
概述
华为从2019年发布昇腾910(Ascend 910)到今年的CloudMatrix计算系统,在6年时间里完成了从芯片到系统的整合;从910不够成熟的互联方案到910C 完整的芯片和网络互连解决方案 ,在有限的资源和限制下对业务的需求的取舍,值得深入的探讨。同时,由于各种原因,关于910从芯片到系统,仿佛有一层薄雾,各类信息参差不齐,让人很难一睹全貌。本文基于网络上已有的资料,试图从芯片架构,计算结构,存储层次,互联方案等各方面揭露910的神秘面纱。
下表是910到910C的一些基本指标信息:
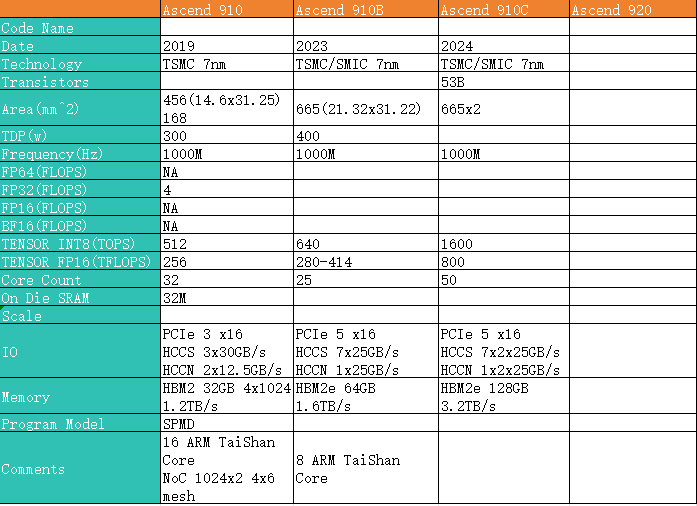 可以看到,不同产品之间很明显的继承和演变脉络:
可以看到,不同产品之间很明显的继承和演变脉络:
- 910可以看成是AI计算和应用还方兴未艾时的试水,所以从当前LLM的需求,910在计算尺寸,互联等方面存在较为明显的缺陷
- 910B则是在各种限制约束下,基于910展现出来的缺点进行了增加,同时减少迭代时间,快速推出产品,小步快跑
Ascend 910
昇腾910(Ascend 910) 是华为2019年发布产品,计算部分采用达芬奇架构。
Ascend 910 SoC架构
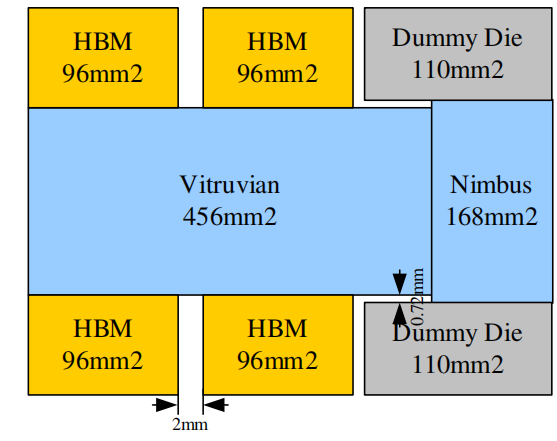
昇腾910采用chiplet方案,一共8个die,4个HBM,2个dummy die,1个soc die,一个NIMBUS die;其中两个dummy die用来保持芯片整体机械应力平衡; 四个HBM总带宽为 1.2TB/s;昇腾910整体布局如下图所示:
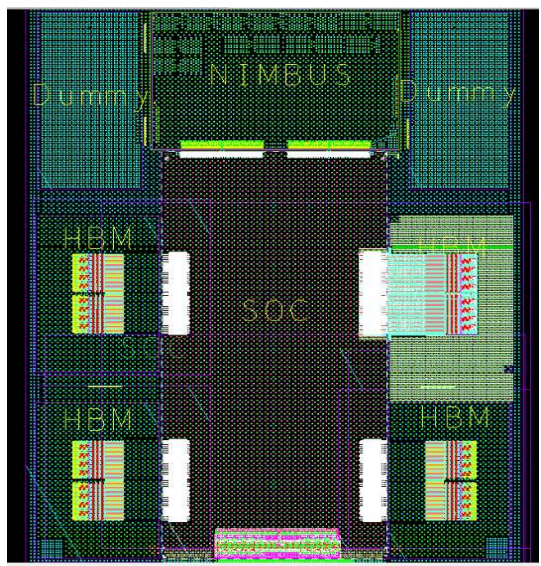 不同die的面积如下所示:
不同die的面积如下所示:
 Ascend 910 SoC 包含
