
什么是Bloom Filter ?
Bloom Filter是一种space efficient probabilistic data structure,其使用
m bit来记录n个记录。每个记录会用k个hash函数来影射到m bit中的k位上。
通常
k是常值,并且比m小很多,而m的值和要插入元素n有关。一般m增大则false positive rate下降,而n增大,false positive rate上升。
由其结构可知,Bloom Filter可以用来查询记录是否存在。并且不会存在false negative, 但是会有false positive。因此一般Bloom Filter没法删除。
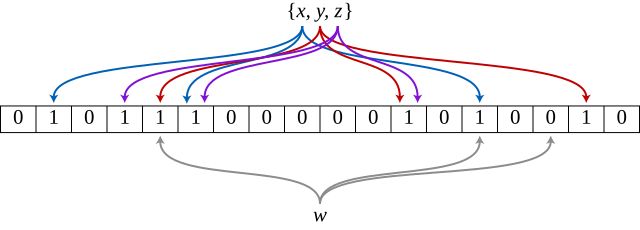
如下图所示Bloom Filter, m = 18, k = 3:
Bloom FIlter 有什么应用 ?
- Cache filter :CDN网络使用Bloom Filter来避免缓存一次点击的数据
- Google Chrome浏览器使用Bloom Filter来过滤有害的URLs. 所有URL首先在一个local Bloom Filter里查询,如果返回positive则进行全面检查。
怎么实现Bloom Filter ?
- 通常Bloom Filter用来查询记录是否存在,因此需要实现操作就包括插入记录和查询记录。我们可以声明如下的BloomFilter类:
#include<vector>
#include "MurmurHash3.h"
#include<array>
template<typename T>
class BloomFilter {
public:
// constructor
BloomFilter(int size, int num);
// insert element
void insert(const T *v, size_t len);
// check whether the bloom filter contains the element
bool exists(const T *v, size_t len) const;
private:
std::vector<bool> bloomFilter;
int numHashes;
// generate the nth hash values
uint64_t nthHash(int n, std::array<uint64_t,2> &hashVals) const;
// generate 128bit hash value using MurmurHash3
std::array<uint64_t,2> hash(const T *data, size_t len) const;
};
- BloomFilter类构造函数, 初始化内部变量:
// constructor
template<typename T>
BloomFilter<T>::BloomFilter(int size, int num) {
numHashes = num;
bloomFilter.resize(size);
}
- BloomFilter类成员函数
insert(T v)
// insert element
template<typename T>
void BloomFilter<T>::insert(const T *v,size_t len) {
std::array<uint64_t,2> hashValues = hash(v,len);
for(int i = 0; i < numHashes; ++i)
bloomFilter[nthHash(i,hashValues)] = true;
}
- BloomFilter类成员函数
exists(T v)
// check if element exists in BloomFilter
template<typename T>
bool BloomFilter<T>::exists(const T *v,size_t len) const {
std::array<uint64_t,2> hashValues = hash(v,len);
for(int i = 0; i < numHashes; ++i) {
if( bloomFilter[static_cast<int>(nthHash(i,hashValues))] == false )
return false;
}
return true;
}
- BloomFilter类私有函数
nthHash()
BloomFilter最重要的是hash函数之间相互独立,实际中我们采用的是double
hash来获得多个相互独立的hash值
// private function : generate nth hash value
template<typename T>
uint64_t BloomFilter<T>::nthHash(int n, std::array<uint64_t,2> &hashValues) const {
return ( hashValues[0] + n * hashValues[1]) % bloomFilter.size();
}
hash函数使用了128bit的MurmurHash3函数:
template<typename T>
std::array<uint64_t,2> BloomFilter<T>::hash(const T *data, size_t len) const {
std::array<uint64_t,2> hashValues;
MurmurHash3_x64_128(data, len, 0, hashValues.data());
return hashValues;
}
测试程序
简单的测试了一下BloomFilter类的实现:
#include <iostream>
#include "BloomFilter.hpp"
using namespace std;
int main() {
vector<string> s = {"hello", "world", "good", "morning"};
int size = 25, num = 3;
BloomFilter<char> bf(size,num);
cout << "Insert : ";
for(auto itr : s) {
cout << itr << "\t";
bf.insert(itr.c_str(),itr.size());
}
cout << endl;
vector<string> test = {"world", "morning", "China", "Red"};
for(auto itr : test) {
cout << itr << " : ";
if( bf.exists(itr.c_str(), itr.size()) )
cout << "maybe exist in BloomFilter";
else
cout << "don't in BloomFilter";
cout << endl;
}
return 0;
}
测试输出:
Insert : hello world good morning
world : maybe exist in BloomFilter
morning : maybe exist in BloomFilter
China : don't in BloomFilter
Red : don't in BloomFilter
参考
1.wikipedia - Bloom Filter
2.how to write a bloom filter
3.MurmurHash3
4.Network Applicatio of Bloom Filter