What’s Raft ?
与之前介绍过的Paxos一样, Raft也是用来解决分布系统中concensus问题的协议。 我们知道, 在Paxos中,任何节点都同时是Proposer和Acceptor, 而在Raft中,同一时间,最多只能有一个Leader, 其他节点只能是Follower, 和Multi-Paxos有一点类似。
Role in Raft
在Raft中, 只存在下面三种节点:
- Leader : 负责和Client通信,并管理Follower, 同一时间最多只能有一个
- Follower : 除了Leader之外其他节点, 当hearbeat为零时转化为Candidate
- Candidate : 中间状态,在Follower选举Leader期间存在
三者之间的转换关系如下图所示:
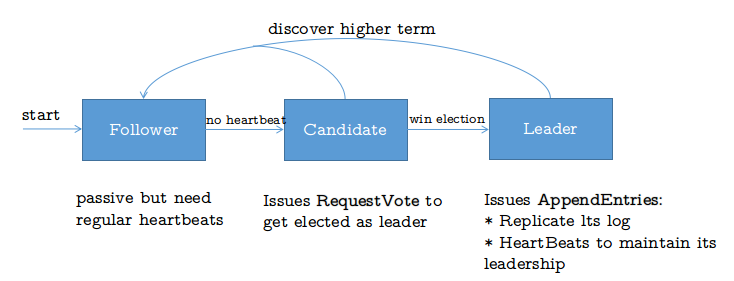
其中每个节点都有一个递减的HeartBeat值,和一个递增的currentTerm。 当一个Follower节点的HeartBeat为零时,其转化为Candidate,同时增加currentTerm,向其他节点发送RequestVote(当前节点选自己),当Candidate收到大多数节点,即[n/2]+1节点的选举时转化为Leader。因此正常工作时leader需要在一定时间之内给Follower重置HeartBeat。
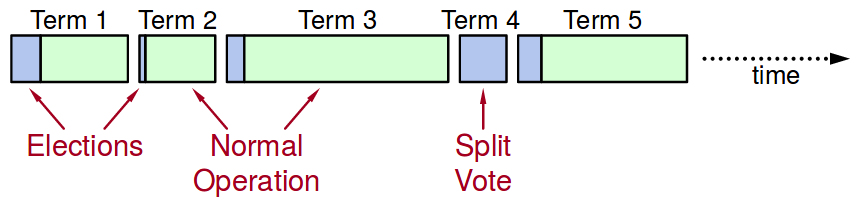
上述说明中的同一时间具体的说是同一个term, 更具体的可以用下图表示:
Normal Operation
了解了Raft中的角色之后, 可以理解下面Raft里正常的运行流程了:
- Client发送命令
command到Leader - Leader将命令
command记录到自己的log里 - Leader发送
AppendEntriesRPC给Follower, 要求记录command - Leader执行
command并返回结果给Client, 同时发送AppendEntries要求Follower执行command - 如果上述过程中有Follower 非正常工作, Leader持续发送
AppendEntries直到成功
Leader Election
和Paxos利用Poposal Number来选举一个Propoer不一样, 在Raft中, Leader 选举过程如下:
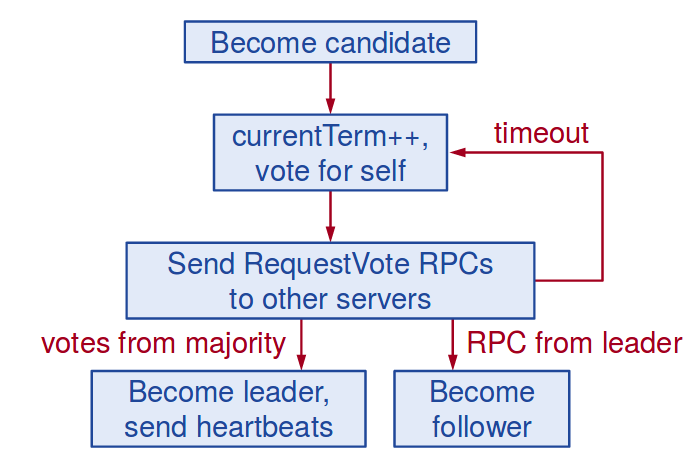
- 初始状态,所有节点都是Follower
- Follower的heartbeat 归零,转化为Candidate
- 当前节点
currentTerm++,同时发出RequestVoteRPC给其他节点 - 其他节点比较收到的
RequestVote的term和自己的currentTerm,如果term比自己currentTerm小则不同意当前Candidate发出的RequestVote - 否则如果发出
RequestVote的Candidate的log不比自己log旧则同意candidate的选举 - 得到大多数节点选举的Candidate转化为Leader, 同时发送空的
AppendEntries来重置其他节点,使其成为Follower
Log Replication
上面提到Leader会发送AppendEntries来要求Follower同步操作,另外, Leader在选举成功之后,也会记录每个节点的log的:
nextIndex: 下一个记录在log里的index, Leader会将其初始化为其当前log index + 1matchIndex: 记录由当前Leader复制的记录的最高的index, 初始化为零
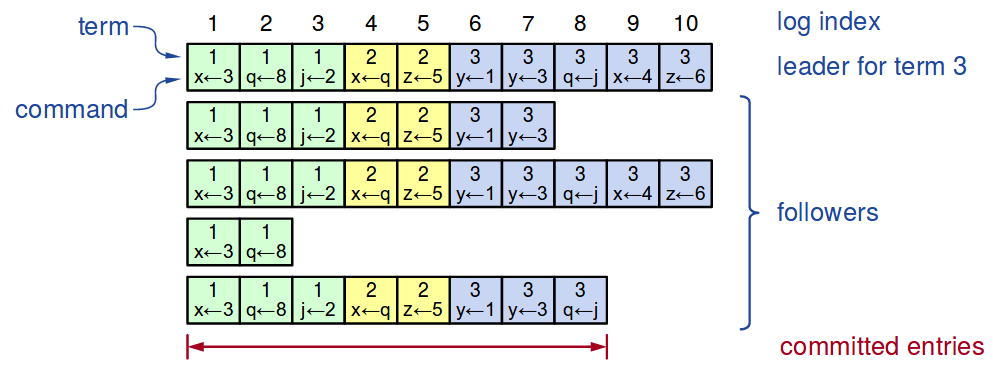
term, log index和Leader, Follower的关系参见下图所示: