
Purpose of the Paper
类似上一篇论文,这篇论文提出的FPGA加速方案也是将FPGA放置于NIC和CPU之间, 在文中被称为in-line-accelerator。不同的是, 本篇论文专注于对内存键值数据库–memcached 进行加速。 提出的主要方案就是将对系统中对Memcached的访问分为fast-path和slow path, 将fast path相关的操作在FPGA中实现, 而slow path仍然放在CPU中。
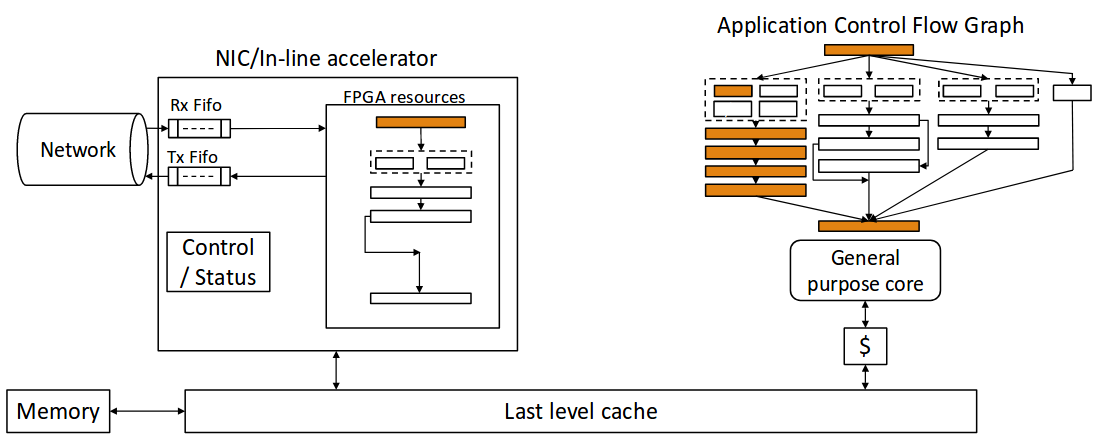
论文中提出的in0line accelerator架构如下图所示:
Methods used in the Paper
in-line accelerator实现的关键是要将应用区分出fast path和slow path。文中使用的方法是使用Valgrind对100万次Memcached 的读取请求进行剖析。结果发现对于99%的读取请求都能够用1330个静态指令执行完成。 这一点对于设计至关重要,这说明能够用硬件将这些热指令有效的实现,其他少见的则仍然交给CPU执行。
对于上面的in-line accelerator, 首先, NIC接收到网络数据, 然后交给in-line accelerator来处理数据, 如果加速器发现不能处理数据, 则还是发给CPU处理, 否则直接对CPU和FPGA的共享内存来处理数据结构,并返回结果。
而加速器得基本结构则是多个支持多线程的引擎。 独立的数据包会被不同的引擎处理。每一个引擎都是执行特定一系列指令的状态机,同时访问引擎之外的资源不超过一次, 设计保证每个状态结束在锁定状态并且能够切换到其他线程如果当前线程访问引擎外资源会导致长时延。同时对于Memcahced加速应用, CPU和FPGA通过共享内存, 能够共享相同的数据结构。
加速器和软件实现性能以及功耗数据对比如下图所示:
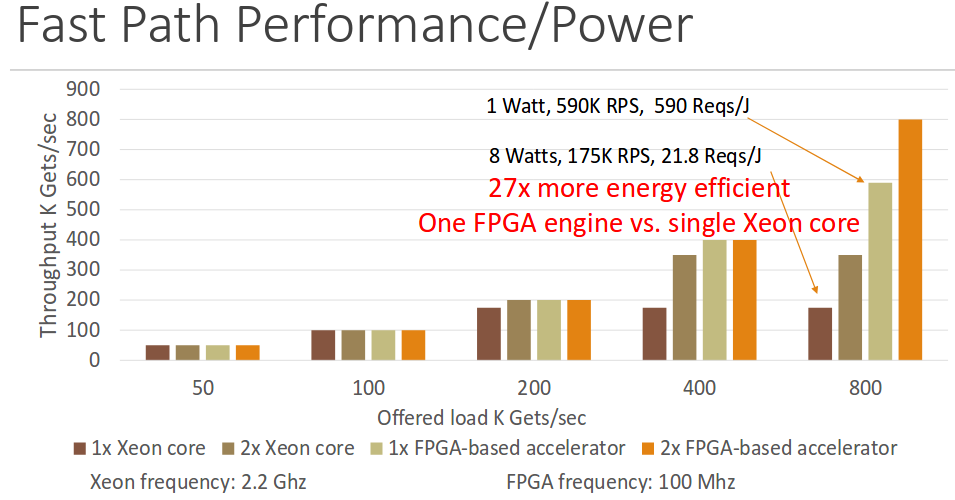

Results of the Paper
本篇论文主要关注点在于将应用分成fast path和slow path, 然后在FPGA里对fast path部分进行加速。除了可以对Emmcahced应用加速外, 对于TCP协议栈,轻量服务器等进行加速, 而加速器设计关键点就在于能够区分出fast path和slow ptah, 对于slow path,则将其将给CPU执行。特别是对时延敏感的应用,能够极大提高性能同时减少功耗。