
前言
从2012年AlexNet引发的AI热潮,到今天已经过去10多年了,AI仍然是当前最火热的话题。寒武纪的前身是DianNao学术项目,起源于2012年的神经网络加速器,可以说是随着AI技术一起发展。因此,了解DianNao项目如何从最开始的DianNao神经网络专用架构,演进到通用的Cambricon指令集和加速器。这一演进历史也可以看着是AI加速器的进化之路,不仅是了解AI这10多年发展的一个窗口,更有助我们自己设计AI加速器和指令集。
概述
DianNao项目的目标是面向机器学习研究加速器架构。本项目是中科院计算所的陈云霁教授和法国Inria的Olivier Temam间的一个学术合作项目,双方为此设立了联合实验室。Temam教授和陈教授的合作始于DianNao, DianNao在ISCA-2012加速器的基础上增加了局部存储,使其可以捕捉深度神经网路的数据局部性并由此克服内存带宽的限制。DianNao加速器的设计发表于ASPLOS-2014,获得了该会议的最佳论文奖。
DaDianNao是DianNao家族的第二个加速器,是DianNao的多片版本,有两个主要的设计目标:一是揭示神经网络层的可分特性使得加速器可具备极好的可扩展性,二是聚集足够多的片上存储来将整个机器学习模型都放在片上,从而克服内存带宽的限制。这个被称为DaDianNao的设计发表在MICRO-2014上,获得了该会议的最佳论文奖。
ShiDianNao是DianNao家族的第三个加速器,为了克服嵌入式应用中内存带宽限制,通过加速器和传感器的直连来绕过内存,发表于2015年的ISCA上。
PuDianNao是DianNao家族的第四个加速器,拓展至多种机器学习算法,因为这些算法多具有类似的运算操作,发表于ASPLOS-2015。
陈云霁教授和中科院计算所团队为一大类神经网络加速器设计了一套名为Cambricon的指令集。该指令集发表于ISCA-2016,在该会议的同行评议中获得了最高分。
本文通过系统性回顾整个DianNao系列加速器,试图通过DianNao系列加速器发展的历史脉络,来展现最近10年AI计算架构的变迁,技术的演进,进而窥见计算技术发展的未来。
本文组织形式如下:
- 第一章介绍DianNao解决的问题,硬件架构,存储结构以及编程模型
- 第二章介绍DaDianNao面向的问题,硬件架构,存储结构以及编程模型
- 第三章介绍ShiDianNao解决的问题,硬件架构,存储结构以及编程模型
- 第四章介绍PuDianNao面向的问题,硬件架构,存储结构以及编程模型
- 第五章介绍Cambricon指令集,加速器原型硬件架构,存储结构以及编程模型
- 文章最后列出了主要的参考文献
DianNao
神经网络结构
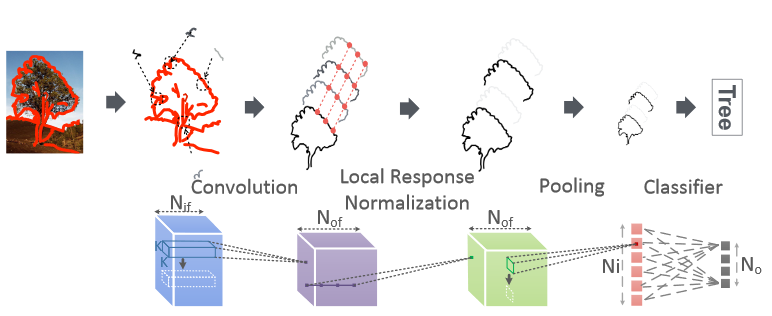
DianNao是面向机器学习的加速器架构,所以,在介绍具体硬件架构之前,需要先了解要解决的问题;对于DianNao,解决问题局限在采用神经网络的机器学习算法。通常,这些神经网络算法由很多层组成,这些层按顺序独立执行;每层包括几个特征映射子层,分别称为输入特征映射和输出特征映射。总体而言,主要有三种层,卷积层,池化层和分类层。如下图所示:
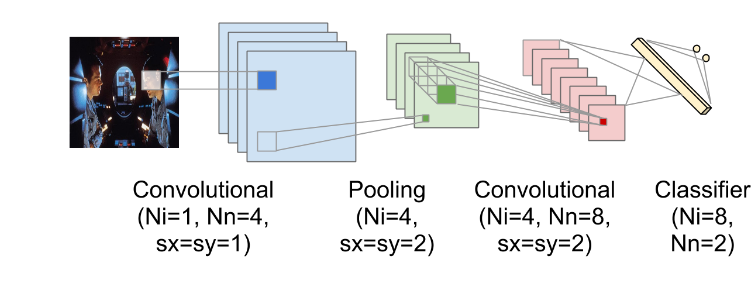
- 卷积层(Convolutional layers) 卷积层主要是在输入层上应用一个或多个filters;因此,输入和输出特征层之间的连接是局部的,而非全连接;一般后面会使用一个非线性函数处理输出
- 池化层(Pooling layers) 又称作下采样,主要是用于在输入数据里聚焦信息;通常会导致特征映射的维度减少
- 分类层(Classifier layers) 在很深的神经网络结构里,卷积层和池化层一般交织组成主要结构,而最后通常是一个分类层。和卷积层类似,一般会使用一个非线性函数处理输出,通常是sigmoid, 比如 $f (x) = \frac{1}{1+e^{−x}}$ ; 和卷积层或池化层不同的是,分类层通常会在所有特征映射里聚焦信息
硬件架构
DianNao采用65nm工艺,设计了一个3.02mm2,功耗485mW的加速器,运行在0.98GHz,每秒可完成452GOP;相比2GHZ,128位的SIMD处理器,加速器快了117.87倍,而且功耗降低了21.08倍;下图展示了加速器的物理版图:

加速器主要由下列三部分组成:
- NBin 存储输入神经元的输入缓冲
- NBout 存储输出神经元的输出缓冲
- SB 存储权重的缓冲
- NFU(Neural Functional Unit) 计算单元
- CP 控制逻辑
整体架构框图如下所示:
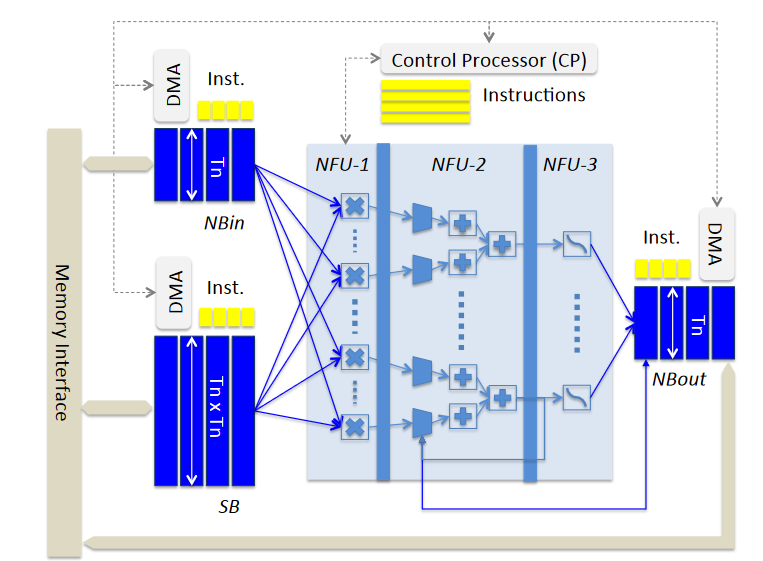 NFU流水线由3部分组成,分别是NFU-1,NFU-2和NFU-3;其中
NFU流水线由3部分组成,分别是NFU-1,NFU-2和NFU-3;其中
- NFU-1 主要对应分类层和卷积层,由256个16位截位乘法器组成;
- NFU-2 由16个加法树组成,每个加法树包含15个加法器,也对应分类层和卷积层,如果池化层使用平均池化也会使用;另外还有一个主要用于池化层的16输入的移位器和最大比较器;
- NFU-3 则有16个16位截位乘法器和16个加法器,主要用于分类层和卷积层,池化层也可能会用到
对于分类层和卷积层,NFU-1和NFU-2每个周期都会激活,每周期可以完成256 + 16 × 15 = 496个定点操作;而在每层操作最后,NFU-3可能会激活,同时NFU-1和NFU-2继续处理剩下的数据,所以短时间内可以实现每周期496 + 2 × 16 = 528个操作。
NFU主要核心是将一个层分解到16x16的计算模块上,主要需要用到tiling,具体可以参考编程模型里的伪代码。
NFU-3里sigmoid函数使用插值算法,同时使用一块RAM存储16段系数;因此,可以通过更新RAM里的系数来调整实现的函数。
存储
加速器采用scratchpad来作为存储结构,而不是通常的缓存,因为scratchpad可以通过软件实现局部性复用,而免去缓存带来的复杂性。DianNao将存储分成三块:NBin, NBout和SB;分开存储的目的主要是降低功耗和减少数据存储的冲突;存储结构上有如下这些特性:
- DMA 为了利用空间局部性,每个缓冲都实现了一个DMA;DMA请求通过指令方式发射到NBin,这些请求会被对应缓冲里的FIFO接收,当DMA完成上一个存储请求之后会按顺序处理FIFO里剩下的请求;这种方式允许提前加载缓冲来避免长时间的延迟。NBin和SB同时充当了预加载缓冲和复用缓冲,所以使用了双口SRAM。
- NBin数据复用 所有的输入层数据都被分割成NBin大小的块,通过将NBin实现成环形缓冲,可以实现数据的复用。硬件实现上只需要更新寄存器的索引,而不需要实际移动数据。
- NBin数据转置 卷积层和池化层在数据结构上有冲突,卷积层需要所有维度的数据来计算输出,而池化层则针对每一个维度计算;因此,当操作池化层从NBin里加载数据时会对数据进行转置操作之后送到NFU。
- 部分和专用寄存器 NBin里数据计算出部分和之后,不是写回到内存,而是保存到NFU-2里的专用寄存器,从而不必将部分和移除NFU流水线,减少功耗。
- 复用NBout NBout只在最后用来保存输出到内存的数据,因此,只要最后结果没有计算出来,NBout一直处于空闲状态;所以,可以利用NBout来保存部分和。NBout不仅需要和NFU-3以及 内存连接,还需要连接NFU-2;NBout里的数据可以加载到NFU-2里的专用寄存器,这些寄存器也可以保存到NBout。
编程模型
由于DianNao里存储结构和计算单元的限制,对原始的计算必须采用切片(tiling)才能适配到加速器上,下面分别展示了卷积层,池化层和分类层采用切片之后的伪代码。 卷积层伪代码,包括对空间局部性的优化:
for (int yy = 0; yy ¡ Nyin; yy += Ty) {
for (int xx = 0; xx ¡ Nxin; xx += Tx) {
for (int nnn = 0; nnn ¡ Nn; nnn += Tnn) {
// — Original code — (excluding nn, ii loops)
int yout = 0;
for (int y = yy; y < yy + Ty; y += sy) { // tiling for y;
int xout = 0;
for (int x = xx; x < xx + Tx; x += sx) { // tiling for x;
for (int nn = nnn; nn < nnn + Tnn; nn += Tn) {
for (int n = nn; n < nn + Tn; n++)
sum[n] = 0;
// sliding window;
for (int ky = 0; ky < Ky; ky++)
for (int kx = 0; kx < Kx; kx++)
for (int ii = 0; ii < Ni; ii += Ti)
for (int n = nn; n < nn + Tn; n++)
for (int i = ii; i < ii + Ti; i++)
// version with shared kernels
sum[n] += synapse[ky][kx][n][i] * neuron[ky + y][kx + x][i];
// version with private kernels
sum[n] += synapse[yout][xout][ky][kx][n][i]} * neuron[ky + y][kx + x][i];
for (int n = nn; n < nn + Tn; n++)
neuron[yout][xout][n] = non linear transform(sum[n]);
}
xout++;
}
yout++;
}
}
}
}
池化层伪代码,包括对空间局部性的优化:
for (int yy = 0; yy ¡ Nyin; yy += Ty) {
for (int xx = 0; xx ¡ Nxin; xx += Tx) {
for (int iii = 0; iii ¡ Ni; iii += Tii) {
// — Original code — (excluding ii loop)
int yout = 0;
for (int y = yy; y < yy + Ty; y += sy) {
int xout = 0;
for (int x = xx; x < xx + Tx; x += sx) {
for (int ii = iii; ii < iii + Tii; ii += Ti) {
for (int i = ii; i < ii + Ti; i++)
value[i] = 0;
for (int ky = 0; ky < Ky; ky++) {
for (int kx = 0; kx < Kx; kx++) {
for (int i = ii; i < ii + Ti; i++)
// version with average pooling;
value[i] += neuron[ky + y][kx + x][i];
// version with max pooling;
value[i] = max(value[i], neuron[ky + y][kx + x][i]);
}
}
}
}
// for average pooling;
neuron[xout][yout][i] = value[i] / (Kx * Ky);
xout++;
}
yout++;
}
}
}
分类层伪代码,包括对空间局部性的优化:
for (int nnn = 0; nnn ¡ Nn; nnn += Tnn) { // tiling for output neurons;
for (int iii = 0; iii ¡ Ni; iii += Tii) { // tiling for input neurons;
for (int nn = nnn; nn ¡ nnn + Tnn; nn += Tn) {
for (int n = nn; n ¡ nn + Tn; n++)
sum[n] = 0;
for (int ii = iii; ii ¡ iii + Tii; ii += Ti)
// — Original code
for (int n = nn; n < nn + Tn; n++)
for (int i = ii; i < ii + Ti; i++)
sum[n] += synapse[n][i] * neuron[i];
for (int n = nn; n < nn + Tn; n++)
neuron[n] = sigmoid(sum[n]);
}
}
}
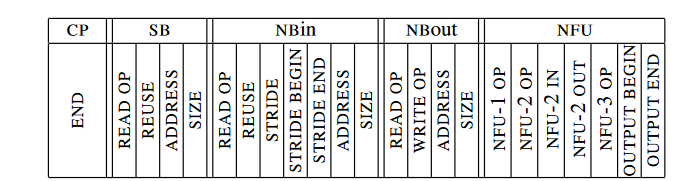
每一层都被分解成一系列的指令来执行;大致上,一个指令对应于分类层和卷积层伪代码里的循环ii,i和n;池化层里的循环ii,i。指令保存在CP里的SRAM里,并驱动三个缓冲里的DMA和NFU执行。硬件上,这些指令实际是一个可配置的状态机完成的。每个指令有五个槽,分别对应CP,三个缓冲和NFU,具体格式如下所示:
 对于DianNao,只有三种主要类型的代码,所以针对三个层,实现了专门的代码生成器,而不是编译器。下面以一个分类层生成的代码为例说明
对于DianNao,只有三种主要类型的代码,所以针对三个层,实现了专门的代码生成器,而不是编译器。下面以一个分类层生成的代码为例说明
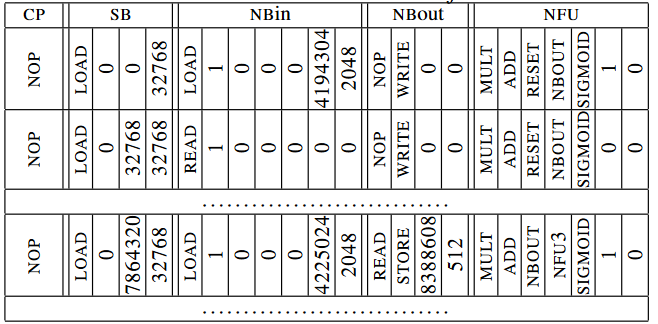 NBin一共2KB,分成64行,每行可以存储16个16位数据;而一共有8192个16位数据,即16KB,所以需要对数据按照2KB来分片。第一个指令里NBin是LOAD (从内存加载数据), 并且标记为复用;接下来一个指令里NBin是READ,因为数据保存在环形缓冲里,并且也标记为复用,因为数据切片成8份; 同时,这两条指令的NFU-2输出是NBout,所以NBout里是WRITE;而NFU-2的操作是RESET;最后,当最后一个分片数据加载完之后,NBout被设置为STORE,将256个输出通过DMA写回到内存。
NBin一共2KB,分成64行,每行可以存储16个16位数据;而一共有8192个16位数据,即16KB,所以需要对数据按照2KB来分片。第一个指令里NBin是LOAD (从内存加载数据), 并且标记为复用;接下来一个指令里NBin是READ,因为数据保存在环形缓冲里,并且也标记为复用,因为数据切片成8份; 同时,这两条指令的NFU-2输出是NBout,所以NBout里是WRITE;而NFU-2的操作是RESET;最后,当最后一个分片数据加载完之后,NBout被设置为STORE,将256个输出通过DMA写回到内存。
加速器支持单个图像或批处理,生成代码里只有CP值会变化。
DaDianNao
为了支持日益扩大的神经网络模型,DaDianNao是一个支持扩展到64个节点的加速器架构,相比GPU,可以实现450.65倍提速,而减少150.31倍功耗。
神经网络结构
和DianNao一样,DaDianNao也是针对神经网络的加速器;不过相比DianNao,除了卷积层,池化层和分类层,DaDianNao增加了一个局部响应归一化层。DaDianNao针对的神经网络结构如下所示:
硬件架构
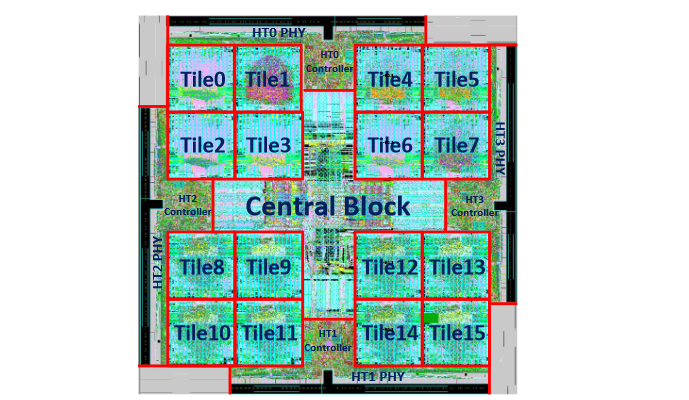
DaDianNao每个节点采用28nm工艺,面积30.16 mm2,运行在606MHz,包括4MB的eDRAM和16个tile;每个tile面积1.89 mm2,包括4个1024x4096的eDRAM bank,一共2MB。具体物理规划版图如下所示:
DaDianNao由一系列的节点以mesh拓扑结构组成,而单个节点则包括16个tile,2个中间的eDRAM bank,以及fat-tree互联;而一个tile则包括一个NFU, 4个eDRAM banks以及和中间eDRAM banks连接的输入输出接口。节点和Tile结构如下所示:
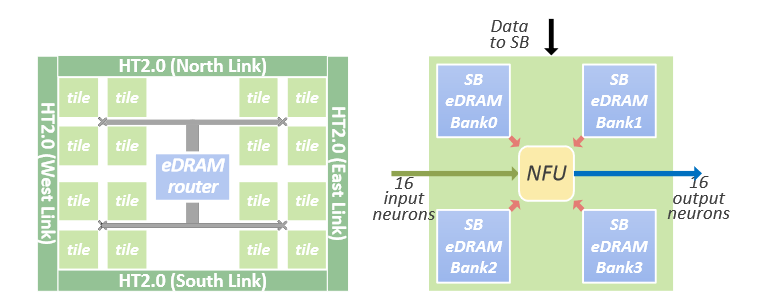 节点内互联采用wormhole路由,有5个接口(东南西北四个接口和一个设备接口),每个接口有8个虚拟通道,每个虚拟通道队列有5项;路由一共4个流水阶段:路由计算(RC),虚拟通道分配(VA),交换分配(SA),和交换传输(ST)。
每个NFU能同时处理16x16个操作,因此,每周期只需要从eDRAM读取16 × 16 × 16 = 4096位数据;每个Tile里的eDRAM分成4个4096位宽的eDRAM来补偿eDRAM需要刷新的缺陷。16个tile使用fat-tree拓扑进行互联,输入数据会广播到每个tile,而每个tile输出则通过互联汇总到中间的eDRAM。
节点内互联采用wormhole路由,有5个接口(东南西北四个接口和一个设备接口),每个接口有8个虚拟通道,每个虚拟通道队列有5项;路由一共4个流水阶段:路由计算(RC),虚拟通道分配(VA),交换分配(SA),和交换传输(ST)。
每个NFU能同时处理16x16个操作,因此,每周期只需要从eDRAM读取16 × 16 × 16 = 4096位数据;每个Tile里的eDRAM分成4个4096位宽的eDRAM来补偿eDRAM需要刷新的缺陷。16个tile使用fat-tree拓扑进行互联,输入数据会广播到每个tile,而每个tile输出则通过互联汇总到中间的eDRAM。
tile内部NFU和DianNao差别不是太大,也是分成三个阶段,主要差异来自于NBout的组织方式,具体架构框图如下所示:
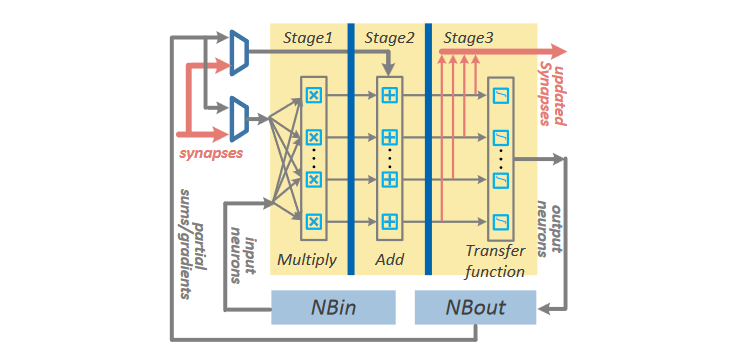 NFU流水线针对推理和训练,以及不同的神经网络层,需要不同的配置,每个硬件模块都支持16位的输入和32位的输出。NFU可以分解成:
NFU流水线针对推理和训练,以及不同的神经网络层,需要不同的配置,每个硬件模块都支持16位的输入和32位的输出。NFU可以分解成:
- 加法模块 可以配置成256个输入, 16个输出的加法树或 256个并行加法器
- 乘法模块 256并行乘法器
- 最大值模块 16个并行最大值操作
- 变换模块 分成两个独立子模块,可以完成16个分段线性插值;插值的系数保存在2个16项的SRAM里,可以通过修改系数来实现不同的变换函数和偏置
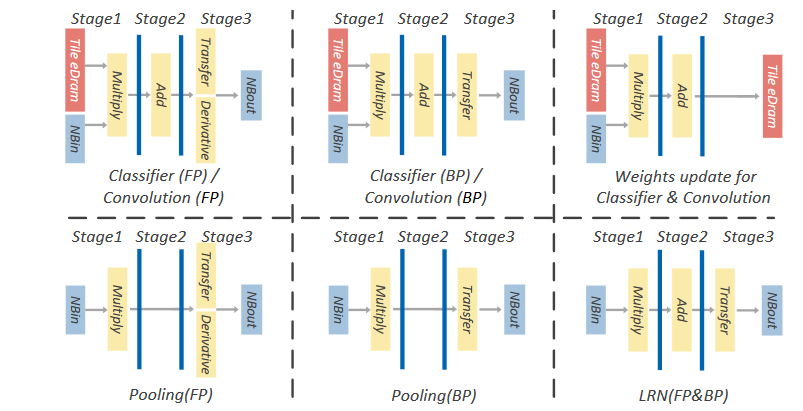
除了上述流水线和硬件模块的需要配置之外,还需要根据不同的数据移动方式来对tile进行配置。比如,对于分类层,输入可能来自中间的eDRAM,也可能来自于tile内部的NBin和NBout(都是16KB的SRAM),甚至是临时值;对于反向传播,NFU必须将更新后的权重输出写到tile内部eDRAM。下图展示了NFU分别配置成CONV, LRN, POOL和CLASS神经网络层:
节点之间互联采用HT(HyperTransport) 2.0,HT2.0物理层在28nm工艺面积是5.635mm × 0.5575mm;节点互联拓扑采用2D mesh,每个方向HT 2.0接口是16组差分信号(16组输入,16组输出),运行在1.6GHz;HT接口和中间eDRAM之间连接是128位宽,有深度4的FIFO;每个HT能提供6.4GB/s带宽,节点间延迟80ns。
存储
DaDianNao架构既要做训练,又要做推理,为了较少数据移动,tile里eDRAM用来存储权重。eDRAM相比SRAM,面积更小,和DRAM相比,功耗更低;但是缺点是延迟比SRAM大,而且需要定期刷新。为了能够给NFU每周期提供数据,tile里的eDRAM组织成4个bank,数据交织使用;中间eDRAM分成两个bank,一个用于输入神经元,一个用于输出神经元。对于神经网络模型而言,即使很多tile和节点组成的系统,所有NFU里的输出神经元还是偏少的,因此,对于广播到每个tile的输入神经元,会在同样硬件上计算多个输出神经元。中间值会存储在tile内部eDRAM里,只有所有输入神经元都计算完,得到的输出神经元才会通过互联存储到中间eDRAM。对于一个节点,有如下这些存储单元:
- 16KB的NBin,采用SRAM,每个tile一个,用来存储NFU计算输入
- 16KB的NBout,采用SRAM,每个tile一个,用来存储NFU计算的输出
- 2MB的eDRAM,tile内部分成4个bank,存储权重
- 4MB的eDRAM,节点中间,分成两个bank,一个用于输入神经元,一个用于输出神经元
编程模型
DaDianNao只需要进行配置,并提供相应数据;输入数据在节点之间进行分区,并存储在节点中间的eDRAM里;神经网络的配置则是由代码生成器生成的指令序列。指令格式如下所示:
 下面是分类层 (Ni = 4096, No = 4096, 4节点)指令序列:
下面是分类层 (Ni = 4096, No = 4096, 4节点)指令序列:
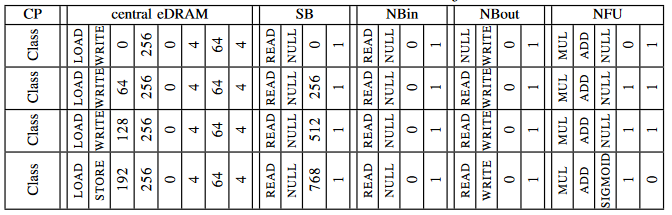 数据被分割成多个256位的数据块,每个数据块包含256/16 = 16个神经元;每个节点分配4096/16/4 = 64个数据块,每个tile分配64/16 = 4个数据块,所以每个节点需要4个指令; 前面三个指令会从中间eDRAM给所有tile分发数据,同时从tile内部eDRAM里读取权重,然后将计算部分和写入到NBout;最后一个指令时,每个tile内部NFU会计算出最终的和,并进行变换计算,最后将结果写回到中间eDRAM。
这些节点指令会将相应的控制发送到每个tile,一个节点或tile指令对一套连续的输入数据完成同一层的计算;因为同一个指令的输入数据是连续的,因此指令里只需要使用开始地址,步长和迭代次数。
另外,不同节点以同样速度处理几乎相同的数据量,DaDianNao采用了computing-and forwarding的通信模式,即一个节点一旦完成计算,就可以马上处理新输入的数据;所以不需要全局同步或屏障指令。
数据被分割成多个256位的数据块,每个数据块包含256/16 = 16个神经元;每个节点分配4096/16/4 = 64个数据块,每个tile分配64/16 = 4个数据块,所以每个节点需要4个指令; 前面三个指令会从中间eDRAM给所有tile分发数据,同时从tile内部eDRAM里读取权重,然后将计算部分和写入到NBout;最后一个指令时,每个tile内部NFU会计算出最终的和,并进行变换计算,最后将结果写回到中间eDRAM。
这些节点指令会将相应的控制发送到每个tile,一个节点或tile指令对一套连续的输入数据完成同一层的计算;因为同一个指令的输入数据是连续的,因此指令里只需要使用开始地址,步长和迭代次数。
另外,不同节点以同样速度处理几乎相同的数据量,DaDianNao采用了computing-and forwarding的通信模式,即一个节点一旦完成计算,就可以马上处理新输入的数据;所以不需要全局同步或屏障指令。
ShiDianNao
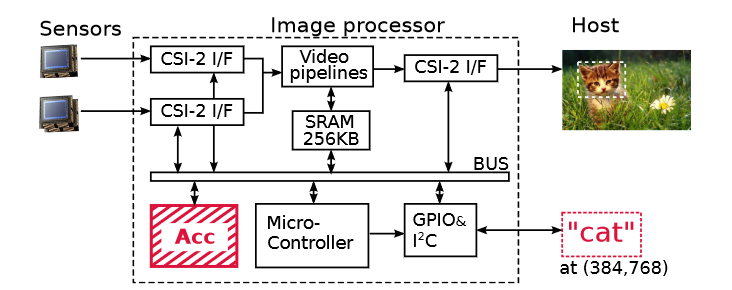
ShiDianNao是一个CNN加速器,放置在CMOS或CCD传感器旁边。在许多应用中,例如智能手机、安全、自动驾驶汽车,图像直接来自CMOS或CCD传感器。图像由CMOS/CCD传感器采集,发送到DRAM,然后由CPU/GPU获取以进行识别处理。CNN加速器的小尺寸使其可以将其提升到传感器旁边,并且仅将识别过程的几个输出字节(通常是图像类别)发送到DRAM或主机处理器,从而几乎完全消除了对存储器的访问。下图展示了ShiDianNao的应用场景:
硬件架构
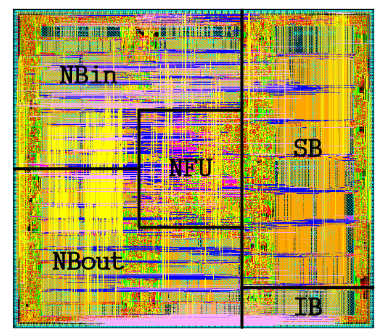
ShiDianNao在硬件上一共有8 × 8 (64)个PEs,64 KB的NBin, 64 KB的NBout, 128 KB的SB, 和32 KB的IB; 工艺65nm,面积4.86mm^2,功耗320mw,运行在1GHz,提供194GOP/s算力;下图展示了ShiDianNao的物理规划版图:
 加速器主要由下列部分组成:
加速器主要由下列部分组成:
- 存储输入神经元的NBin
- 存储输出神经元的NBout
- 存储权重的SB
- 计算单元
- NFU 主要负责神经元乘,加和比较操作
- 算术单元ALU 主要负责激活函数计算
- 指令缓冲和译码单元IB
计算单元采用16位定点,可以有效减少硬件开销,同时不会对神经网络精度产生影响。在65nm工艺下,16位定点乘法器相比32位浮点乘法器,面积小6.1倍,同时功耗少7.33倍。NFU可以从NBin/NBout和SB里同时读取权重和输入数据,并分发到不同PE;PE内部包含存储单元,可以完成PE之间的数据传输;当PE完成计算之后,NFU从PE收集数据并发送到NBin/NBout或ALU。ShiDianNao整体架构框图如下所示:
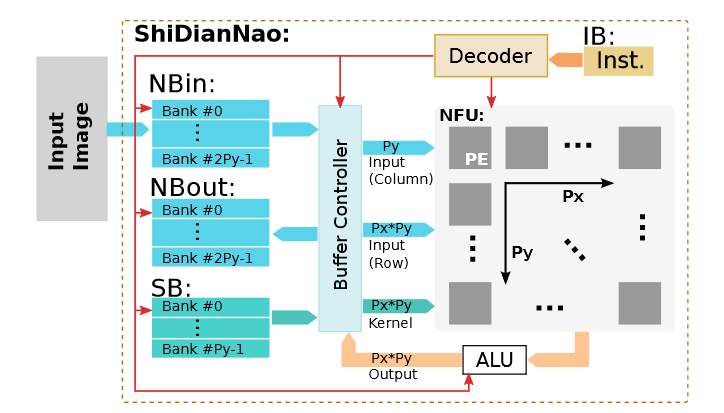
NFU
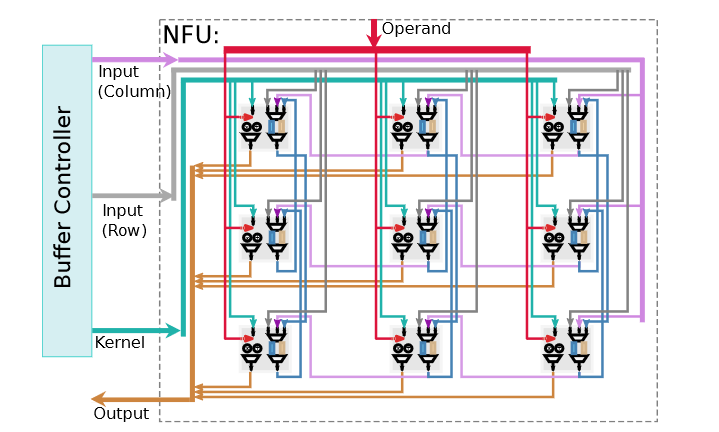
ShiDianNao主要处理图像数据,所以NFU和DianNao上相比,为2D数据处理进行了优化。NFU由8x8个PE(Processing Element)组成2D mesh拓扑,可以高效处理2D数据。直接映射Kx × Ky个PEs (Kx × Ky核函数)来计算一个输出,受限于和函数大小不能有效的利用PE,并且会导致共享数据逻辑变得复杂;因此,ShiDianNao将一个输出神经元映射到一个PE,采用时分复用PE来对输入数据进行计算并输出神经元。下图展示了NFU的微架构框图:
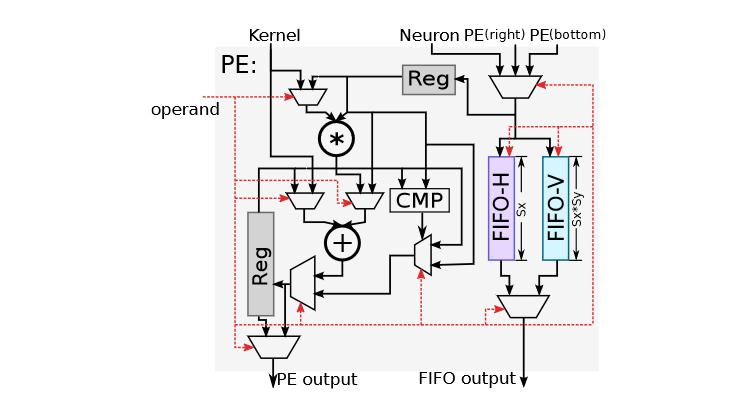
PE
对于卷积层,分类层,归一化层等,每个PE每周期可以完成一个乘加运算;PE有3个输入:一个接收控制信息,一个从SB读取权重,一个从NBin/NBout,右边PE或下边的PE读取输入数据;2个输出,一个将计算结果写入NBout/NBin; 一个用来将输入数据传输到相邻的PE。对于CNN神经网络层,每个PE会持续的累积计算输出,直到当前计算完之后才会计算下一个输出。下图展示了一个PE内部的微架构框图:
 对于CNN网络,不同的PE计算的输出需要的输入数据有一部分时重叠的,如果每个PE都从NBin/NBout里读取数据,需要的带宽会比较大;因此为了支持数据复用,每个PE可以将自己保存的输入数据发送到左边和下边的PE;每个PE有两个FIFO,分别是FIFO-H和FIFO-V,可以临时存储输入数据;FIFO-H可以存储来自NBin/NBout和右边PE的数据,并发送到左边的PE;FIFO-V可以存储来自NBin/NBout和上面PE的数据,并发送给下面的PE。
对于CNN网络,不同的PE计算的输出需要的输入数据有一部分时重叠的,如果每个PE都从NBin/NBout里读取数据,需要的带宽会比较大;因此为了支持数据复用,每个PE可以将自己保存的输入数据发送到左边和下边的PE;每个PE有两个FIFO,分别是FIFO-H和FIFO-V,可以临时存储输入数据;FIFO-H可以存储来自NBin/NBout和右边PE的数据,并发送到左边的PE;FIFO-V可以存储来自NBin/NBout和上面PE的数据,并发送给下面的PE。
ALU
NFU并不能完成CNN网络里所有计算,因此NFU之外有一个ALU,可以完成平均池化和归一化层需要除法,和tanh(),sigmoid()等卷积和池化需要的非线性激活函数。非线性激活函数采用分段线性插值实现,插值需要的线段系数提前保存在寄存器。
NB控制器
NB控制器可以支持NFU里数据复用和计算,对于NBin/NBout,控制器支持6个读模式和一个写模式。下图展示了NB控制器的微架构框图:
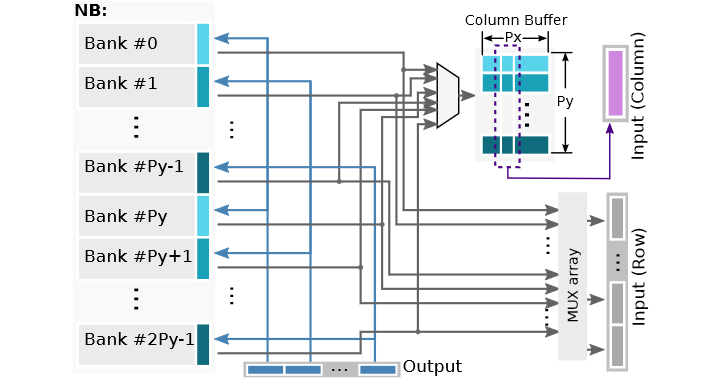 一共2 × Py个bank,每个bank宽度Px × 2 bytes,支持的6个读模式如下:
a. 读多个banks (#0 到 #Py − 1)
b. 读多个banks (#Py 到 #2Py − 1)
c. 读一个bank
d. 读一个神经元
e. 按指定步长读取神经元
f. 每个bank读一个神经元 (#0到 #Py − 1 或#Py 到 #2Py − 1)
一共2 × Py个bank,每个bank宽度Px × 2 bytes,支持的6个读模式如下:
a. 读多个banks (#0 到 #Py − 1)
b. 读多个banks (#Py 到 #2Py − 1)
c. 读一个bank
d. 读一个神经元
e. 按指定步长读取神经元
f. 每个bank读一个神经元 (#0到 #Py − 1 或#Py 到 #2Py − 1)
下图展示了上面6种读模式示意图:
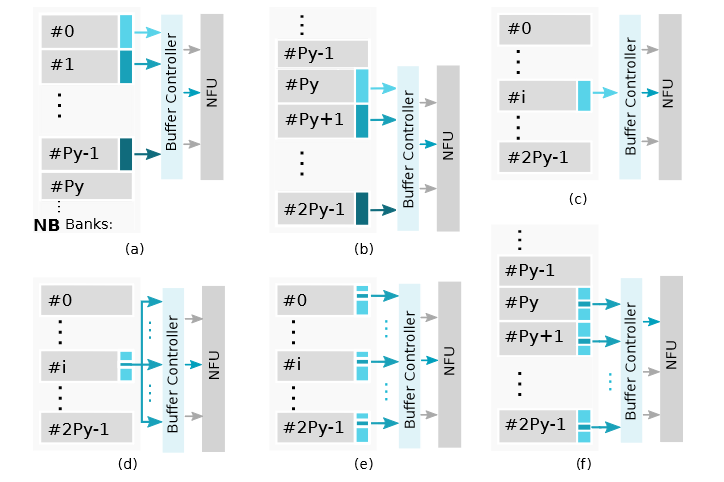 不用的神经网络层需要使用不同的读模式:
不用的神经网络层需要使用不同的读模式:
- 对于卷积层,使用模式a或模式b从NBin的#0 到#Py − 1或#Py 到#2Py − 1 读取输入数据;如果卷积窗口步长大于1,则使用模式e;使用模式c从NB里读取一个bank数据;模式f从NB的#Py 到#2Py − 1 或 #0 到#Py − 1 每个banks读取一个数据
- 对于池化层,和卷积层类似,也可以使用模式a, b, c, e, 或f
- 对于归一化层,会被分解成类似卷积层的子层,所以也可以使用模式a, b, c, e, 或f
- 对于分类层,使用模式d加载同一个输入数据
NB控制器的写模式比较直接,在CNN神经网络模型里,一旦一个PE计算出了输出数据,结果会临时保存在NB控制器的寄存器阵列里;当Px × Py个PEs里计算结果都出来之后, NB控制器马上将结果写到NBout。Px × Py输出数据组织成Py行,每一行Px × 2位, 刚好是一个NB bank。当当输出数据处在2kPx, . . . , ((2k + 1)Px − 1)行 (k = 0, 1, . . . )时,数据会被写到NB的第一个Py bank;否则写到第二个Py banks。具体映射如下所示:
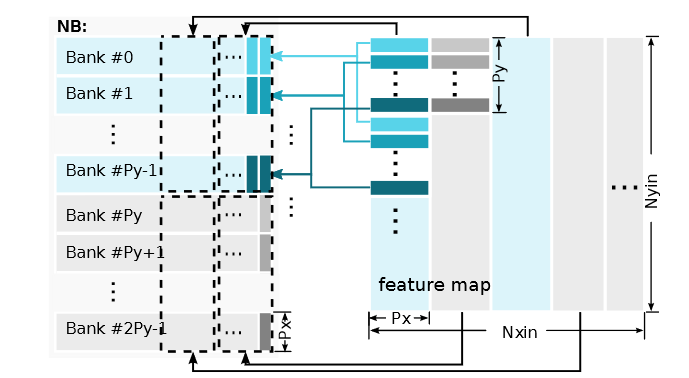
存储结构
ShiDianNao片上存储一共288 KB SRAM,可以同时存储一个CNN网络的所有数据和相关的指令,不需要片外存储。片上存储分为3个缓冲:NBin,NBout和SB,不同缓冲可以使用不同的位宽,减少时间和功耗。NBin用来存储输入数据,NBout存储输出数据,当所有输出数据计算完成之后,NBin和NBout功能交换,之前输出作为下一层的输入,每一个有 2 × Py 个banks;SB存储权重,一共Py个bank。
编程模型
为了较少配置硬件的指令需要的SRAM空间,ShiDianNao采用了2层的HFSM(Hierarchical Finite State Machine)来控制加速器的执行流。第一层状态机的状态描述加速器处理的任务,比如神经网络层类型,ALU执行操作等;每一个第一层状态相关联的有几个第二层状态,用来描述具体操作;比如和卷积层状态相关联的包括加载输入输出数据。HFSM状态机如下所示:
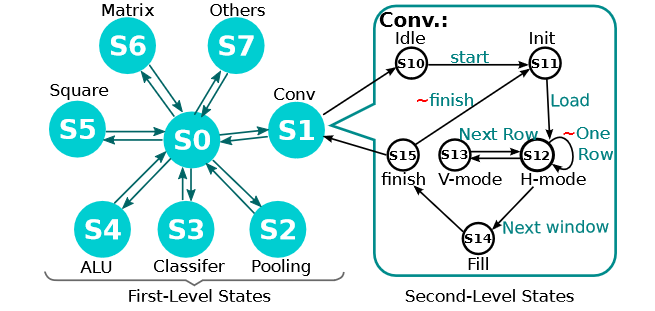 使用61位长度的指令来表示HFSM状态和相应参数,执行5万个周期的CNN网络只需要1KB的指令存储空间。
使用61位长度的指令来表示HFSM状态和相应参数,执行5万个周期的CNN网络只需要1KB的指令存储空间。
PuDianNao
PuDianNao, 可以对包括k-means, k-nearest neighbors, 朴素贝叶斯(naive bayes), 支持向量机(support vector machine), 线性回归(linear regression), 分类树(classification tree), 和深度神经网络(deep neural network)在内的7种机器学习进行加速。机器学习算法一般通过使用的数学模型(线性或非线性),学习方式(监督学习或无监督学习),训练算法(最大后验估计或梯度下降)等进行区分。但是从计算机体系结构上看,机器学习算法可以根据分解的计算原语和数据临近性来分类。通过对上述7种机器学习算法从计算原语和数据临近性上分析,PuDianNao在架构上,采用一个通用的ALU来执行一般操作,而对最耗时的操作卸载到专用硬件执行,实现了对多种机器学习算法的加速。
硬件架构
PuDianNao采用65nm工艺,面积3.51mm^2,功耗596 mW,运行在1GHz,算力1056 GOP/s;相比NVIDIA K20M GPU (28nm工艺), PuDianNao速度上快了1.20倍,功耗降低128.41倍。下图展示了PuDianNao的物理版图:
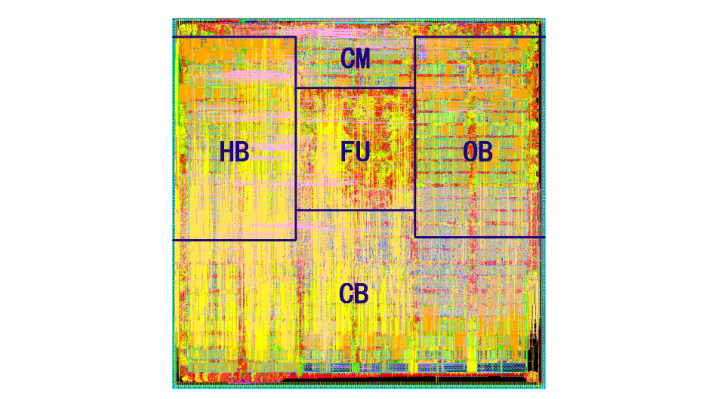 PuDianNao主要由功能单元FUs(Functional Units), 3个数据缓冲(HotBuf, ColdBuf,和OutputBuf), 指令缓冲(InstBuf), 控制模块(CM)和一个DMA组成。下图展示了PuDianNao的架构框图:
PuDianNao主要由功能单元FUs(Functional Units), 3个数据缓冲(HotBuf, ColdBuf,和OutputBuf), 指令缓冲(InstBuf), 控制模块(CM)和一个DMA组成。下图展示了PuDianNao的架构框图:
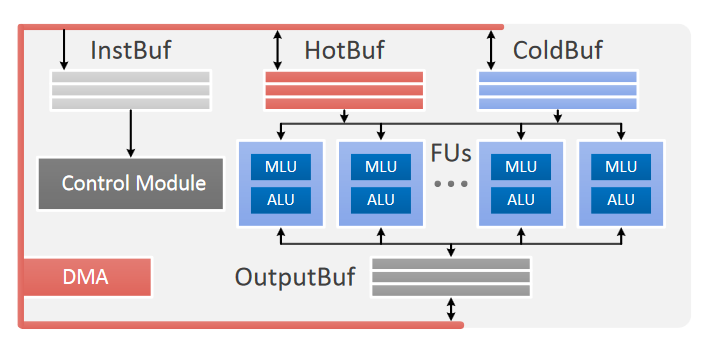 功能单元FUs是加速器计算单元,每个FU由两部分组成,机器学习功能单元MLU(Machine Learning functional Unit )和算数逻辑单元ALU(Arithmetic Logic Unit );PuDianNao一共有16个FUs。
功能单元FUs是加速器计算单元,每个FU由两部分组成,机器学习功能单元MLU(Machine Learning functional Unit )和算数逻辑单元ALU(Arithmetic Logic Unit );PuDianNao一共有16个FUs。
MLU支持机器学习里常见的几种计算原语,包括点乘(LR, SVM, 和DNN), 距离计算(k-NN和k-Means), 计数(ID3和NB), 排序(k-NN 和 k-Means), 非线性函数 (sigmoid 和 tanh) 等。下图展示了MLU微架构框图:
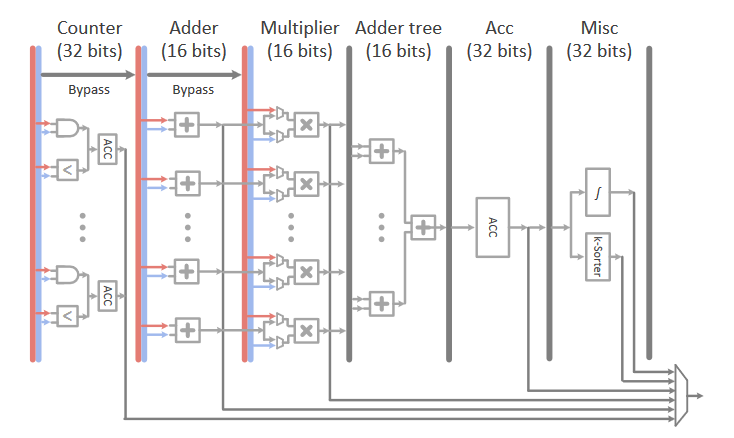 MLU分成6个流水线阶段,分别是Counter, Adder, Multiplier, Adder tree, Acc和Misc。每个MLU包含16+16+15+1+1=49个加法器,分别来自Counter, Adde, Adder tree, Acc和Misc阶段;以及16+1=17 个乘法器, 来自于Multiplier和Misc阶段。 因此,一共可以实现16 × (49 + 17) × 1 = 1056 Gop/s算力。
MLU分成6个流水线阶段,分别是Counter, Adder, Multiplier, Adder tree, Acc和Misc。每个MLU包含16+16+15+1+1=49个加法器,分别来自Counter, Adde, Adder tree, Acc和Misc阶段;以及16+1=17 个乘法器, 来自于Multiplier和Misc阶段。 因此,一共可以实现16 × (49 + 17) × 1 = 1056 Gop/s算力。
- Counter阶段 每对输入都会送到一个与门或比较器,然后结果会进行累加;累加器输出结果直接写到输出缓冲。主要用来加速朴素贝叶斯和分类树里的计数操作;如果不需要进行计数,则可以直接旁路该阶段。
- Adder阶段 支持机器学习里常见的向量加法,计算结果可以写到输出缓冲或者送到下一个流水阶段;如果不需要,则可以直接旁路该阶段。
- Multiplier阶段 支持机器学习里常见的向量乘法,输入数据可以来自上一个Adder阶段,或者输入缓冲;计算结果可以写到输出缓冲或者送到下一个流水阶段。
- Adder tree阶段 对Multiplier阶段的计算结果进行求和,两者结合可以完成LR, SVM, 和DNN等机器学习里常见的点乘运算;如果输入数据维度超过加法树大小,则计算结果是部分和,最终和会在下一个Acc 阶段进行计算;计算出最后结果之后, Acc 阶段计算结果可以写到输出缓冲或者送到下一个流水阶段。
- Misc阶段 包括线性插值模块和k-sorter模块,计算结果写到输出缓冲
- 线性插值模块 可以通过插值表完成机器学习里sigmoid和tanh等非线性函数近似计算
- k-sorter模块 可以从来查找Acc 阶段输出结果里的K个最小值
为了减小面积和功耗,Adder, Multiplier, 和Adder tree阶段都是16位浮点运算;对于Counter, Acc, 和Misc阶段,为了避免溢出,采用32位浮点。
对于机器学习里一些计算类型,比如除,条件赋值等MLU不支持的操作,会在FU里的ALU里执行。ALU里包括加法器,乘法器和除法器,以及32位和16位浮点之间转换逻辑。另外,为了支持分类树需要的对数运算,ALU可以采用泰勒展开进行近似计算。
存储结构
对机器学习算法里数据局部性的分析,切片可以提高数据的局部性;另外,根据数据复用的距离,可以分成2到3类。因此,PuDianNao设计了三种片上存储:
- HotBuf 8KB的单口SRAM,存储复用距离最近的数据
- ColdBuf 16KB的单口SRAM,存储复用距离相对比较长的数据
- OutputBuf 8KB的双口SRAM,存储输出数据或临时数据
之所以拆分成三个片上存储,除了考虑数据局部性之外,还有加载不同数据时位宽不一样。三个片上存储都使用同一个DMA。
编程模型
加速器内部控制模块负责从InstBuf里取指,译码,并将指令分发到所有FUs;所有FUs同步执行一样的操作。指令格式如下所示:
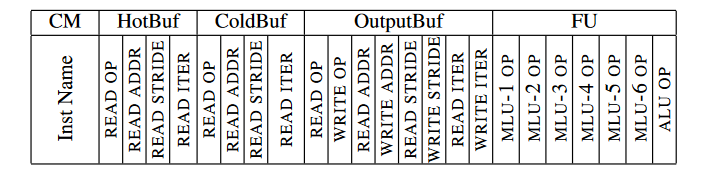 每个指令分成5个槽,CM, HotBuf, ColdBuf, OutputBuf, 和FU;不同的机器学习算法通过代码生成器来生成对应的指令。
每个指令分成5个槽,CM, HotBuf, ColdBuf, OutputBuf, 和FU;不同的机器学习算法通过代码生成器来生成对应的指令。
下面表格提供了生成的 k-Means 代码的示例:
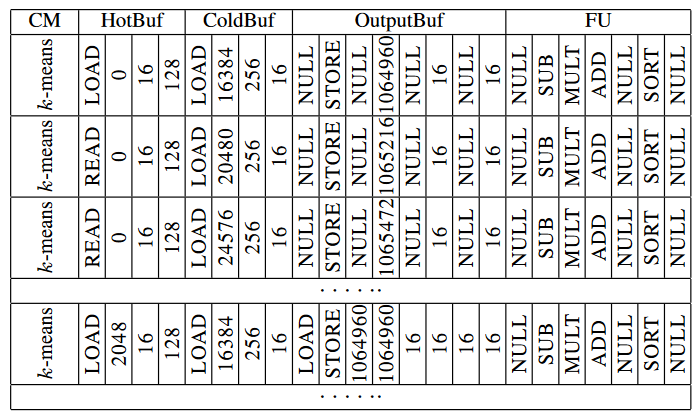 每个实例中的特征数为 f = 16,质心数为 k = 1024,测试实例数为 N = 65536。质心将存储在 HotBuf (8KB) 中,测试实例将存储在 ColdBuf (16KB) 中。为了隐藏DMA 内存访问,我们以乒乓球方式利用 HotBuf 和 ColdBuf。具体来说,在第一个指令中,加速器通过 DMA 从内存中加载 128 个质心 (4KB) 和 256 个测试实例 (8KB),它们分别占据了 HofBuf 和 ColdBuf 的一半。然后,加速器计算加载的质心和测试实例之间的距离。同时,另外 256 个测试实例被加载到 ColdBuf 的另一半,这些实例将由第二条指令使用。在第二条指令中,第一条指令中加载的 128 个质心将被复用,这些质心是从 HotBuf 读取的。当处理完 128 个质心和所有 65536 个测试实例之间的距离计算时(在第 256 条指令之后),将加载一个由 128 个质心组成的新块(在第 257 条指令中)。重复该过程,直到完成所有质心和测试实例之间的距离计算。
每个实例中的特征数为 f = 16,质心数为 k = 1024,测试实例数为 N = 65536。质心将存储在 HotBuf (8KB) 中,测试实例将存储在 ColdBuf (16KB) 中。为了隐藏DMA 内存访问,我们以乒乓球方式利用 HotBuf 和 ColdBuf。具体来说,在第一个指令中,加速器通过 DMA 从内存中加载 128 个质心 (4KB) 和 256 个测试实例 (8KB),它们分别占据了 HofBuf 和 ColdBuf 的一半。然后,加速器计算加载的质心和测试实例之间的距离。同时,另外 256 个测试实例被加载到 ColdBuf 的另一半,这些实例将由第二条指令使用。在第二条指令中,第一条指令中加载的 128 个质心将被复用,这些质心是从 HotBuf 读取的。当处理完 128 个质心和所有 65536 个测试实例之间的距离计算时(在第 256 条指令之后),将加载一个由 128 个质心组成的新块(在第 257 条指令中)。重复该过程,直到完成所有质心和测试实例之间的距离计算。
Cambricon
由于AI模型的飞速发展,专用硬件很难适配新出现的算法;因此,通过借鉴RISC的指令集的设计原则:
- 通过将描述神经网络的复杂指令分解成更短,更简单的指令,可以扩大加速器的应用范围;当有新的模型出现时,用户可以使用这些底层的,简单的指令来组装出新模型需要的计算
- 简单和短的指令可以减少设计和验证的风险,以及译码逻辑的功耗和面积
为了设计出针对神经网络的简洁,灵活,高效的指令集,分析了不同神经网络的计算和存储访问模式,得出了几条设计原则:
- 数据级并行 在大多数神经网络技术中,神经元和突触数据被组织为层,然后以统一/对称的方式进行操作。使用向量或矩阵来挖掘数据并行比使用传统的标量指令来挖掘指令级并行更高效
- 向量和矩阵指令 尽管有许多线性代数库(例如,BLAS库)成功地涵盖了广泛的科学计算应用,但对于神经网络,这些代数库中定义的基本运算不一定是有效和高效的选择(有些甚至是多余的)。更重要的是,神经网络有许多常见的操作,而这些操作是传统线性代数库所未涵盖的。例如,BLAS库不支持向量的元素指数计算,也不支持突触初始化、dropout和受限玻尔兹曼机 (RBM)中的随机向量生成。因此,我们必须定制一组小而具有代表性的向量/矩阵指令,而不是简单地从现有的线性代数库中重新实现向量/矩阵运算。神经网络可以自然地分解为标量、向量和矩阵运算,ISA设计必须有效地利用潜在的数据级并行性和数据局部性。
- 使用片上Scratchpad Memory 神经网络通常需要对矢量/矩阵数据进行密集、连续和可变长度的访问,因此使用固定宽度,且高功耗的向量寄存器文件不是最优选择。使用片上scratchpad memory代替向量寄存器文件,为每次数据访问提供了灵活的数据宽度。因为神经网络中的突触数据通常很大且很少重用,片上scratchpad memory是神经网络中数据级并行性的高效选择
为此,开发了一个新的神经网络加速器的指令集,叫做Cambricon。Cambricon 是一种存储加载架构,其指令均为 64 位,并包含 64 个用于标量的 32 位通用寄存器 (GPR),主要用于控制和寻址目的。为了支持对向量/矩阵数据的密集、连续、可变长度的访问,并且减少面积/功耗开销,Cambricon 不使用向量寄存器文件,而是将数据保存在片上scratchpad memory。与性能受寄存器文件宽度限制的SIMD不同,Cambricon有效地支持更大和可变的数据宽度,因为片上scratchpad memory可以很容易做的比寄存器文件更宽。
针对十种具有代表性的模型(MLP、CNN、RNN、LSTM、Autoencoder 、Sparse Autoencoder、BM、RBM、SOM、HNN),Cambricon 的代码密度比MIPS高13.38 倍、x86(9.86 倍)和 GPGPU(6.41 倍)。与DaDianNao(只能支持3种NN技术)相比,基于Cambricon的加速器原型带来的延迟、功耗和面积开销(分别为4.5%/4.4%/1.6%)很小。
硬件架构
Cambricon原型加速器采用65nm工艺,面积 56.24mm^2,功耗1.695 W,运行在1GHz。下图是Cambricon原型加速器的物理版图:
 Cambricon原型加速器一共7级流水线,取指(fetch), 译码decoding, 发射issuing, 读寄存器register reading, 执行execution, 写回writing back, 和完成committing。 具体架构框图如下所示:
Cambricon原型加速器一共7级流水线,取指(fetch), 译码decoding, 发射issuing, 读寄存器register reading, 执行execution, 写回writing back, 和完成committing。 具体架构框图如下所示:
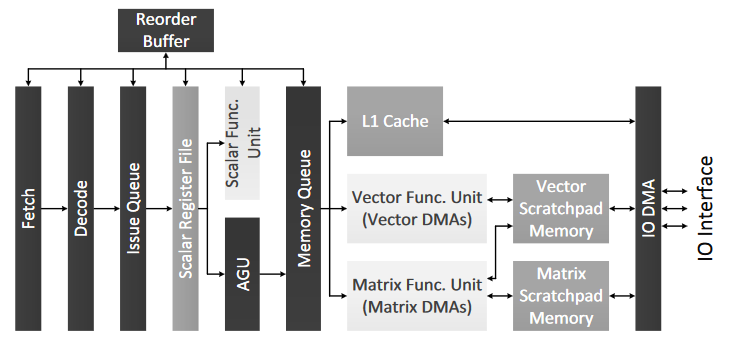 取指和译码之后,指令进入一共顺序发射队列;当标量寄存器文件里的操作数准备好之后(标量或者向量和矩阵的地址和大小),根据指令类型不同,会被发射到不同的执行单元。
取指和译码之后,指令进入一共顺序发射队列;当标量寄存器文件里的操作数准备好之后(标量或者向量和矩阵的地址和大小),根据指令类型不同,会被发射到不同的执行单元。
- 控制指令和标量计算/逻辑操作指令 这些指令被发射到标量单元直接执行,当结果写回到标量寄存器文件后,这些指令可以按序从reorder buffer里完成。
- 数据传输指令,向量/矩阵计算指令和向量逻辑指令 这些指令可能会访问L1缓存或scratchpad memories, 因此会被发射到地址生成单元AGU(Address Generation Unit);并且需要在顺序内存队列(in-order memory queue)里解决和前面指令可能的内存依赖关系。之后标量数据存储加载指令会发送到L1缓存;向量的数据传输,计算和逻辑运算指令会被发送到向量功能单元; 而矩阵的数据传输,计算指令会被发送到矩阵功能单元。执行完成之后,指令可以从内存队列里退休,并按序从reorder buffer里完成。
向量功能单元有32个16位的加法器,32个16位的乘法器和64KB的scratchpad memory。 矩阵单元则包括1024个乘法器和1024个加法器,为了避免物理上的布线困难和搬运数据导致功耗,乘法器和加法器被分成32个单独的计算模块。每个计算模块有24KB的scratchpad。32个计算模块通过H-tree连接,可以广播数据到所有计算模块并收集输出数据。
存储结构
在Cambricon原型加速器里,存在发射队列,内存队列,reorder buffer,L1缓存,以及scratchpad memory。发射队列和scratchpad memory大小如下所示:
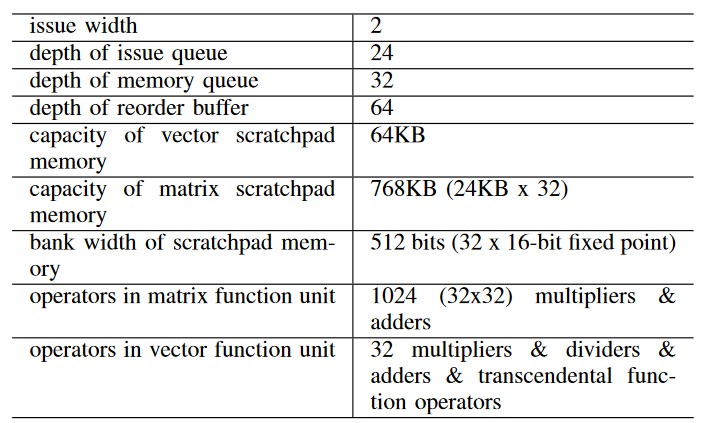 为了高效访问scratchpad memories, 向量和矩阵功能单元都集成了3个DMA,每一个分别对应向量和矩阵指令里的输入和输出。另外,scratchpad memory还带有一个IO DMA。为了解决4个DMA并发的读写请求,使用地址的低两位将scratchpad memory分成4个bank,并将4个bank通过crossbar和4个DMA相连。这样避免了使用昂贵的多端口向量寄存器文件,并可以使用scratchpad memory支持灵活的数据位宽。下图展示了矩阵功能单元里的scratchpad memory的结构框图:
为了高效访问scratchpad memories, 向量和矩阵功能单元都集成了3个DMA,每一个分别对应向量和矩阵指令里的输入和输出。另外,scratchpad memory还带有一个IO DMA。为了解决4个DMA并发的读写请求,使用地址的低两位将scratchpad memory分成4个bank,并将4个bank通过crossbar和4个DMA相连。这样避免了使用昂贵的多端口向量寄存器文件,并可以使用scratchpad memory支持灵活的数据位宽。下图展示了矩阵功能单元里的scratchpad memory的结构框图:
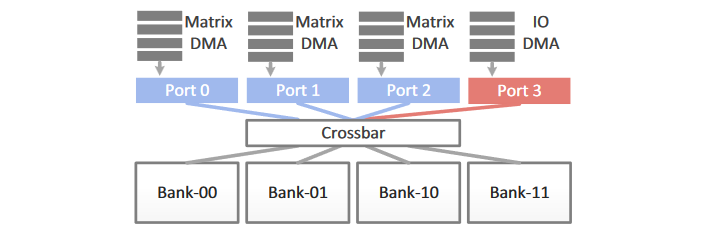
编程模型
Cambricon包含四种类型的指令:计算指令、逻辑指令、控制指令和数据传输指令。尽管不同的指令的有效位数可能不同,但指令长度固定为 64 位,以便内存对齐和简化加载/存储/解码逻辑的设计。Cambricon支持的指令集如下所示:
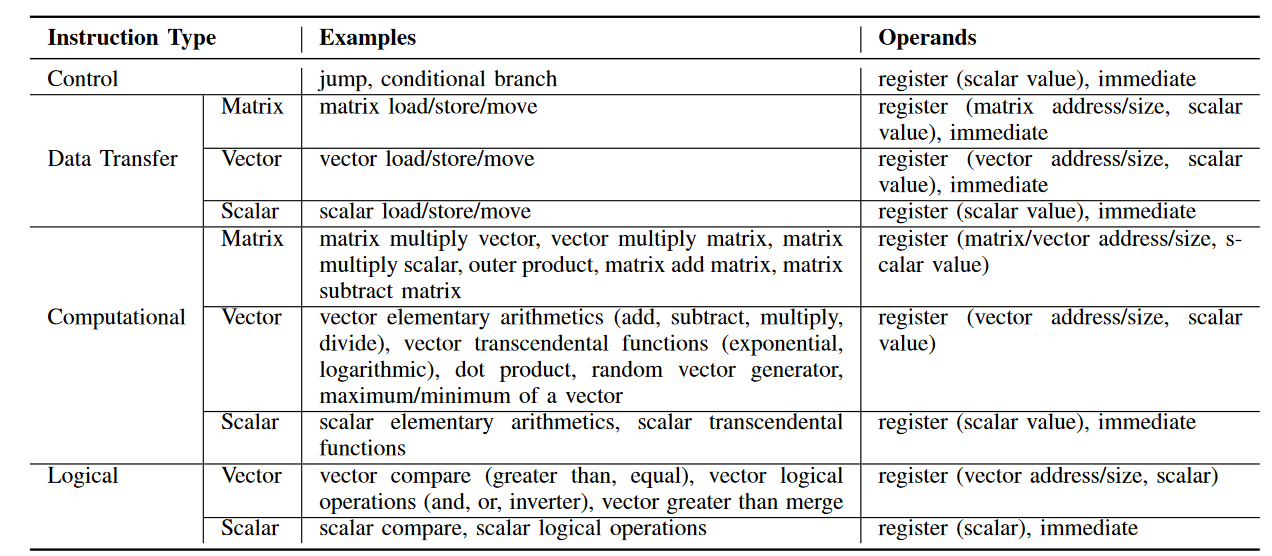
-
控制指令 Cambricon有两个控制指令,跳转和条件分支。跳转指令通过立即数或 GPR指定偏移量,并将该值和程序计数器 (PC)相加。除了偏移量之外,条件分支指令还要指定条件(存储在 GPR 中),分支目标(PC + {偏移量} 或 PC +1)通过条件和零之间的比较来确定。
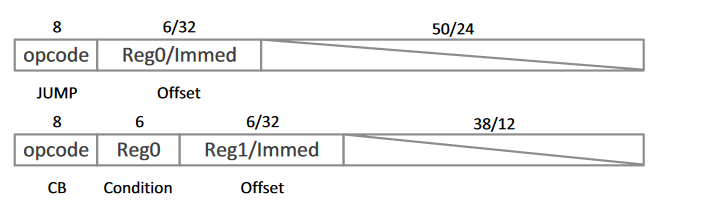
- 数据传输指令 Cambricon的数据传输指令支持可变数据大小,以便灵活地支持矩阵和向量计算/逻辑指令。具体来说,这些指令可以将可变大小的数据块(由数据传输指令中的数据宽度操作数指定)从主存储器加载/存储到片上Scratchpad Memory,或者在片上Scratchpad Memory和标量 GPR 之间移动数据。下图是向量加载指令 (VLOAD) ,可以将 V_size 大小的向量从主存储器加载到向量Scratchpad Memory; 其中,主存储器中的源地址是GPR中保存的基址和立即数之和。Vector STORE(VSTORE)、Matrix LOAD(MLOAD)和Matrix STORE(MSTORE)指令的格式与VLOAD相似。

- 矩阵-多向量指令 MMV(Matrix-Mult-Vector) 矩阵-多向量指令 (MMV里,Reg0 指定向量输出 (Vout_addr) 的scratchpad memory内存地址; Reg1 指定向量输出的大小 (Vout_size); Reg2、Reg3 和 Reg4 分别指定矩阵输入的基址 (Min_addr)、向量输入的基址 (Vin_addr) 和向量输入的大小。MMV指令可以支持任意尺度的矩阵向量乘法,只要所有输入和输出数据都可以同时保存在scratchpad memory中即可。使用专用的 MMV 指令计算 W x,而不是将其分解为多个向量点积,因为后一种方法需要额外的开销(例如,显式同步、对同一地址的并发读/写请求)才能在 M 的不同行向量之间复用输入向量 x。

- 向量-多矩阵指令(VMM) 反向传播(BP)算法的一个关键步骤是计算梯度向量,梯度向量可以表述为向量乘以矩阵。如果使用 MMV 指令实现,则需要一个额外的指令来实现矩阵转置。为了避免这种情况,Cambricon提供了一个向量-多矩阵指令(VMM),该指令直接适用于反向传播。VMM 指令与 MMV 指令具有相同的字段,但操作码除外。此外,在训练神经时,权重矩阵 W 通常需要使用 W = W + ηΔW 进行增量更新,其中 η 是学习率,ΔW 为两个向量的外积。Cambricon提供OuterProduct指令(OP)(输出为矩阵)、MatrixMult-Scalar(MMS)指令和Matrix-Add-Matrix(MAM)指令,协同执行权重更新。此外,Cambricon还提供矩阵减法矩阵 指令(MSM),以支持受限玻尔兹曼机 (RBM) 中的权重更新。
-
向量指令 除了矩阵指令,还需要向量指令;包括向量加法指令(VAV) ,向量指数指令 (VEXP) ,向量-除-向量指令 (VDV) ;Cambricon还提供Vector-Add-Scalar(VAS)指令,其中标量可以是立即数或由GPR指定。Cambricon还提供了一系列向量算术指令,如VectorMult-Vector(VMV)、Vector-Sub-Vector(VSV)和VectorLogarithm(VLOG)。在硬件加速器的设计过程中,不同超越函数相关的指令(例如对数、三角函数和反三角函数)可以使用CORDIC技术有效地重用相同的功能块(涉及加法、移位和表格查找操作)。寒武纪提供了一个专用的随机向量指令(RV),可以生成一个随机数向量,该向量服从区间[0,1]的均匀分布。给定均匀的随机向量,我们可以借助 Cambricon 中的向量算术指令和向量比较指令,使用 Ziggurat 算法进一步生成服从其他分布(例如高斯分布)的随机向量。Cambricon 支持使用 Vector-Greater-Than-Merge (VGTM) 指令进行最大池化操作。VGTM 指令通过比较输入向量 0 (Vin0) 和输入向量 1 (Vin1) 的相应元素来指定输出向量 (Vout) 的每个元素,即 Vout[i]=(Vin0[i] > Vin1[i])?Vin0[i] : Vin1[i]。

- 除了向量计算指令外,寒武纪还提供向量大于(VGT)、向量相等指令(VE)、向量和/或/非指令(VAND/VOR/VNOT)、标量比较和标量逻辑指令来处理分支条件,即计算上述条件分支(CB)指令的条件。
为了说明Cambricon指令集的用法,下面使用Cambricon 指令实现了三个简单但具有代表性的神经网络组件,即 MLP 前馈层、池化层和玻尔兹曼机 (BM) 层。为了简洁起见,省略了所有三个层的标量加载/存储指令,只列出了池化层的单个池化窗口(具有多个输入和输出特征图)的程序片段。
// $0: input size, $1: output size, $2: matrix size
// $3: input address, $4: weight address
// $5: bias address, $6: output address
// $7-$10: temp variable address
VLOAD $3, $0, #100 // load input vector from address (100)
MLOAD $4, $2, #300 // load weight matrix from address (300)
MMV $7, $1, $4, $3, $0 // Wx
VAV $8, $1, $7, $5 // tmp=Wx+b
VEXP $9, $1, $8 // exp(tmp)
VAS $10, $1, $9, #1 // 1+exp(tmp)
VDV $6, $1, $9, $10 // y=exp(tmp)/(1+exp(tmp))
VSTORE $6, $1, #200 // store output vector to address (200)
// $0: feature map size, $1: input data size,
// $2: output data size, $3: pooling window size ̢ 1
// $4: x-axis loop num, $5: y-axis loop num
// $6: input addr, $7: output addr
// $8: y-axis stride of input
VLOAD $6, $1, #100 // load input neurons from address (100)
SMOVE $5, $3 // init y
L0: SMOVE $4, $3 // init x
L1: VGTM $7, $0, $6, $7
// feature map m, output[m]=(input[x][y][m]>output[m])?
// input[x][y][m]:output[m]
SADD $6, $6, $0 // update input address
SADD $4, $4, #-1 // x-
CB #L1, $4 // if(x>0) goto L1
SADD $6, $6, $8 // update input address
SADD $5, $5, #-1 // y-
CB #L0, $5 // if(y>0) goto L0
VSTORE $7, $2, #200 // stroe output neurons to address (200)
// $0: visible vector size, $1: hidden vector size, $2: v-h matrix (W) size
// $3: h-h matrix (L) size, $4: visible vector address, $5: W address
// $6: L address, $7: bias address, $8: hidden vector address
// $9-$17: temp variable address
VLOAD $4, $0, #100 // load visible vector from address (100)
VLOAD $9, $1, #200 // load hidden vector from address (200)
MLOAD $5, $2, #300 // load W matrix from address (300)
MLOAD $6, $3, #400 // load L matrix from address (400)
MMV $10, $1, $5, $4, $0 // Wv
MMV $11, $1, $6, $9, $1 // Lh
VAV $12, $1, $10, $11 // Wv+Lh
VAV $13, $1, $12, $7 // tmp=Wv+Lh+b
VEXP $14, $1, $13 // exp(tmp)
VAS $15, $1, $14, #1 // 1+exp(tmp)
VDV $16, $1, $14, $15 // y=exp(tmp)/(1+exp(tmp))
RV $17, $1 // i, r[i] = random(0,1)
VGT $8, $1, $17, $16 // i, h[i] = (r[i]>y[i])?1:0
VSTORE $8, $1, #500 // store hidden vector to address (500)
参考文献
- DianNao项目—-智能计算系统官方网站 [WWW Document], n.d. URL https://novel.ict.ac.cn/diannao/
- Chen, T., Du, Z., Sun, N., n.d. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning.
- Chen, Y., Luo, T., Liu, S., Zhang, S., He, L., Wang, J., Li, L., Chen, T., Xu, Z., Sun, N., Temam, O., 2014. DaDianNao: A Machine-Learning Supercomputer, in: 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. Presented at the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), IEEE, Cambridge, United Kingdom, pp. 609–622. https://doi.org/10.1109/MICRO.2014.58
- Du, Z., Fasthuber, R., Chen, T., Ienne, P., Li, L., Luo, T., Feng, X., Chen, Y., Temam, O., 2015. ShiDianNao: shifting vision processing closer to the sensor, in: Proceedings of the 42nd Annual International Symposium on Computer Architecture. Presented at the ISCA ’15: The 42nd Annual International Symposium on Computer Architecture, ACM, Portland Oregon, pp. 92–104. https://doi.org/10.1145/2749469.2750389
- Liu, D., Chen, T., Liu, S., Zhou, J., Zhou, S., Teman, O., Feng, X., Zhou, X., Chen, Y., 2015. PuDianNao: A Polyvalent Machine Learning Accelerator, in: Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems. Presented at the ASPLOS ’15: Architectural Support for Programming Languages and Operating Systems, ACM, Istanbul Turkey, pp. 369–381. https://doi.org/10.1145/2694344.2694358
- Liu, S., Du, Z., Tao, J., Han, D., Luo, T., Xie, Y., Chen, Y., Chen, T., 2016. Cambricon: An Instruction Set Architecture for Neural Networks, in: 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA). Presented at the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), IEEE, Seoul, South Korea, pp. 393–405. https://doi.org/10.1109/ISCA.2016.42
- Zhang, S., Du, Z., Zhang, L., Lan, H., Liu, S., Li, L., Guo, Q., Chen, T., Chen, Y., 2016. Cambricon-X: An accelerator for sparse neural networks, in: 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). Presented at the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), IEEE, Taipei, Taiwan, pp. 1–12. https://doi.org/10.1109/MICRO.2016.7783723
- V. Kantabutra, “On hardware for computing exponential and trigonometric functions,” in IEEE Transactions on Computers, vol. 45, no. 3, pp. 328-339, March 1996, doi: 10.1109/12.485571. keywords: {Hardware;Read only memory;Adders;Polynomials;Arithmetic;Taylor series;Software algorithms;Approximation algorithms;Circuits;Throughput},