
什么是 leveldb ?
leveldb 是由 google 的jeff dean 开发的in-memory 的key-value 数据库, 提供了基本的
Put,Get,Delete操作。
leveldb 基本结构
leveldb 的基本结构如下所示:
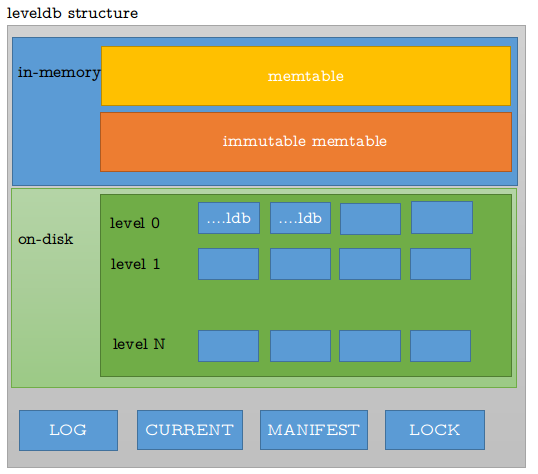
由上图可以知道:
- memtable 和 immutable memtable :这两个是 leveldb 用来在 memory 里存储数据的结构。leveldb 首先在 memtable里存储数据, 当
memtable使用memory 的大小超过options_.write_buffer_size时,将其作为immutable memtable 并写入disk, 然后释放immutable memtable。 - LOG : 记录 leveldb 运行中进行的操作,可以用来分析数据库状态
- LOCK: 当
Recover或者DestroyDB时用来锁定文件 - MANIFEST- : 记录了当前 leveldb 的一些属性, 格式与下面介绍的
log一致 - CURRENT : 记录了当前
MANIFEST-*文件的FileNumber, 可以用来查找当前MANIFEST-*文件 *.log文件, 记录当前memtable里的数据*.ldb文件, 记录 leveldb 存储的key-value, 文件分多层来组织, 由kNumLevels来控制, 默认7
了解 leveldb 基本操作之前, 下面先介绍其使用的数据结构
memtable
memtable 是用来在 in-memory 中存储key-value 的数据结构, 其实质是 skiplist 。存储的数据的结构如下所示:
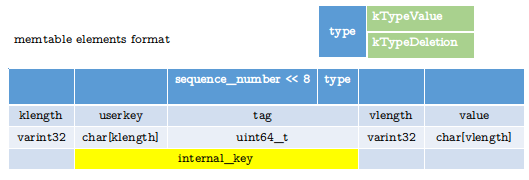
由上图可知:
userkey和tag组成了internal_key- 其中 8 byte 的
tag是由 7 byte 的sequence_number和 1 byte 的type组合而成的 sequence_number是一个递增的无符号数据, 每次对 leveldb 的Put,Get,Delete操作都会使其加一type可取的值分别是:kTypeValue表示当前数据有效,kTypeDeletion表示当前数据已删除。 需要注意的是, 当使用Delete操作时, memtable 实际只是插入一个type为kTypeDeletion的空值。
skiplist 内部数据是有序的, 也就是我们存储在 memtable 里的数据会根据userkey 和 sequence_number来排序, 基本原则是先比较userkey,之后再根据sequence_number大的在前。
write batch 格式
WriteBatch可以用来保证一系列操作的完整性,里面的操作要么都成功, 要么都失败。当调用Put或Delete时, leveldb 上会将其操作放到 WriteBatch对象中。另外 leveldb 在实际执行WriteBatch里操作之前,会尝试将几个WriteBatch合并一起,可以减少write lock的消耗。WriteBatch里的数据格式如下图所示:

当合并几个WriteBatch时,取其中最大的SequenceNumber作为新的SequenceNumber。
log 格式
为了保证数据安全, 在每一个WriteBatch里操作在memtable里执行之前, 会将WriteBatch里的数据写入到log文件里保存。当memtable写入到sstable文件里时,log文件会打开一个新的文件。log文件保存数据格式如下图所示:
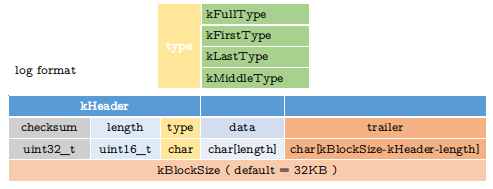
由上图可知,log文件是以kBlockSize来存储数据, 其中一个kBlockSize多个kHeader和data, 只有一个kBlockSize剩下不到kHeader的空间才会填充trailer(ox00)。存储的data就是上面介绍的WriteBatch的数据。其中type可能值是:
kFullType: 表示data全部存储在当前kBlockSize内kFirstType: 表示当前kBlockSize存储的是data的第一部分kMiddleType:表示当前kBlockSize存储的是data的中间部分kLastType:表示当前kBlockSize存储的是data的最后一部分
sstable 格式
当memtable占用内存空间大小超过options_.write_buffer_size( default = 4MB)时, leveldb 会将memtable写到sstable文件中。sstable文件存储的基本格式如下图所示:
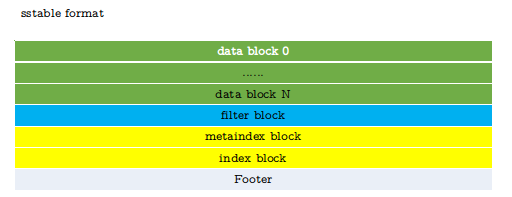
由上图可知, sstable文件中是以options_.block_size(default = 4KB)来组织数据的, 首先存储数据库数据。 如果有使用FilterPolicy, 接下来就存储FilterPolicy的数据。然后接下来存储数据库的信息,接下来就是用来索引data block的index block。文件最后会存储footer。上述各自具体格式下面会详细介绍。
block 格式
上面不管是data block, index block还是 metaindex block, 其基本结构都如下图所示:

其中,
crc是对block中除crc之外数据的校验type表示数据是否压缩num_restarts表示restarts数组的个数,restarts数组记录的是对应的使用共享编码的key-value的偏移shared_bytes表示当前key相同的部分大小,unshared_bytes是key里差异的大小,value_length是value的长度,key_delta是差异的key值,value就是实际的值
对于index block和metaindex block来说, num_restart_interval都是1也就是说所有shared_bytes = 0, 而对于data block来说, 是受options_.num_restart_interval控制的, 默认是16, 也就是16个key-value会进行共享编码。
footer 格式
footer保存在sstable文件最后,其保存数据及其格式如下图所示:

其中分别保存了metaindex_handle和index_handle对象, 可以通过这两个对象来访问sstable里metaindex block和index block。
metaindex block 格式
metaindex block当前只保存了filter name及filter_block_handle, 具体格式参见下图:
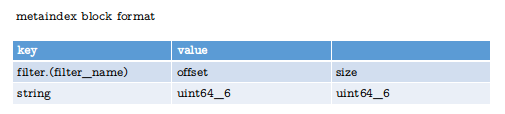
通过filter_block_handle可以访问sstable里的filter block。
index block 格式
index block是用来索引sstable里的data block, 具体格式如下:
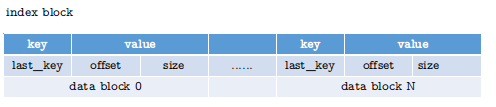
其中
last_key是其所对应的data block所保存的数据中最后一个key-value的key值, 由于memtable里值是有序的, 所以last key也是有序的offset和size则分别是对应的data block在sstable的偏移值和大小。
filter block 格式
filter block和data block不一样,不是利用block的结构来存储数据的, 而是使用下面的格式:

其中
crc是整个filter block除了crc部分的校验type, 表示是否压缩,存储的是nocompressedkFilterBaseLog, 表示是对多大数据创建filter, 默认是2KB (2^kFilterBaseLg)array_offset, 表示offset数组在filter block里的偏移offset[N]和filter[N],offset数组分别记录的是对应filter数组在filter block的偏移