Ascend 910 SoC 包含
- 5个D2D
- 4个cluster,一共32 个 Ascend-Max Core
- 16个 Arm V8 TaiShan CPU 内核和 8M CPU L3
- 32MB on chip buffer
- 4个HBM2 , 32GB, 1.2TB/s
- PCIe 3 x16 RC/EP
- 3x30GB/s HCCS
- 2x12.5GB/s HCCN
- 视频编解码器(Digital Vision Pre-Processor),支持128路的全高清视频解码
- 片上网络 (NoC)。NoC采用4x6的mesh拓扑,以提供统一且可扩展的通信网络;两个相邻节点之间的链路工作频率为 2GHz,数据位宽为 1024 位,可以提供256GB/S 的带宽
SoC die和Nimbus die架构框图如下所示:
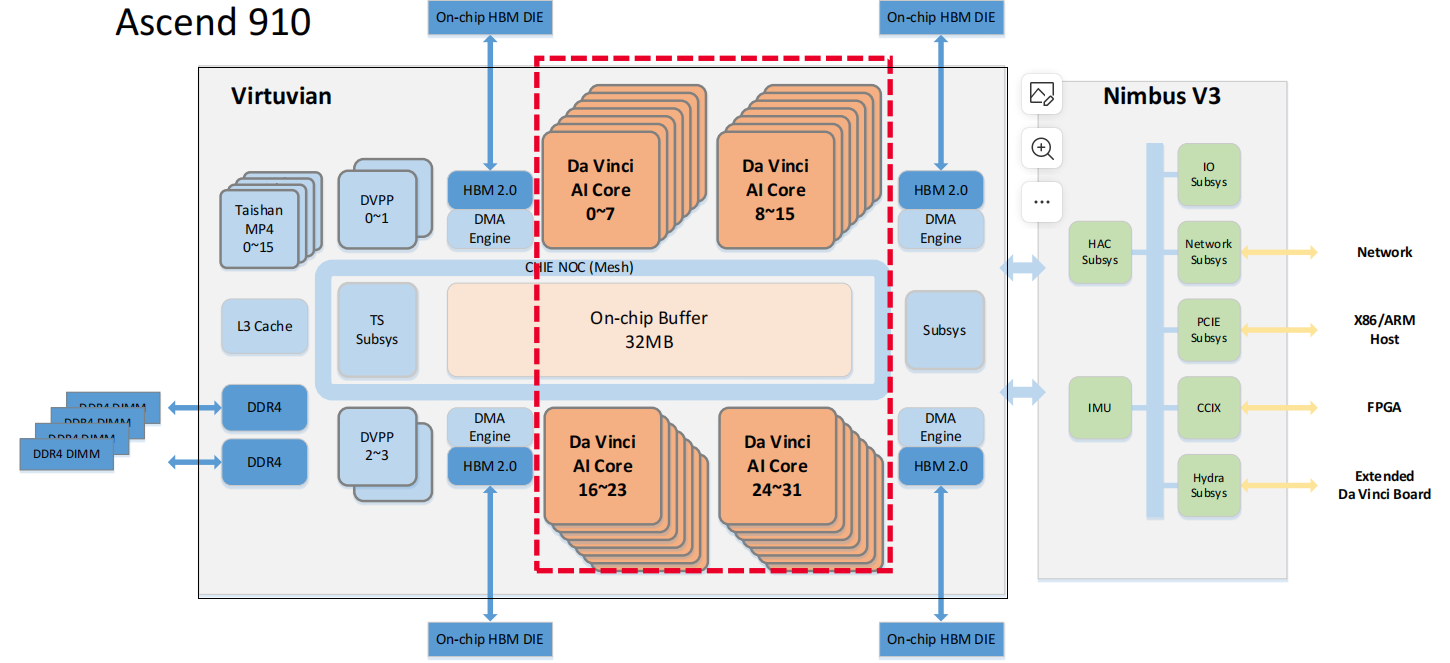
其中soc die主要用来计算,采用台积电7nm工艺,面积456mm^2,可以提供512TOPS的INT8性能;soc die的物理规划如下所示:
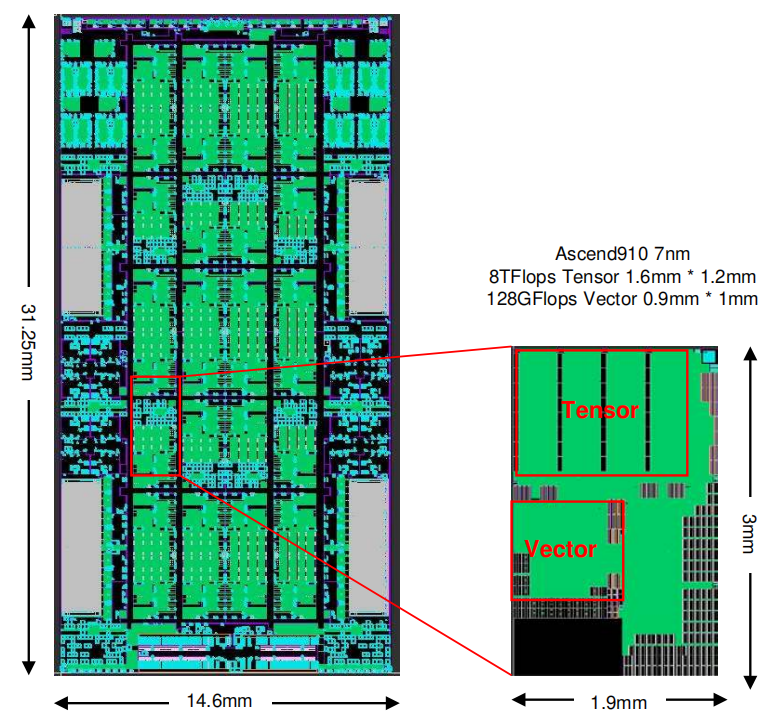
Ascend 910 计算架构
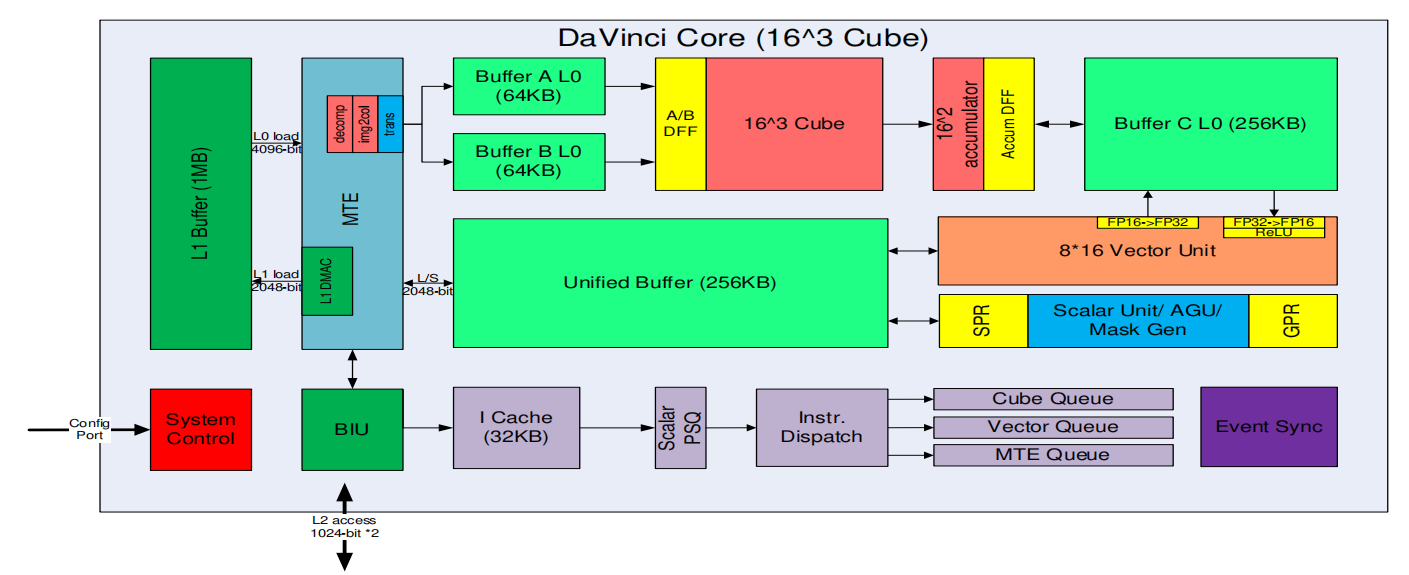
Ascend 910计算核是DaVinci架构,称为Ascend -Max,包括:
- 标量计算单元主要负责地址等标量计算
- 向量计算单元可以进行归一化,激活等计算;向量单元还负责数据精度转换,例如 int32、fp16 和 int8 之间的量化和解量化操作;向量单元还可以实现 fp32 操作
- 张量计算单元主要是矩阵计算,包括卷积,全连接,矩阵乘等;张量计算中矩阵的典型尺寸为 16 x 16 x 16。因此,张量计算单元配备了 4096 个乘法器和 4096 个累加器。
