
什么是 HDFS ?
HDFS 与之前介绍的Btrfs不同,HDFS 是针对 Hadoop 框架适用于廉价计算机并具有容错功能的分布式文件系统。主要用来存储大文件,能够提供很高的吞吐量,但是不适合對时延要求高的场景。另外,为了保持一致性, HDFS 只支持
write-once-read-many, 文件一旦创建,操作结束之后, 只能对文件进行追加和截取操作。与 Btrfs 等本地文件系统一样的是,HDFS 也使用block来保存文件,而且针对不同文件可以配置不同的block size, 默认大小是128M。同时同时保存同一个文件的多个备份,默认是3个, 一个保存在当前节点,一个保存在当前机架另一个节点,另外就是其他机架的节点。
HDFS 基本结构
HDFS 在结构上是由一个 NameNode 和 多个 DataNode 组成, 其中NameNode
和 DataNode之间使用TCP/IP Socket进行通信, 而使用 RCP和客户端通信。
下图是基本的 HDFS 结构 :
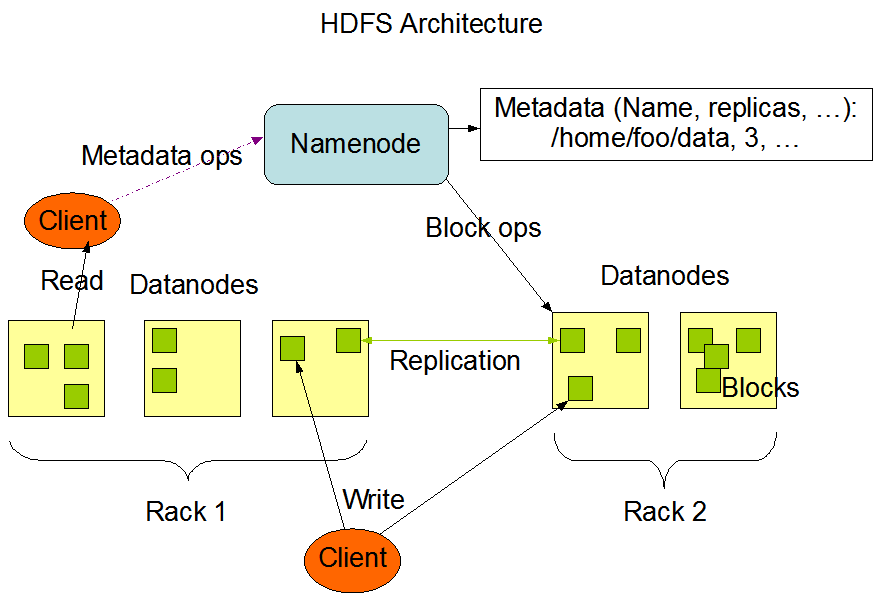
NameNode 功能
从结构上, HDFS 是Master/Slave架构,
而其中NameNode就充当Master,来管理文件空间,以及管理客户端对文件系统的访问。NameNode提供基本的文件操作如文件创建,删除,复制等操作,并且提供文件访问和权限功能,但是不支持链接。
所有对文件系统的操作都会在NameNode里记录, 在NameNode里,有一个EditLog,会记录对文件系统的所有的操作,不管是创建一个新文件,还是改变文件保存的复制数,HDFS 将该文件保存在NameNode所在的主机的本地文件系统里。另外,关于 HDFS 的一些基本信息,包括文件保存的blocks,文件系统配置会被保存在本地文件系统的Fsimage文件中。
一般的,HDFS 会在内存中存储一份Fsimage和EditLog,当 NameNode 启动或者触发 checkpoint 时,HDFS 会读取磁盘中的 Fsimage和EditLog,并且应用EditLog中的操作,同时更新磁盘中的Fsimage和EditLog。
由于Fsimage和EditLog对于 HDFS 的重要性,HDFS
能够配置为保存多份Fsimage和EditLog,任何操作都会同时更新所有的备份。
每个DataNode都会周期的发送HeartBeat给NameNode,
如果由于网络等其他因素导致DataNode无法访问,NameNode能够根据HeartBeat的停止而发现这种问题,从而将最近没有HeartBeat的DataNode标记为Dead同时不再发送数据请求。NameNode同时还要对由于DataNode缺失而导致复制数少于配置要求的重新进行复制。
DataNode 功能
DataNode
负责保存在本地文件系统来具体的文件,并负责具体的文件创建,删除等操作。每个文件保存在一系列的block里,并复制备份到其他节点,block
size和复制数可以针对每一个文件进行配置。每一个DataNode都要定期发送HeartBeat给NameNode来表示可以正常工作。