Puspose of the Paper
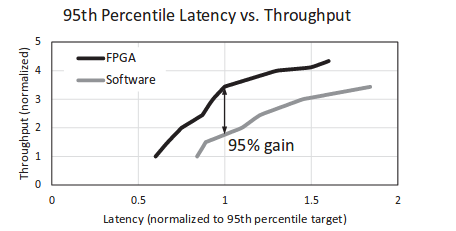
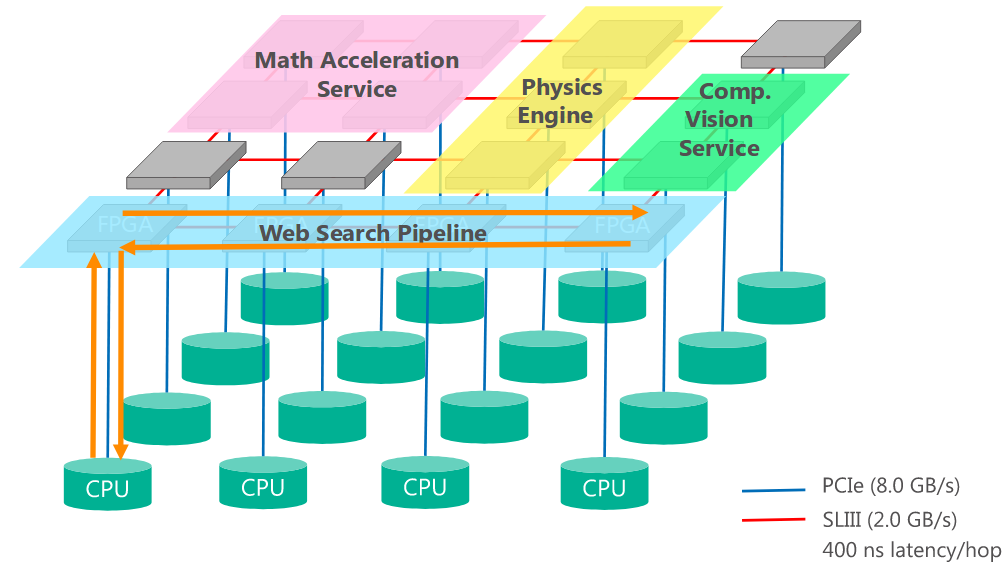
由于现在数据中心负载越来越大, 同时CPU随着摩尔定律和散热问题导致性能无法继续提升。为了解决这个问题, 这篇论文提出研究了使用FPGA来对服务进行加速的方案。 论文中介绍的方案是使用6x8个高端Stratix FPGA组成的二维网络放置于48个机器的机架中。每一个FPGA和对应的服务器通过PCIe来通信,并可以通过10Gb SAS线直接和其他FPGA通信。使用Bing Web Search来对系统进行测试,发现在高负载情况下,该系统在固定的延时分布下可以提高服务器95%的吞吐,或者在保持相等吞吐情况下减少29%的延时。
整个系统架构如下图所示:
Method used in the Paper
FPGA子板设计
为了减少对原始服务器系统主版的改动,该论文提出使用PCIe来作为主CPU和FPGA系统之间通信,同时使用8GB DRAM来作为FPGA的存贮器。FPGA子板和主板位置如下图所示:
FPGA逻辑设计
FPGA和CPU接口设计
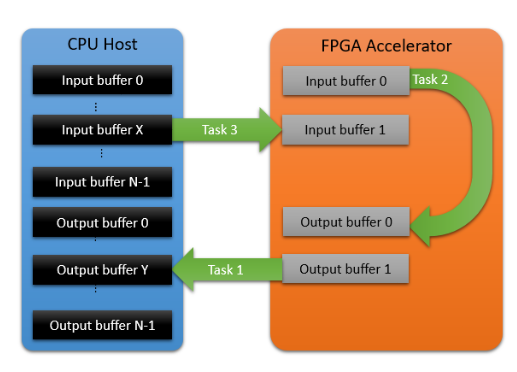
该论文提出为了保证CPU与FPGA之间传输16KB数据时延在10us以内,同时能够支持多线程,专门设计了DMA支持的PCIe接口程序,其中:
-
CPU侧设计了64个input/output buffer对, 每个线程只能访问指定buffer, 实现线程安全
-
FPGA侧则实现了2个input/output buffer对,可以同时执行3个任务
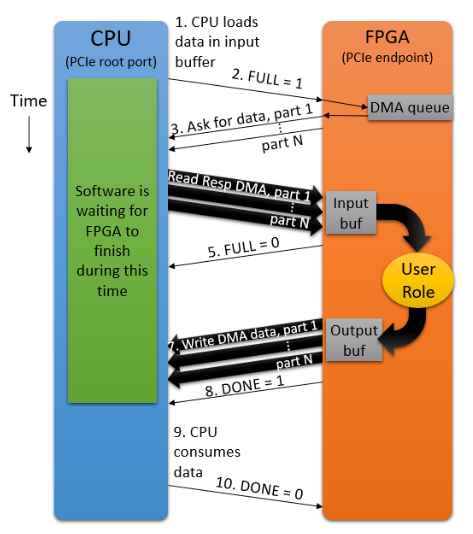
其接口实现可以参考下图:
而其传输流程则如下图所示:
- 每一个线程有自己独立的input buffer, 将数据写入并将
FULL标志位置起 - FPGA监控
FULL标志位,检测到置起之后通过DMC将数据搬运到FPGA侧的inout buffer - CPU侧等待FPGA侧output buffer的DONE信号
具体流程可以参考如下图所示:
FPGA 逻辑实现
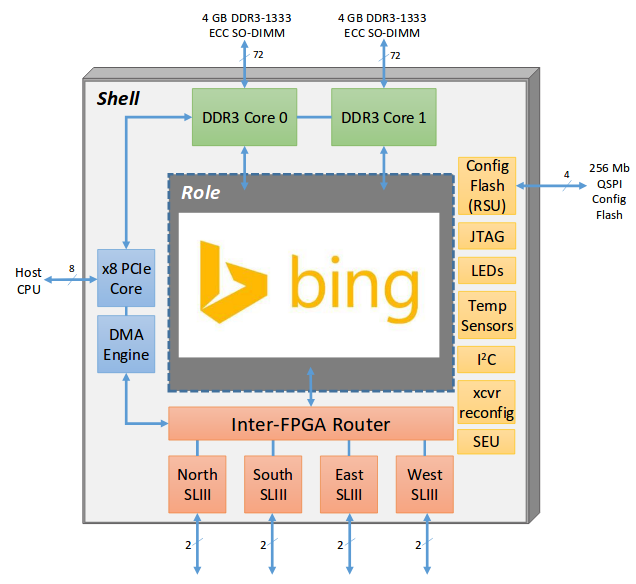
该论文将FPGA的实现分成了Shell和Role两部分,其中Role部分是主要的应用逻辑实现部分,Shell部分是能够复用的部分包括:
- 2个DRAM 控制器,能够独立运行在667MHz或者作为一个800MHz接口
