
文件系统历史回顾
为了能够更好的理解Btrfs 的特性,下面首先回顾以一下Linux 上使用的各个文件系统历史及其特点:
-
1992.04 ext1 是第一个专门为Linux 设计的文件系统, 有Unix File System(UFS)2 类似的metedata , 并且是第一个使用VFS3 。解决了之前Minix 里64M最大容量和14个字符文件名的限制(支持2G容量和255个字符的文件名),但是不支持单独时间戳的文件访问以及数据修改
-
1993.01 ext24 基于Berkely Fast File System 同样的原则开发并取代ext 成为Linux 文件系统。基本单位是Block, 以Inode管理并组成Block Group。 ext2 文件系统结构图如下所示:
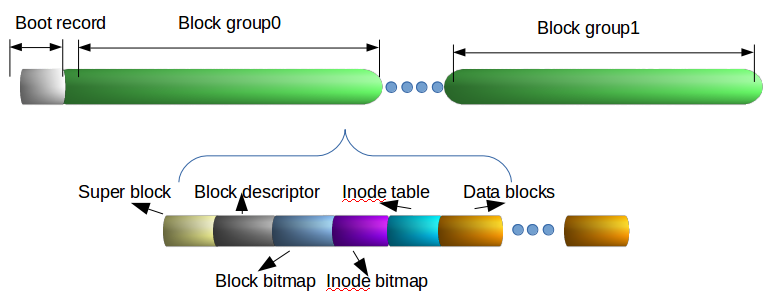
可以看到,ext2 文件系统主要由Boot record 和Block Groups 组成,而后者包含Super block , Block Group Descriptor Table , Block Bitmap, Inode Bitmap, Inode table, Data blocks , 其中:
- Boot record : 主要是系统启动引导纪录,每一个逻辑分区都有,并占据其开始的512B空间
- Super Block : 纪录当前ext2 文件系统的基本信息,包括Block Size, Block Groups个数,每个Block Group的Blocks数量和Blocks 已使用数量等。每个Block Group 前1KB空间用来存储Super Block 信息。(除了Block Group 0必须有Super Block,其他可以不存储。并且Block Group 0总是从逻辑分区的第二个1KB开始)
- Block Group Descriptor Table : 紧随Super Block 之后, 纪录每个Block Group的信息,包括每个Group Block 的第一个Block Bitmap, Inode Bitmap以及Inode Table的地址。其大小由文件系统中Block Groups数量决定, 并且与Super Block 一样,在每个Block Group里都有备份。
-
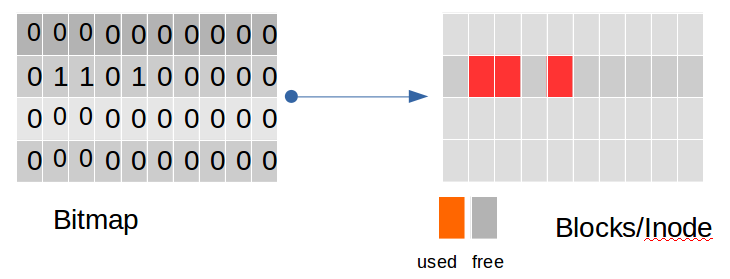
Block Bitmap 和 Inode Bitmap : 两者都是用来bit值来指示其对应的Block或Inode是否使用。其中Block Bitmap大小始终是1个Data Block。可以参见下面示意图:
- Inode Table 和 Inode : 类似于Block Group Descriptor Table, 只是用来管理Block Group内部的Inode和文件目录的查找。实际文件和目录自身读写属性,大小,类型等都保存在Inode里。每个Inode包含12个直接指向的Data Block, 分别1个single indirect Data Block, doubly indirect Data Block和triply indirect Data Block。具体结构可参考下图:
了解上面一些概念之后,可以参考下面示意图来理解ext2 是怎么保存/etc/vim/vimrc:
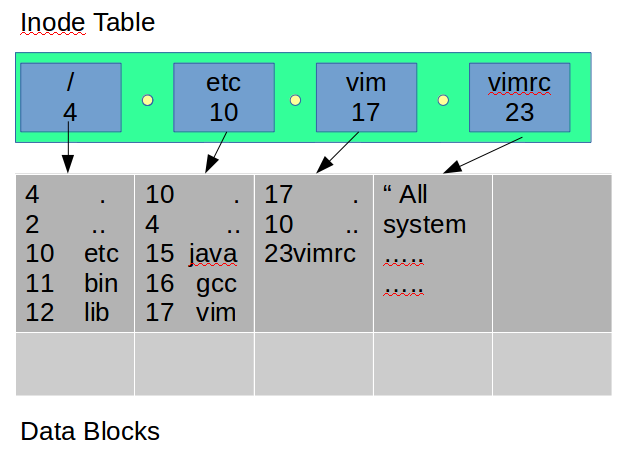
- 2001.12 ext35 取代ext2成为Linux文件系统,兼容ext2。主要是加入日志功能,提高了系统的可靠性,能够支持文件系统在线扩容,对大目录使用HTree进行索引。ext3支持三种日志级别:
- Journal : metadata和数据先纪录在日志之后再写入文件系统。这种风险最低,但是性能会有下降。
- Ordered : 日志里metadata在数据写入文件系统之后会更新。对于写或追加文件过程中发生故障,这种级别可以保证文件系统不会被破坏。但是对于修改文件过程中发生的故障,文件系统会被破坏。
- Writeback : 日志里的metadata不能保证是在数据写入文件系统之后还是之前更新。对于写或追加文件过程中发生的故障,可能日志里已经更新导致数据s被破坏。