DaVinci架构框图如下所示:
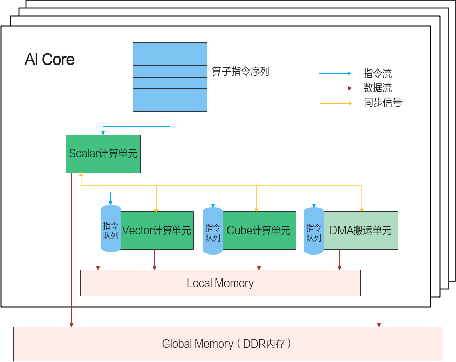
DaVinci核内部的异步并行计算过程
- Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步并行执行接收到的指令。
- 不同的指令间有可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令。
Ascend 910 存储结构
DaVinci核存储层次包括核内的L0,L1 缓冲区构成的本地存储(Local Memory),以及外部HBM/LPDDR构成的全局存储区(Global Memory):
- DaVinci核包括多个缓冲区,分成不同层次。
- L0 缓冲区专用于张量计算单元,分成三个单独的 L0 缓冲区,分别是缓冲区 A L0、缓冲区 B L0 和缓冲区 C L0。
- 分别用于保存输入特征数据、权重和输出特征数据。
- 缓冲区 A L0 和缓冲区 B L0 中的数据从 L1 缓冲区加载。
- L0 缓冲区和 L1 缓冲区之间的通信由内存传输引擎MTE(Memory Transfer Engine) 管理。
- L0 缓冲区专用于张量计算单元,分成三个单独的 L0 缓冲区,分别是缓冲区 A L0、缓冲区 B L0 和缓冲区 C L0。
- DaVinci核外面有一个Gobal Memory,是多个DaVinci核共享的
DaVinci核心组件有三个计算单元,标量计算单元、向量计算单元,矩阵计算单元。另外还有一个DMA搬运单元,DMA搬运单元负责在Global Memory和Local Memory之间搬运数据;DaVinci核数据处理的基本过程:
- DMA把数据搬运到Local Memory,Vector/Cube计算单元完成数据计算,并把计算结果写回Local Memory
- DMA把处理好的数据搬运回Global Memory
Ascend 910的存储结构和数据流结构如下所示:
Ascend 910 互联架构
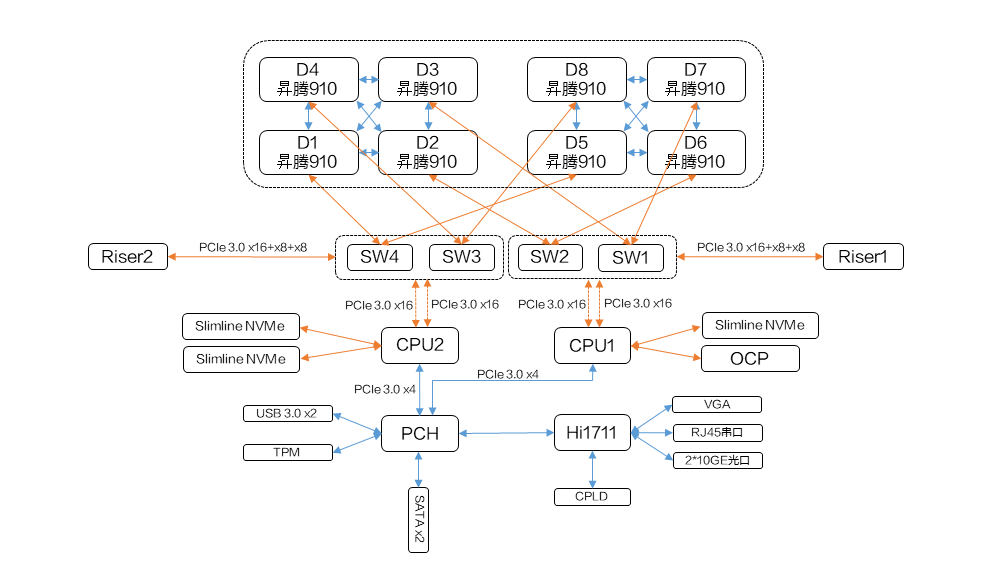
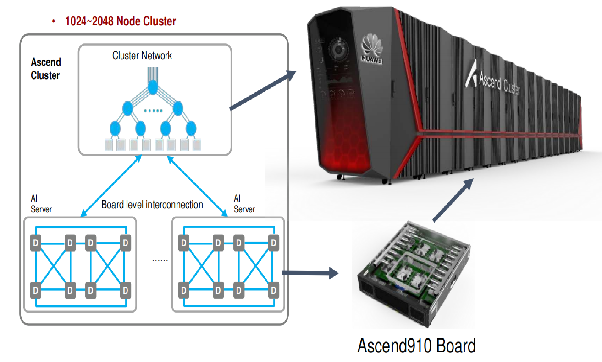
每台昇腾910服务器包含
- 8个昇腾910芯片,并分为两组;
- 组内连接基于高速缓存一致性网络HCCS (high-speed cache coherence network),提供30GB/S带宽 。
- 两个组使用 PCI-E 总线相互通信,提供32GB/S带宽。
- 整体形成hyper cube mesh网络拓扑。
多台昇腾910服务器可以通过fat-tree的网络拓扑组织成一个集群。下图展示了一个 2048 节点的集群,可以提供512 Peta FLOPS的 fp16 总计算能力,包含 256 台服务器,服务器之间的链路带宽为 100Gbps。
Ascend 910 编程模型
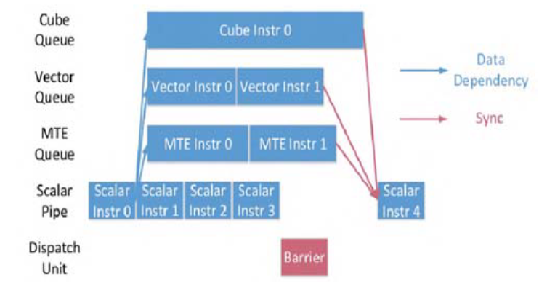
DaVinci核三个计算单元和 MTE 并行工作,因此需要显式同步来确保不同执行单元之间的数据依赖关系。下图展示了相应流程:
- PSQ 不断向不同的单元发送指令,这些指令可以并行处理,直到遇到显式同步信号(屏障);
- 屏障由编译器或程序员生成。
 Ascend 910主要采用SPMD(Single-Program Multiple-Data)编程方式利用数据并行:
Ascend 910主要采用SPMD(Single-Program Multiple-Data)编程方式利用数据并行: - 将数据分片,每片数据经过完整的一个数据处理流程。
- 每份数据的处理运行在一个核上,这样每份数据并行处理完成,整个数据也就处理完了。
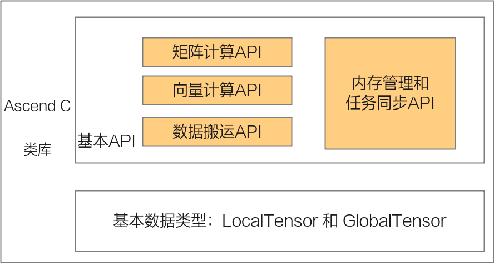
Ascend C是SPMD(Single-Program Multiple-Data)编程语言,多个DaVinci核共享相同的指令代码,每个核上的运行实例唯一的区别是就是block_idx(内置变量)不同,可以通过block_idx来区分不同的核,只要对Global Memory上的数据地址进行切分偏移,就可以让每个核处理自己对应的那部分数据了。算子被调用时,所有的计算核心都执行相同的实现代码,入口函数的入参也是相同的。每个核上处理的数据地址需要在起始地址上增加block_idx*BLOCK_LENGTH(每个block处理的数据长度)的偏移来获取。这样也就实现了多核并行计算的数据切分。Ascend C主要提供的API接口如下:
Ascend 910B
昇腾910B(Ascend 910B) 是华为2023年发布产品,计算部分采用达芬奇架构。在910的基础上主要是提高了互联能力,主要功能模块包括:
- 25 个 Ascend Core
- 提供280-414 FP16算力,主要是生产工艺和产品筛片划分产品规格非常多
- 6 个 D2D,带宽数据存疑,不过考虑通过基板互联,带宽可能在TB/s以下
- 8 个 Arm V8 TaiShan CPU 内核和 8M CPU L3
- 256MB LLC
- 4个HBM2e, 64GB, 1.6TB/s
- 1个PCIE Gen5 x16
- 7个4x56G HCCS
- 1个4x56G HCCN
- 支持Dragonfly组网
- 视频编解码器(Digital Vision Pre-Processor),支持128路的全高清视频解码?这个存疑
- 一个片上网络 (NoC)。NoC采用4x6的mesh拓扑,以提供统一且可扩展的通信网络;两个相邻节点之间的链路工作频率为 2GHz,数据位宽为 1024 位,可以提供256GB/S 的带宽 ?这个也存疑
910B和910的物理版图如下:
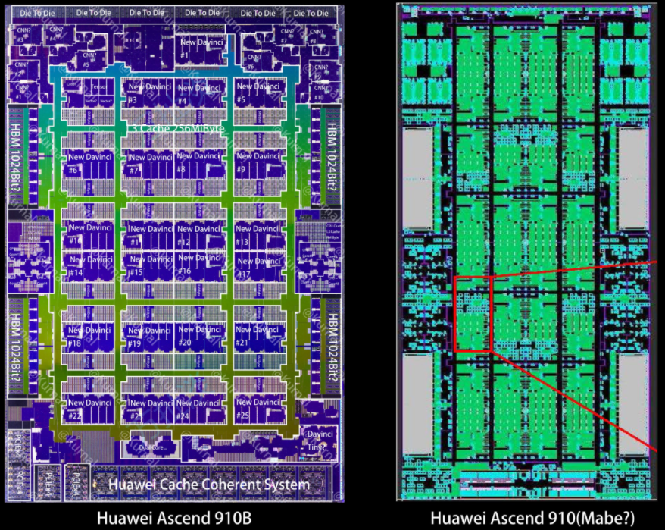
主要变化是去掉了910上的Nimbus die, 提高了HCCS的数量和带宽,Ascend Core的Cube计算尺寸可能也有增加。两个910B上的HBM是组成NUMA还是UMA不太确定,不过考虑到D2D的性能,可能NUMA比较合适。
Ascend 910C
昇腾910C(Ascend 910C) 是华为2024年发布产品,主要是2片910B通过D2D在基板互联组成MCM,如下图所示:
 因此,Ascend 910C主要包含:
因此,Ascend 910C主要包含:
- 2个 910B, 通过基板互联
- HBM 8个,128GB, 3.2TB/s
- 提供800T FP16算力
- 7x2x25GB/s HCCS
- 1x2x25GB/s HCCN
910C主要采用交换机组网进行互联扩展,简单猜测,如果要用满HCCS互联带宽,应该需要两个910B上的计算核同时往自己本地的HCCS进行数据传输,也就是HCCS也是NUMA结构,在外面把两个200G的HCCS合并成一个400G的,然后接到一个400G的光模块上。
后续的主要信息来源于Semianalysis, 不做过多解读。
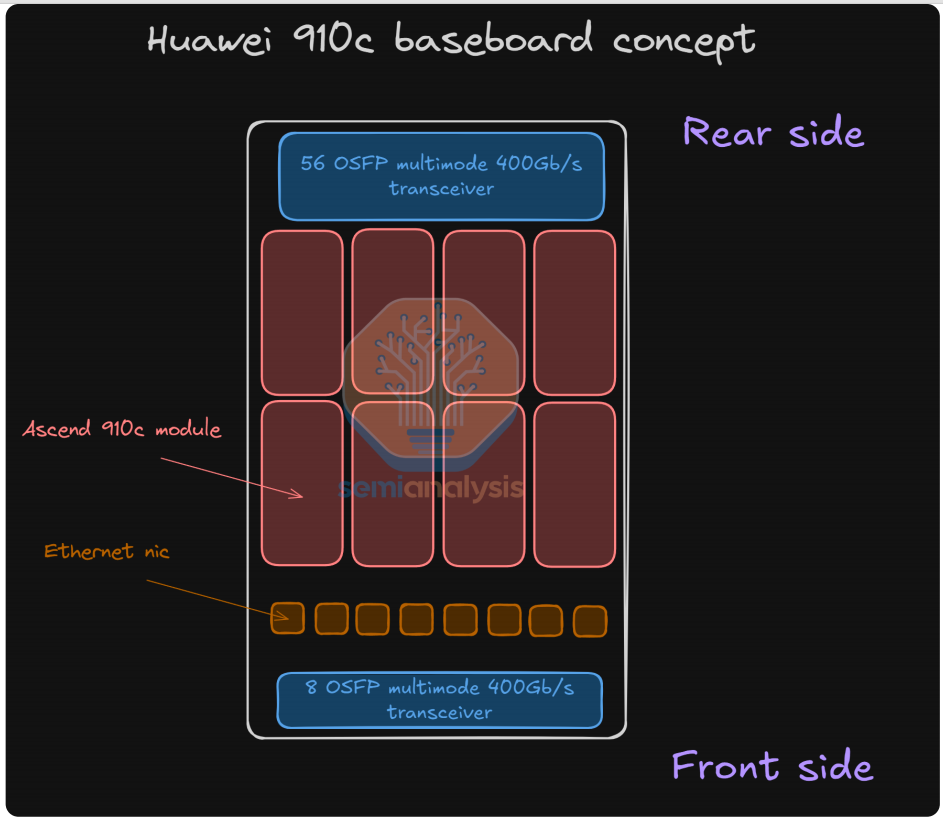
Semianalysis预测910C的8卡基板设计如下:
- 8个 910C
- 56个Scaleup光模块
- 8个Scaleout光模块
- 支持交换机Scaleup
Ascend 910C 互联架构
Ascend 910C一个互联节点称为CloudMatrix ,包含:
- 384个 910C
- 12个计算服务器机柜
- 4个网络交换机柜
- 6912个光模块=384x7x2 + 384x1x2,采用LPO,相比DSP的光模块减少功耗
384个 910C通过交换机组成全互联拓扑,每个910C的互联带宽是7x56GB/s。CloudMatrix如下所示:

下表是Semianalysis统计的CloundMatrix 384和NVIDIA NVL72的规格对比
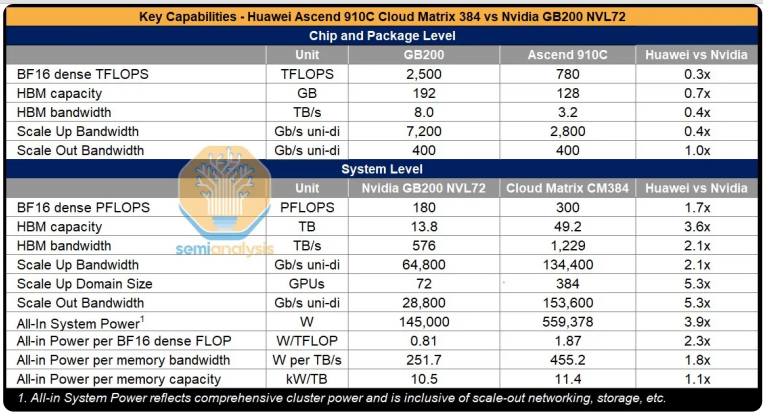 CloudMatrix能够提供300 PFLOPs BF16计算性能, 是NVL72的1.7倍,3.6倍的存储容量和2.1倍的存储带宽;代价是3.9的功耗。总结下来,CloudMatrix 每FLOP的功耗是NVL72的2.3倍;每TB/s的存储带宽的功耗是NVL72的1.8倍;每TB的存储容量的功耗是NVL72的1.1倍。
CloudMatrix能够提供300 PFLOPs BF16计算性能, 是NVL72的1.7倍,3.6倍的存储容量和2.1倍的存储带宽;代价是3.9的功耗。总结下来,CloudMatrix 每FLOP的功耗是NVL72的2.3倍;每TB/s的存储带宽的功耗是NVL72的1.8倍;每TB的存储容量的功耗是NVL72的1.1倍。
每个计算机柜有32个910C,12个计算机柜,一共12x32=384个910C。
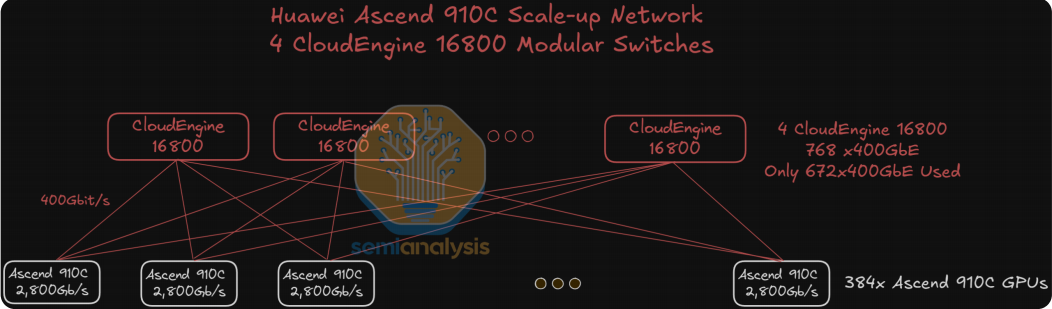
 中间4个交换机机柜是CloudEngine 16800, 每个交换机有768个400G的接口,910C需要的400G接口数量384x7=2688个,这样每个CloudEngine需要使用的接口数量2688/4=672个,如下所示:
中间4个交换机机柜是CloudEngine 16800, 每个交换机有768个400G的接口,910C需要的400G接口数量384x7=2688个,这样每个CloudEngine需要使用的接口数量2688/4=672个,如下所示:
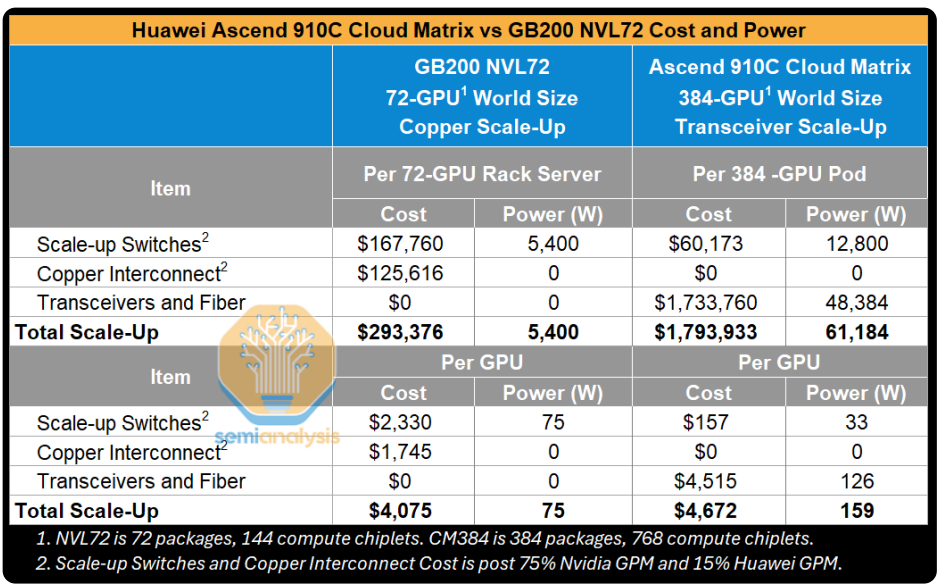
下表是根据上面的拓扑估算的成本对比:
CloudMatrix 384 Scale Out Topology
Semianalysis预估了CloudMatrix做Scale out的拓扑方案,如下所示:
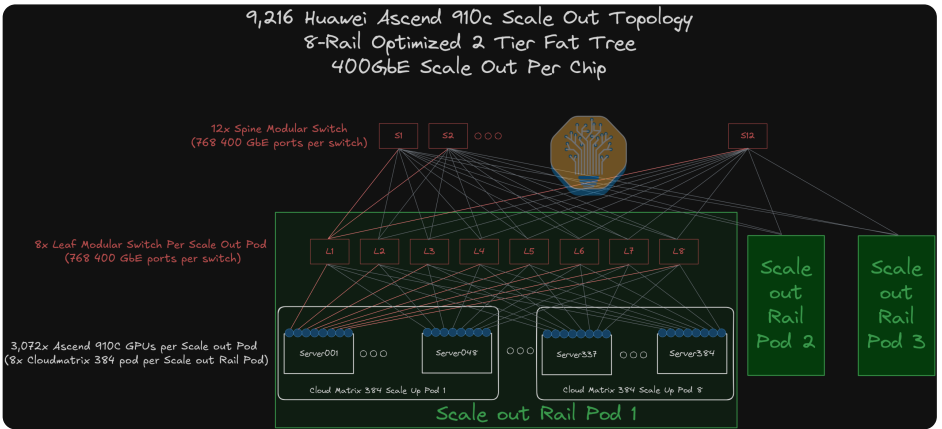 CloudMatrix 384采用two-tier 8-rail 的互联拓扑,因此需要8个leaf交换机,每个交换机需要384x2个400G,一边和910C连接,一边和Spine交换机连接;每个Pod有8个CloudMatrix 384, 一共384x8=3072个910C,因此需要3072个400G光模块;3个Pod互联需要384x8x3=9216个400G,所以需要9216/768=12个Spine交换机。
CloudMatrix 384采用two-tier 8-rail 的互联拓扑,因此需要8个leaf交换机,每个交换机需要384x2个400G,一边和910C连接,一边和Spine交换机连接;每个Pod有8个CloudMatrix 384, 一共384x8=3072个910C,因此需要3072个400G光模块;3个Pod互联需要384x8x3=9216个400G,所以需要9216/768=12个Spine交换机。