- 4个高速SerialLite III (SL3),用来和邻近FPGA通信
- 和CPU的PCIe通信的控制逻辑以及 PCIe核
- 一些其他接口逻辑
Role和Shell的具体结构可见下图:
Web Search流程
论文中将Bing’s Ranking Engine用FPGA实现,即上面的Role逻辑。 Bing’s Ranking Engine的主要工作如下:
- 当一个查询请求达到服务器时, 服务器从存储器中取得对应文档和元数据, 然后将文档处理成包含相关信息的
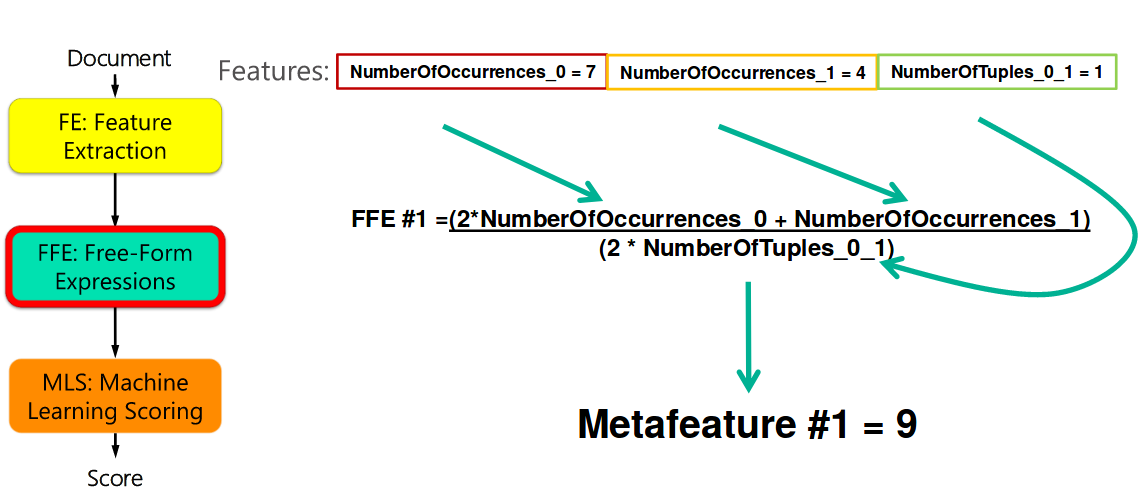
feature, 这一步是feature extraction - 然后会对feature进行处理得到一些综合的feature, 这一步称为
free form expression - 然后这些
feature都会被送到机器学习模型来得到和查询的相关度
上述过程中的feature extraction, free form expression, machine learned model都是在FPGA上实现的, CPU上实现的主要是从存储器读取等操作,具体过程如下图所示:
Feature Extraction 在FPGA上实现如下图所示:
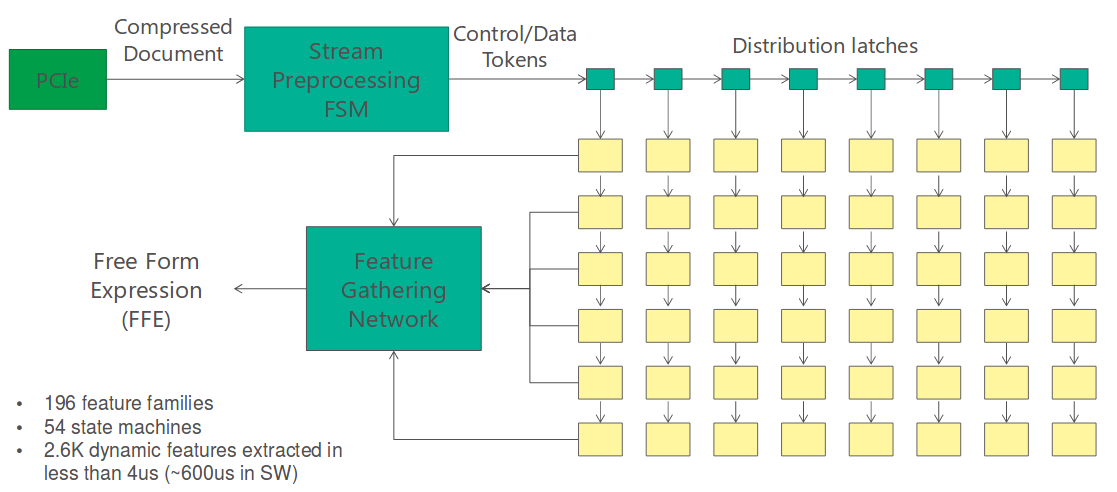
- 首先,文档被送到
Stream Preprocessing FSM, 被分割成控制和数据 - 然后数据被并行分发到43个单独的
feature state matchine来计算feature - 最后上面计算出来的
feature被Feature Gathering Network收集
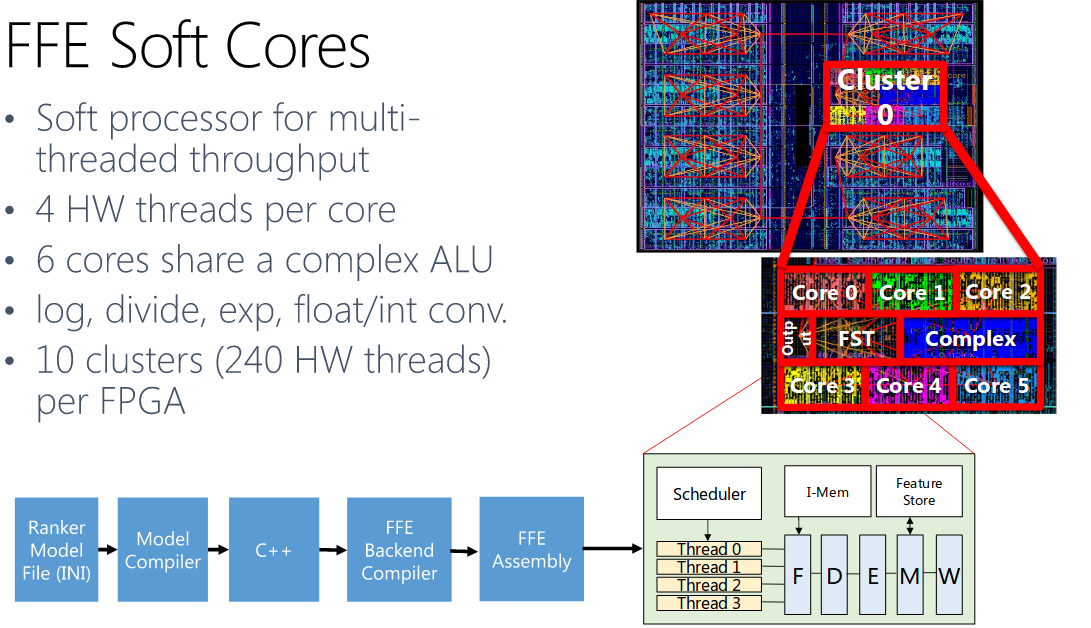
Free Form Expression主要是对Feature Extraction计算出来的Feature进行一些数学的计算来得到新的Feature, 由于这一步对不同的模型差异很大,所以论文采用的方式是使用多线程软核来实现。可以参考下图:
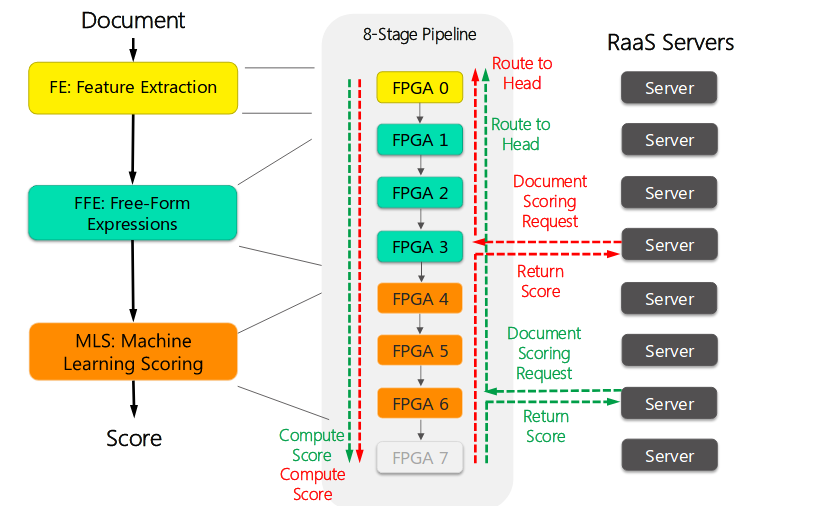
Web Search在系统中实现
上面介绍的Bing's Ranking Engine在整个系统中实现使用了8个FPGA+CPU对, 其中一个是冗余的, 具体功能映射如下所示
Results of the Paper
论文中实现的Web Search在FPGA + CPU上能够实现比纯CPU 相同延时下95%的吞吐量提升,同时减少10%功耗。