ext3在实际中使用不多,主要是由于和ext2兼容,导致性能和特性没有优势,而且由于删除文件时会删掉文件的Inode而不支持undelete,不支持快照和日志没有效验等。
-
2008.10 ext46 加入Linux, 对于ext3上述的一些缺点,ext4 加入了一些新的特性, 比如:Delayed allocation, Journal checksumming, Extents 等, 但仍然与ext2, ext3兼容, 整体结构上也是一致的。对于defragmentation 和performance等相对于其他新的文件系统仍然有差距。
-
2009.03 受ZFS7 启发, Btrfs8 加入Linux, 增强了Snapshots, Checksums等功能。与之前的ext 系列Inode不同的是, Btrfs 采用了Copy-On-Write的B+Tree的结构来索引和存储文件。
以上简单的回顾了Linux上文件系统的历史和结构, 下面重点讲解Btrfs 的一些特性和相应实现结构。
Btrfs 特性
Btrfs 使用的B+Tree 结构
在Implement-B+-Tree-with-C++一文中我详细介绍了标准B+-Tree 的结构及其实现, 可以知道B+-Tree 的leaf node是组成一个链表的, 这种结构不利于COW, 所以Btrfs 相对于标准B+-Tree 去掉了leaf-chaining的结构。Btrfs 使用B+-Tree 结构如下所示:
Btrfs 的整体结构
- 从整体上看,Btrfs 是由一系列的B+-Tree 组成的Forest 构成。类似的,在固定位置有一块Superblock 区域, 指向一个tree of tree root, 然后这个tree of tree root 可以索引组成文件系统的B+-Tree。 Btrfs 整体架构如下:
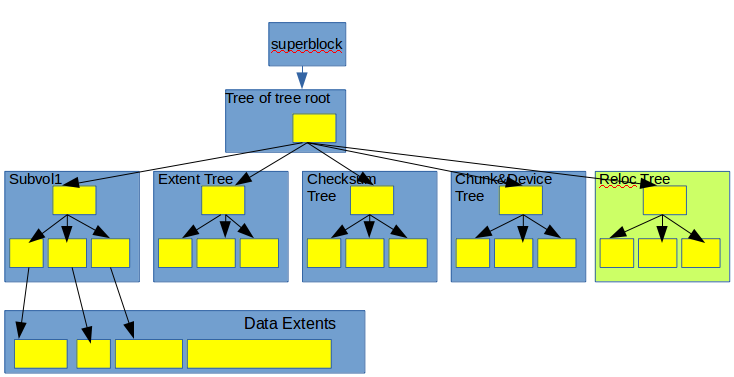
- 由上图可知,Btrfs 整体上是由如下B+-Tree 结构组成:
- Sub-volumes Tree : 是主要用来存储文件和目录的B+-Tree,每一个sub-volume都是一个单独的Sub-Volume Tree, 并且能够快照和克隆,使用ref-counting来记录对同一个Extent的引用。 所有Sub-Volumes Tree的根节点都可以被tree of tree root 索引。
- Extent Allocation Tree : 记录所有的分配的extents和剩余空间。可以用来移动extents或者从损坏德磁盘区域恢复文件系统。
- Checksum Tree : 对于每一个分配的extent 记录一个对应的数据和元数据的Checksum。
- Chunk and Device Tree : 物理设备操作层, 支持RAID。
- Reloc Tree : 移动Extents时特殊操作使用的。 当defragmentation时, Btrfs会克隆Sub-Volume Tree创建Reloc Tree, 然后移动Extent到新的连续的Extent, 最后将Reloc Tree合并到Sub-Volume Tree上。
Btrfs 的读写改操作
- Sub-Volume Tree的inner node存储了
[key, block-pointer]对, 而leaf node则存储了[item,data]对。 由于data的size是变化的,所以每一个leaf node在一个block的前段存储item,然后从block后端开始存储data。每个leaf node存储结构如下:
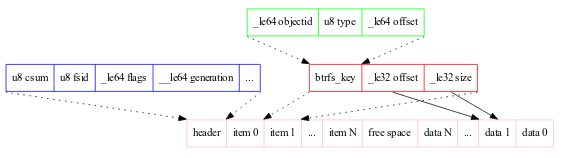
- Btrfs读操作很简单就是对Sub-Volume Tree作简单的B+-Tree查找操作。
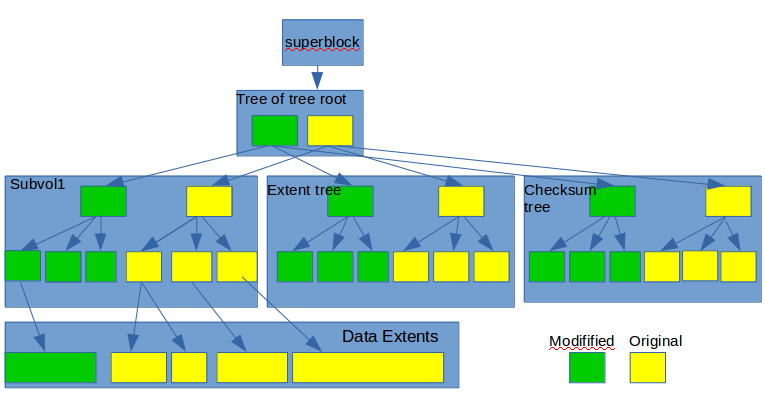
- 当修改文件或目录时会导致extent的更新, 然后由于使用 Copy-On-Write , 更新会一直传导到Sub-Volume Tree的根节点。 同时也会导致Extent Allocation Tree需要更新。而数据和元数据变化也会导致Checksum Tree需要同样更新操作。所有这些更新最后在root层就是产生一个新的tree of tree root。 *Btrfs一个更新操作可以参考下图:
参考
以下是一些参考信息: