
前言
当下最火热的领域非人工智能莫属,而支撑这些应用的硬件则是GPGPU;在过去20年,NVIDIA的GPGPU借助摩尔定律的加持和自身架构特点,占据了并行计算领域绝大部分市场,让人难以望其项背;而最近几年随着摩尔定律逐步停滞,给了大家追赶的机会。那么,在这种情况下,梳理GPU的发展历程,了解其架构变迁背后的故事,可以更好地帮我们来应对不确定的未来。如果你也有下列问题:
- GPU是如何从图形处理单元变成通用计算的GPGPU的?
- NVIDIA是如何凭借Tesla架构,纵横并行计算江湖近20载?
- AMD又为何三易架构,从图形时代各领风骚到并行计算领域和当下人工智能时代节节败退?
- Interl又是如何三心二意,左右摇摆?
针对上述问题,本文首先通过回溯40年前图形处理硬件,到GPU概念的出现 ,说明硬件是如何随着应用的需求变化从专用硬件变成可编程处理器;然后通过NVIDIA和AMD的各自产品和架构上的迭代来展现从GPU到GPGPU的演进历史,也是图形处理从固定的流水线到统一处理流水线的变迁;最后结合NVIDIA和AMD在各自统一处理器架构上对HPC和AI应用的倾向上来陈述各自的选择。
本文组织结构如下:
- 第一节概述,简要介绍了近40年来图形处理硬件的发展,以及CUDA奠定的GPGPU一般编程模型;通过本节可以快速了解GPU和GPGPU出现的历史背景
- 第二节从NVIDIA第一个GPU产品GeForce 256开始,经过2.5节第一个GPGPU产品Tesla,最后以最新的Rubin产品和架构结束;通过本节可以完整的了解GPU到GPGPU,GPGPU到AI加速的完整的演变过程
- 第三节从AMD第一个统一处理器架构XBOX 360开始,到最新MI350X为止,展示AMD从Terascale,到GCN,然后CDNA的架构差异
- 第四节简要描述了Intel Ponte Vecchio 产品架构
- 第五节是Biren的产品一些信息
- 最后是本文写作过程一些参考文献
1. 概述
过去40多年的图形处理流水线总体上没有太多变化,大致遵循顶点处理,三角形生成,像素处理,光栅化等主要步骤,如下图所示:
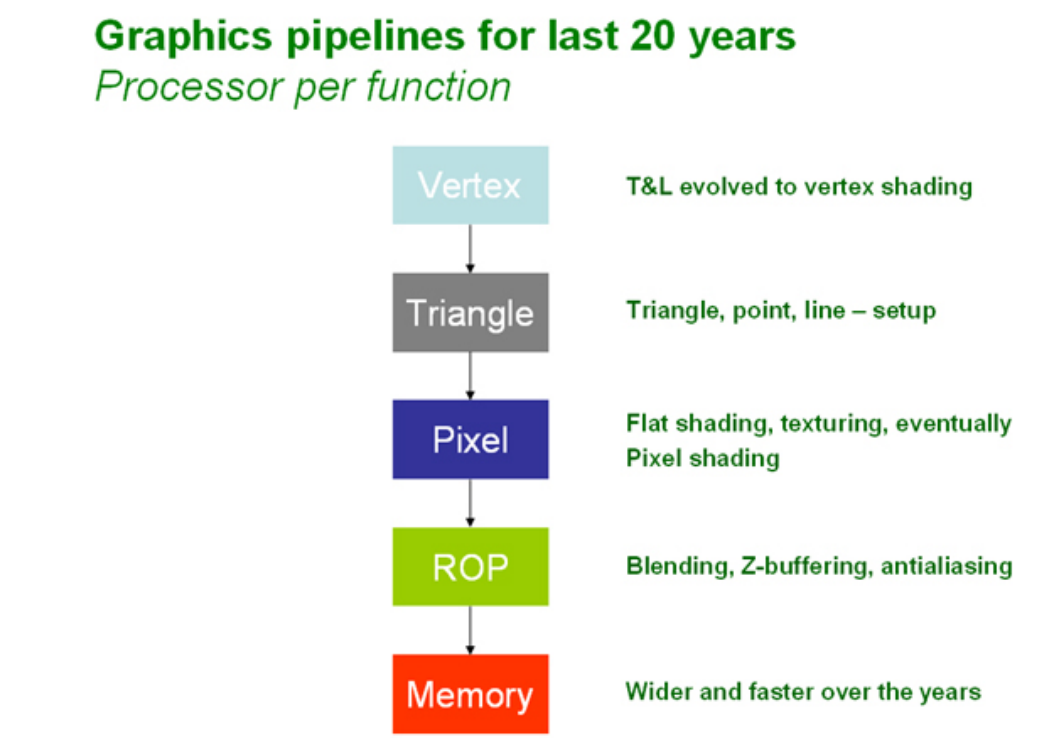
其中,顶点处理主要是做变换和光照处理,在变换与光照引擎(Transform & Lighting Engine) 中,变换是计算密集型的任务,用于将包含所有物体的3D场景,称为’世界空间’,转换为我们正在查看的’屏幕空间’。光照是3D流水线中的一个可选阶段,该阶段根据一个或多个光源计算物体的光照。光照和变换一样,也是计算密集型的任务。
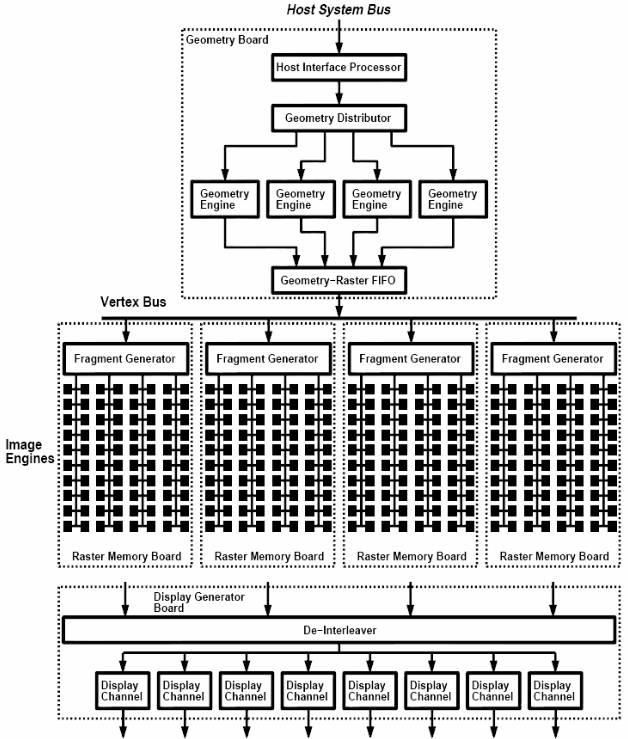
在20世纪90年代这些图形处理催生出了大量的芯片,专门用来处理图形流水线,下图展示了1997年SGI的 InfiniteReality InfiniteReality 的处理单元结构:
可以看到,当时的图形芯片本身集成度不高,不同的功能是由不同芯片组成的;但是总体的图形处理流水线是类似的。这时期还是图形处理芯片或者3D芯片,即图形数据从Host发送到图形芯片,经过固定的流水线处理之后输出到显示器。
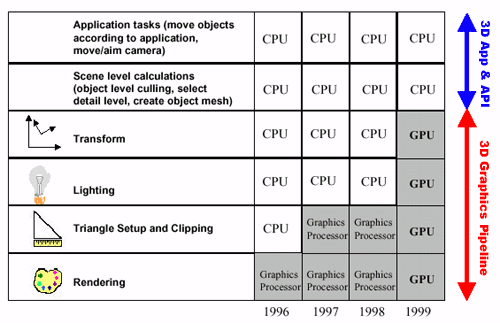
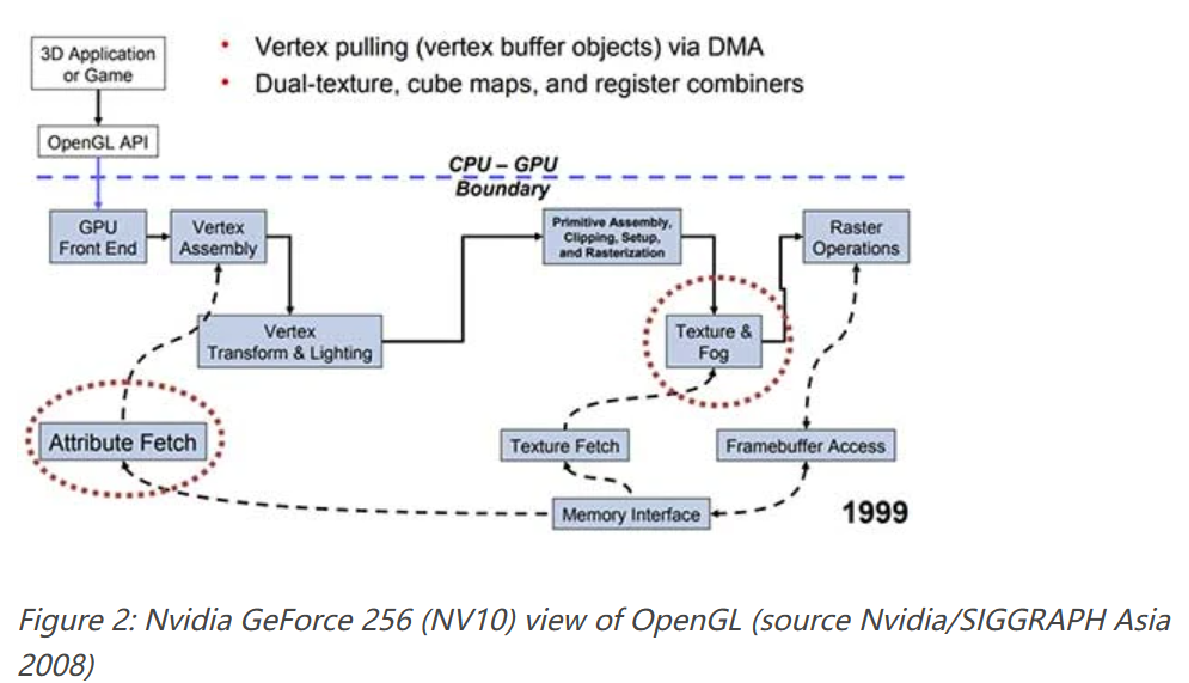
在20多年前,最开始图形芯片只负责图形的渲染,随后慢慢的变换与光照,三角形生成等也由图形芯片负责。因为这些操作都是计算密集型的,由CPU执行,给CPU带来了相当大的压力。其结果是,3D芯片常常需要等待CPU提供数据(例如,CPU限制的3D基准测试),而且游戏开发者不得不将自己限制在简单的3D世界中,因为过多的多边形使用会使CPU停顿。下表是从1996年到1999年间从图形处理芯片到GPU出现时CPU和图形芯片的分工变化:
 1999年,NVIDIA推出的GeForce 256,将之前由CPU处理的变换和光照用专用硬件实现;为了区别于之前的图形芯片,第一次采用了GPU这个名称。这个时候,GPU还是一个固定功能的图形处理器。
1999年,NVIDIA推出的GeForce 256,将之前由CPU处理的变换和光照用专用硬件实现;为了区别于之前的图形芯片,第一次采用了GPU这个名称。这个时候,GPU还是一个固定功能的图形处理器。
开发人员总是希望获得更大的灵活性,因此,固定功能着色器单元变成可编程的;
- 首先是顶点着色器变成可编程,这一时期典型代表是NVIDIA GeForce 3;
- 随后像素着色器也变成可编程,这一时期典型代表是NVIDIA GeForce 6800;
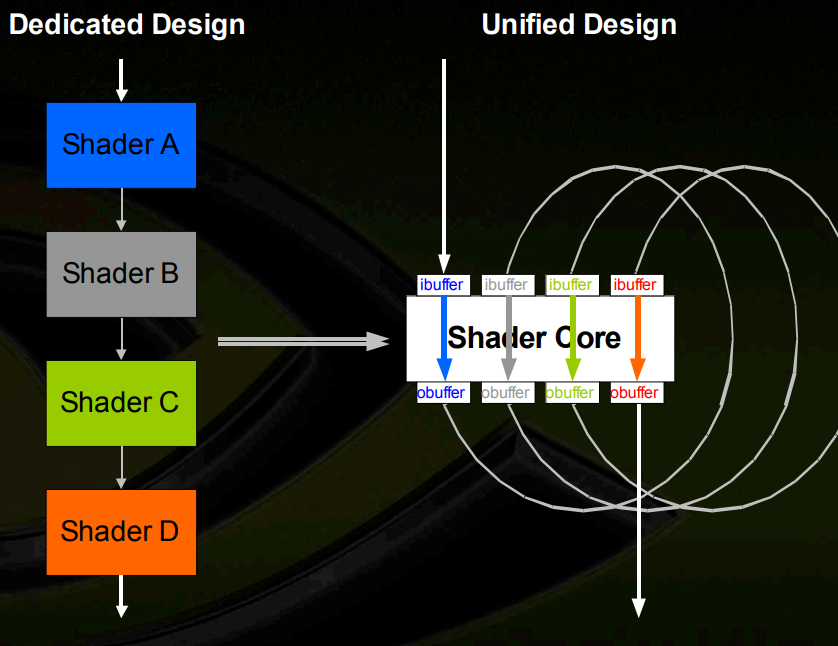
而不同工作负载对顶点处理器和像素处理器的需求也存在较大差异,所以NVIDIA GeForce 7800应运而生,调整了顶点着色器和像素着色器的数量;然后,即使同一个应用里不同阶段对顶点处理器和像素处理器的需求也存在较大差异;因此,顶点处理器和像素处理器也逐渐从不同的计算单元演进成相同的通用计算单元,包括计算,分支等指令,以及寄存器,加载和存储等功能单元, 典型产品是NVIDIA Tesla。

在固定功能的全流水线架构中,着色器阶段瓶颈会使整个流水线停滞;而这种新的架构被称为统一处理器,可以实现着色器级负载均衡。此时,GPU由专用的图形处理功能进化为了通用的计算单元,也就是GPGPU。
1.1 GPGPU架构和编程模型
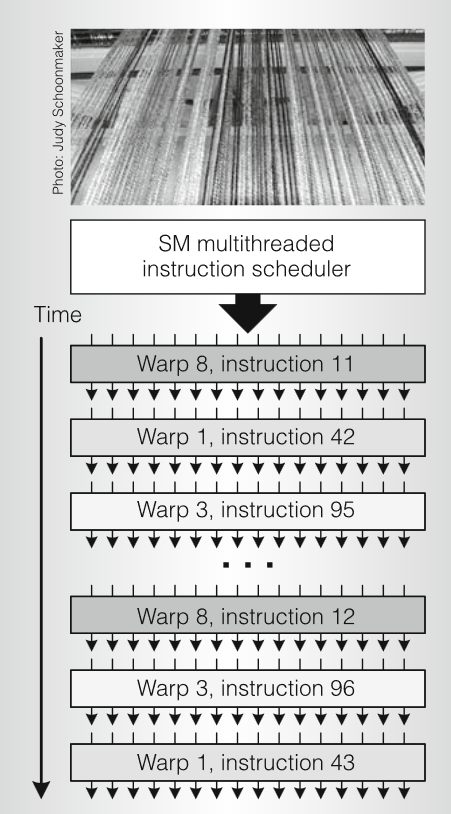
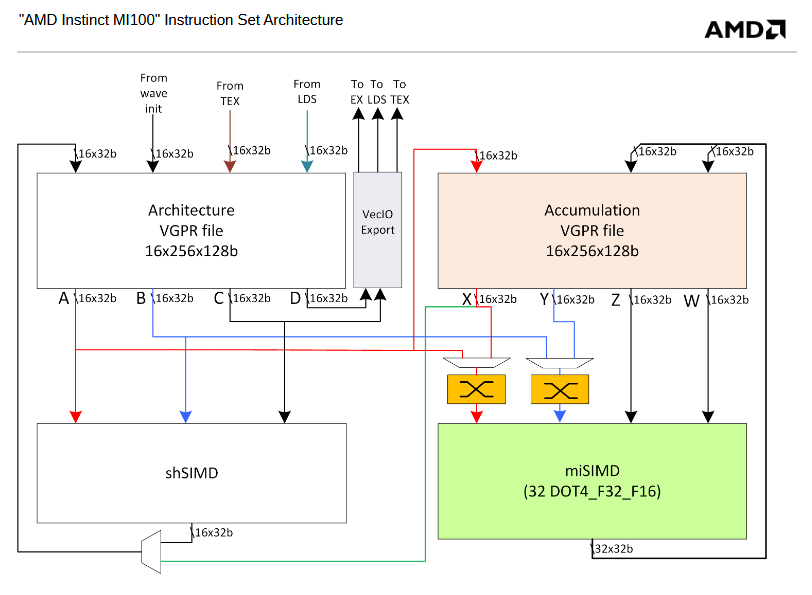
CUDA 提供了三个关键抽象 - 线程组的层次结构、共享内存和屏障同步 - 为层次结构中的一个线程提供适用传统 C 代码的清晰并行结构。 当主机 CPU 上的 CUDA 程序调用内核网格(kernel grid)时,CWD(计算工作分配单元compute work distribution unit)枚举网格块并将它们分发给可执行的 SM。线程块(thread block)的线程在一个 SM 上并发执行。当线程块结束时,CWD 单元会在空闲的SM上启动新的线程块。
以Tesla为例,一个SM 由 8 个标量 SP 核、2 个用于超越函数的 SFU(特殊功能单元)、1 个 MT IU(多线程指令单元)和片上共享存储器组成。SM 可以零开销在硬件中创建、管理和执行多达 768 个并发线程,可以同时执行多达 8 个 CUDA 线程块,受线程和内存资源的限制。SM 通过单个指令实现 CUDA syncthreads()屏障同步。快速屏障同步与轻量级线程创建和零开销线程调度一起有效地支持非常细粒度的并行性,允许创建一个新线程来计算每个顶点、像素和数据点。
SM 将每个线程映射到一个 SP 标量核,每个标量线程使用自己的指令地址和寄存器状态独立执行。SM SIMT 单元以 32 个并行线程(称为warp)为一组创建、管理、调度和执行线程。组成 SIMT warp的各个线程从同一程序地址一起开始,但可以自由地独立分支和执行。每个 SM 管理一个warp 池, 支持 24 个warp ,每个 warp 32 个线程,总共 768 个线程。
发射指令时,SIMT 单元都会选择一个准备执行的warp,并向warp的活动线程发出下一条指令。一个 warp 一次执行一条公共指令,因此当 warp 的所有 32 个线程都执行相同路径时,可以实现全部效率。如果 warp 的线程通过依赖于数据的条件分支而发散,则 warp 会按顺序执行所采用的每个分支路径,禁用不在该路径上的线程,当所有路径完成时,线程会收敛回相同的执行路径。分支发散仅发生在warp内;不同的 Warp 独立执行,无论它们执行的是公共代码路径还是不连贯的代码路径。因此,与上一代 GPU 相比,Tesla架构的 GPU 在分支代码上的效率和灵活性要高得多,因为它们的 32 线程的warp比之前 GPU 的 SIMD(单指令多数据)宽度窄得多。
SIMT 架构类似于 单个指令控制多个处理单元的SIMD 向量结构。一个关键的区别在于,SIMD 向量结构向软件公开 SIMD 宽度,而 SIMT 指令指定单个线程的执行和分支行为。与 SIMD 向量机相比,SIMT 使程序员能够为独立的标量线程编写线程级并行代码,并为协调线程(coordinated thread)编写数据并行代码。为了正确起见,程序员基本上可以忽略 SIMT 行为;但是,通过注意代码很少需要 Warp 中的线程来发散,可以实现显著的性能改进。在实践中,这类似于缓存行在传统代码中的作用:在设计正确性时可以安全地忽略缓存行大小,但在设计最佳性能时必须在代码结构中考虑缓存行大小。
另一方面,向量架构需要软件将数据合并到向量中,并手动管理发散。
线程的变量通常保留在寄存器中。SM的16KB 共享内存具有非常低的访问延迟和高带宽,类似于 L1 缓存;它包含活动线程块的每个块的 CUDA __shared__变量。SM 提供加载/存储指令以访问 GPU 外部 DRAM 中的 CUDA __device__变量。当地址位于同一块中并满足对齐标准时,它将同一 warp 中并行线程的单个访问合并为更少的内存块访问。由于全局内存延迟可能高达数百个处理器时钟,因此当线程块必须多次访问数据时,CUDA 程序会将数据复制到共享内存。
Tesla 加载/存储内存指令使用整数字节寻址来利用传统的编译器代码优化。每个 SM 中的大线程数,以及对许多并发加载请求的支持,有助于覆盖外部 DRAM 的加载到使用延迟。最新的Tesla架构 GPU 还提供原子读-改-写内存指令,便于并行缩减和并行数据结构管理。
程序通过调用 CUDA 运行时(例如 cudaMalloc() 和 cudaFree())来管理Kernel可见的全局内存空间。Kernel可以在物理上独立的设备上执行,就像在 GPU 上运行Kernel时一样。因此,应用程序必须使用 cudaMemcpy() 在分配的空间和主机系统内存之间复制数据。
线程块(thread block)的并发线程表示细粒度数据和线程并行性。网格(grid)的独立线程块表示粗粒度数据并行性。独立网格表示粗粒度任务并行性。内核(kernel)只是层次结构中一个线程的 C 代码。
2. NVIDIA
2.1 GeForce 256 ( NV10 )
1999年,Nvidia推出GeForce 256,在此之前,基本上所有显卡都被称为“图形加速器”或简称为“显卡”。GeForce 256中加入了几项新功能,包括之前由CPU执行的Transform & Lighting(变换和照明)处理。为了和之前图形加速器做区别,NVIDIA将其称为“GPU”。GeForce 256采用220 nm工艺,工作频率为 120 MHz,支持32 - 64MB的SDRAM。下图展示了GeForce 256物理版图:
 GeForce 256包含一个固定功能的32位浮点变换和照明处理器以及一个固定功能的整数像素片元流水线,使用OpenGL和Microsoft DX7 API进行编程。
GeForce 256包含一个固定功能的32位浮点变换和照明处理器以及一个固定功能的整数像素片元流水线,使用OpenGL和Microsoft DX7 API进行编程。
2.2 GeForce 3 ( NV20 )
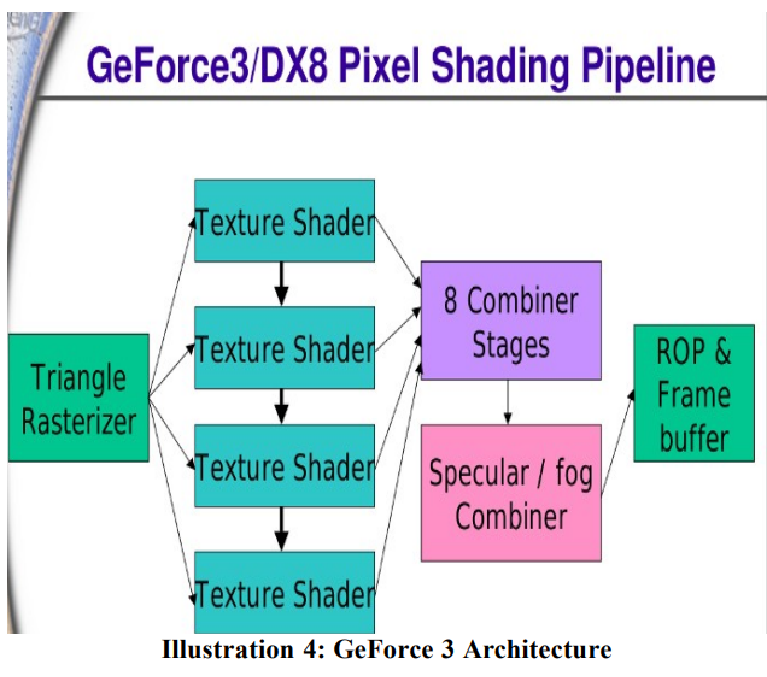
2001 年,GeForce 3发布,采用150 nm工艺,包含 6000 万个晶体管,频率最高可达 250 MHz; 并引入了一个新的内存子系统,称为“Lightspeed Memory Architecture”(LMA),旨在压缩 Z 缓冲区并减少对内存带宽的需求。支持64MB DDR,提供7.4GB/s存储带宽。计算单元包括一个顶点着色器,4个片元着色器。
GeForce 3 是第一款采用可编程顶点处理器来执行顶点着色器的GPU,还有可配置的 32 位浮点片元流水线,使用 DX8.5 和 OpenGL 编程。
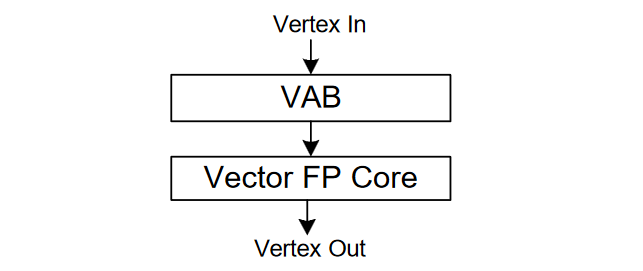
顶点处理器Vertex Processor
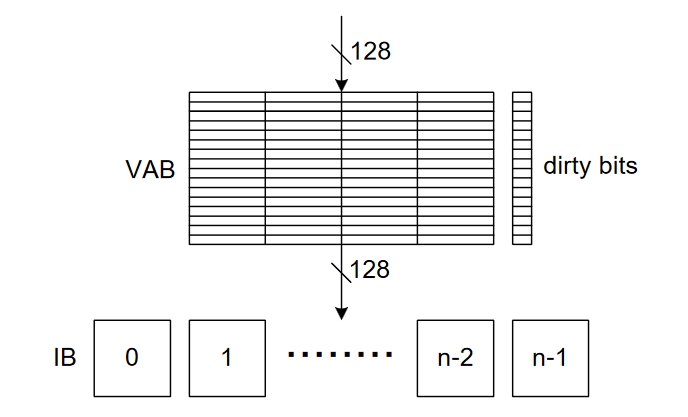
顶点处理器分为两个主要模块:顶点属性缓冲区(VAB)和浮点核心,如下图所示:
 VAB 数据会写到IB(Input Buffer),这些缓冲以round-robin方式给浮点内核提供数据。 VAB有一个dirty 位,当同一缓冲区数据写到IB时,只需要更新修改过的属性。对地址 0写时,会触发顶点的传输,类似固定功能模式下的顶点位置。
VAB 数据会写到IB(Input Buffer),这些缓冲以round-robin方式给浮点内核提供数据。 VAB有一个dirty 位,当同一缓冲区数据写到IB时,只需要更新修改过的属性。对地址 0写时,会触发顶点的传输,类似固定功能模式下的顶点位置。
 浮点内核是一个多线程向量处理器,可以对四个浮点数据进行操作。顶点数据从输入缓冲器读取,执行完之后写入到输出缓冲区 (OB)。向量和特殊函数单元的延迟相等,并且使用多个顶点线程来隐藏延迟。SIMD 向量单元负责 MOV、MUL、ADD、MAD、DP3、DP4、DST、MIN、MAX、SLT 和 SGE 操作。特殊功能单元负责 RCP、RSQ、LOG、EXP 和 LIT 操作。
浮点内核是一个多线程向量处理器,可以对四个浮点数据进行操作。顶点数据从输入缓冲器读取,执行完之后写入到输出缓冲区 (OB)。向量和特殊函数单元的延迟相等,并且使用多个顶点线程来隐藏延迟。SIMD 向量单元负责 MOV、MUL、ADD、MAD、DP3、DP4、DST、MIN、MAX、SLT 和 SGE 操作。特殊功能单元负责 RCP、RSQ、LOG、EXP 和 LIT 操作。

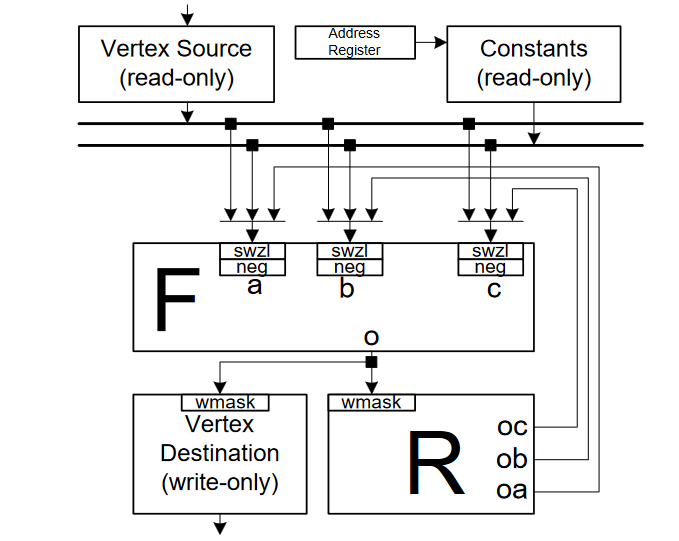
编程模型
顶点处理器架构如下所示,当前顶点属性在输入(源)寄存器中可用,处理后的顶点写入输出(目标)寄存器。constant bank保存变换和光照参数,寄存器文件 (R) 保存临时结果。功能单元 (F) 实现指令集。
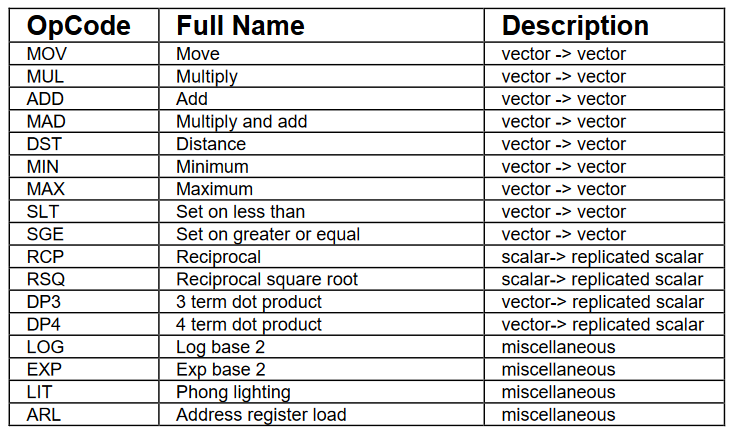
 指令集包括向量操作、标量操作和其他操作等17 个操作,具体如下表所示:
指令集包括向量操作、标量操作和其他操作等17 个操作,具体如下表所示:
2.3 GeForce 6800(NV40)
2003 年,NVIDIA发布GeForce 6800,采用130nm工艺,面积287 mm²,有 2.22 亿个晶体管, TDP 100 W;16 个像素超标量流水线(每个流水线上有一个像素着色器、TMU 和 ROP),支持Microsoft DirectX 9.0和Vertex Shader 3.0;6 个顶点着色器,支持Pixel Shader 3.0和 32 位浮点精度。256 位内存总线,支持最高512MB 的 GDDR3。下图展示了GeForce 6800的架构框图:
 GeForce 6800的工作流程从上到下,从六个相同的可编程顶点处理器开始。顶点阶段的结果将按照原始应用程序指定的顺序重新组合,以发送到三角形设置和栅格化单元。对于每个基元,光栅器会识别组成像素片元并将其发送到片元处理器(fragment processor)。16 个可编程片元处理器并行处理。每个线程接收来自光栅器的 (x, y) 地址和插值输入。最后,片元处理器的颜色和深度结果通过交叉开关分配给 16 个固定功能像素混合单元,这些单元执行帧缓冲操作,例如颜色混合、抗锯齿以及模板测试和更新。任何片元处理器结果可以发送到任何帧缓冲区位置。
GeForce 6800的工作流程从上到下,从六个相同的可编程顶点处理器开始。顶点阶段的结果将按照原始应用程序指定的顺序重新组合,以发送到三角形设置和栅格化单元。对于每个基元,光栅器会识别组成像素片元并将其发送到片元处理器(fragment processor)。16 个可编程片元处理器并行处理。每个线程接收来自光栅器的 (x, y) 地址和插值输入。最后,片元处理器的颜色和深度结果通过交叉开关分配给 16 个固定功能像素混合单元,这些单元执行帧缓冲操作,例如颜色混合、抗锯齿以及模板测试和更新。任何片元处理器结果可以发送到任何帧缓冲区位置。
顶点处理器
每个顶点处理器包括一个向量乘加单元、一个标量特殊功能单元和一个纹理单元。向量单元可以执行四个IEEE单精度乘法、加法或乘加运算,以及内积、最大值、最小值等。特殊功能单元执行超越运算,如正弦、余弦、对数和指数。下图展示了顶点处理器架构框图:
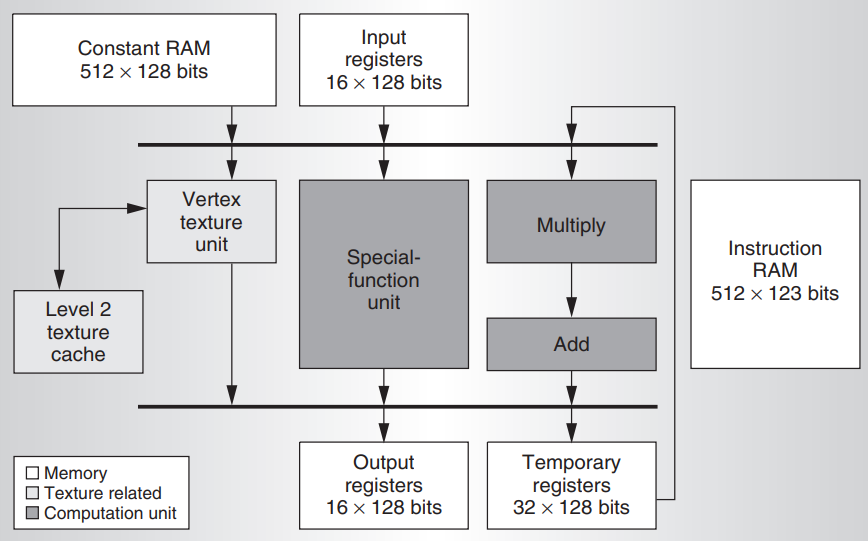
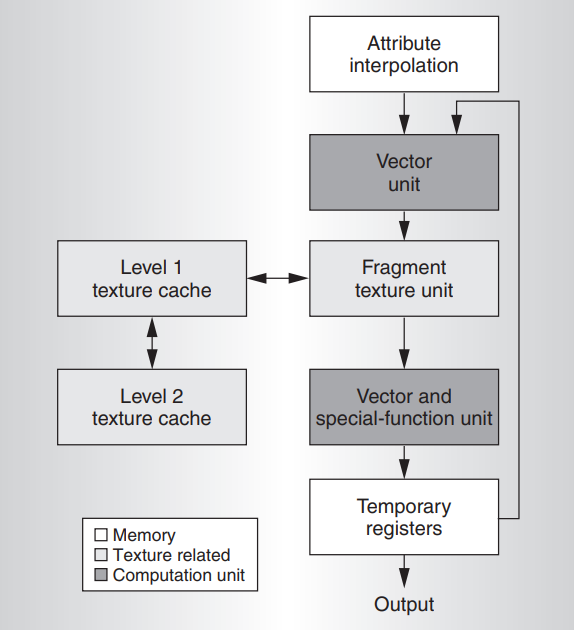
片元处理器
片元处理器在三角形上对属性进行平滑的插值。使用这些插值处理过的输入属性,片元程序使用数学和纹理查找指令来计算输出颜色。GeForce 6800 片元处理器可以执行 16 位或 32 位浮点精度(FP16 和 FP32)的运算。片元处理器的输入是位置、颜色、深度、fog和 10 个通用的 4 × FP32 属性。处理器将其输出发送到最多四个渲染目标缓冲区。与顶点处理器一样,片元处理器是通用的,也有类似的常量、临时寄存器资源和分支功能。下图展示了片元处理器架构框图:
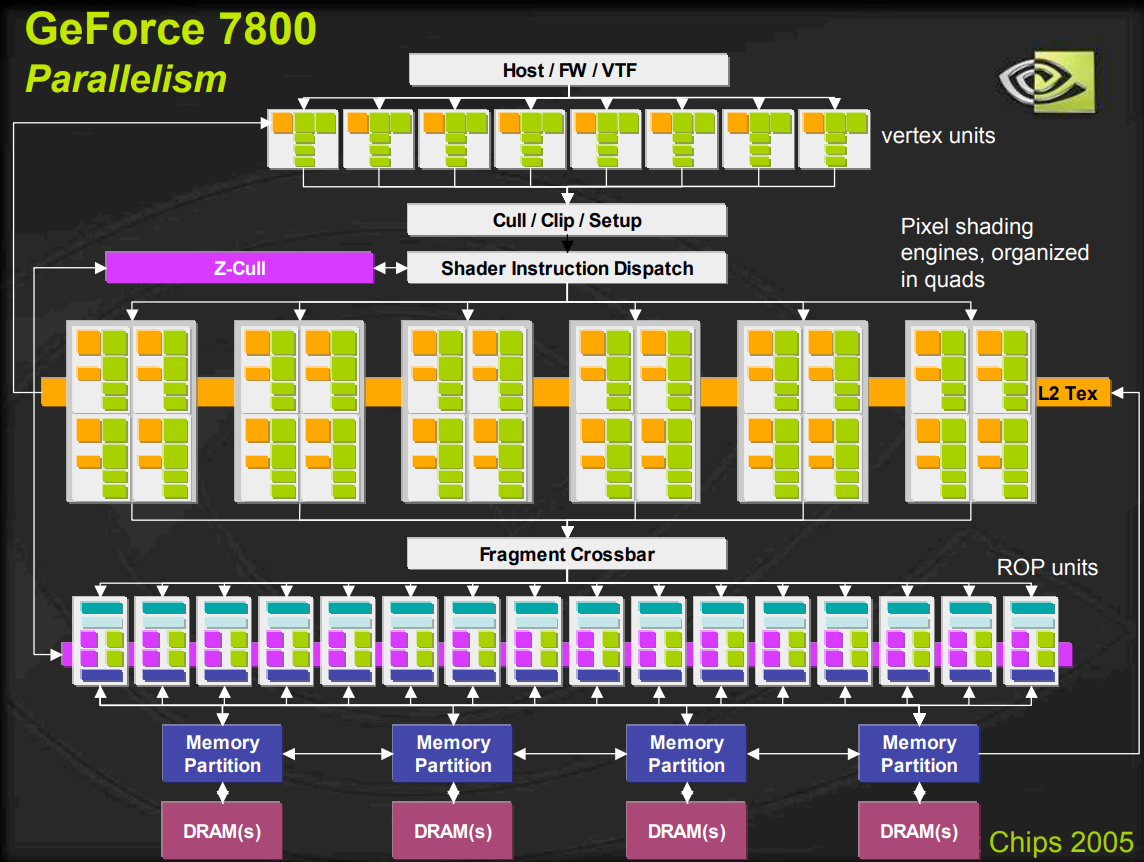
2.4 GeForce 7800(G70)
2005年,GeForce 7800采用110 nm 技术, 面积333 mm²,3.02亿晶体管,工作频率为430 MHz;包含 24 个像素流水线,24 个 TMU,8 个顶点着色器和 16 个 ROP。内存位宽256 位,支持 256MB 的 GDDR3,频率 600 MHz (1.2 GHz DDR)。下图展示了GeForce 7800的架构框图:
2.5 Tesla
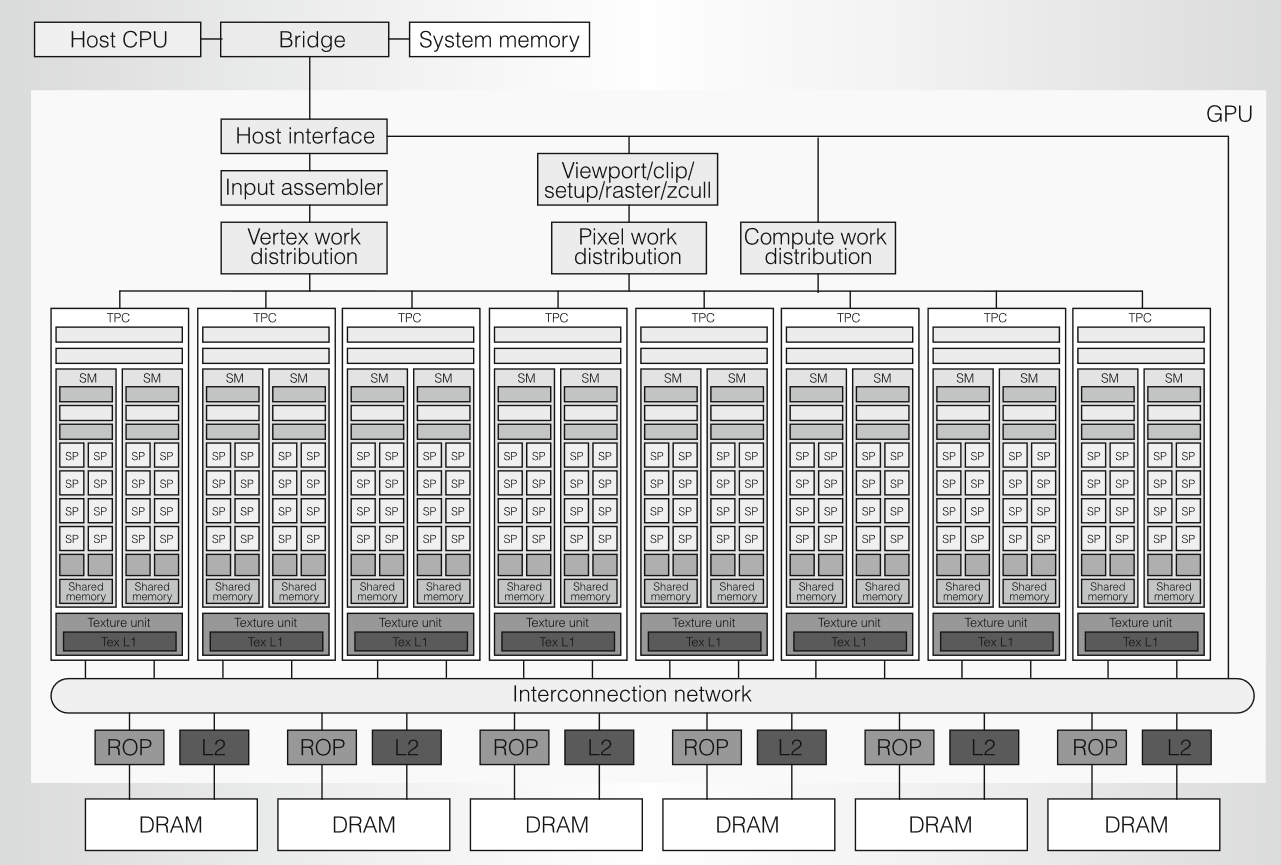
2006年,NVIDIA推出Tesla架构的GeForce 8800,采用台积电 90nm工艺,有6.81 亿个晶体管,面积470 mm2,工作频率1.5GHz,典型功率为 150 W; 包含16 个 SM,每个SM有8个SP核,一共128 个 SP 核; 支持最大12,288 个处理器线程; 峰值性能576 Gflops; 采用384位宽的内存接口,支持768 MB GDDR3,内存频率1.08GHz,提供104 GB/s 峰值带宽。下图展示了GeForce 8800的物理版图:
 Tesla 架构基于可扩展的处理器阵列。下图展示了有 128 个流处理器SP (streaming-processor) 内核的 GeForce 8800 GPU 的框图,这些内核被组织成 16 个流式多处理器SM (streaming multiprocessor),分布在 8 个称为纹理/处理器集群 (TPC)的独立的处理单元中。
Tesla 架构基于可扩展的处理器阵列。下图展示了有 128 个流处理器SP (streaming-processor) 内核的 GeForce 8800 GPU 的框图,这些内核被组织成 16 个流式多处理器SM (streaming multiprocessor),分布在 8 个称为纹理/处理器集群 (TPC)的独立的处理单元中。
TPC
SPA 中的每个 TPC 大致相当于以前架构中的四个像素单元,每个 TPC 都包含一个几何控制器(geometry controller)、一个 SM 控制器 (SMC)、两个流式多处理器 (SM) 和一个纹理单元。SM里的SP是标量 ALU ,代替之前架构的向量单元,因为着色器程序变得越来越长,标量越来越大,向量架构很难有效利用;下图展示了TPC的架构框图:
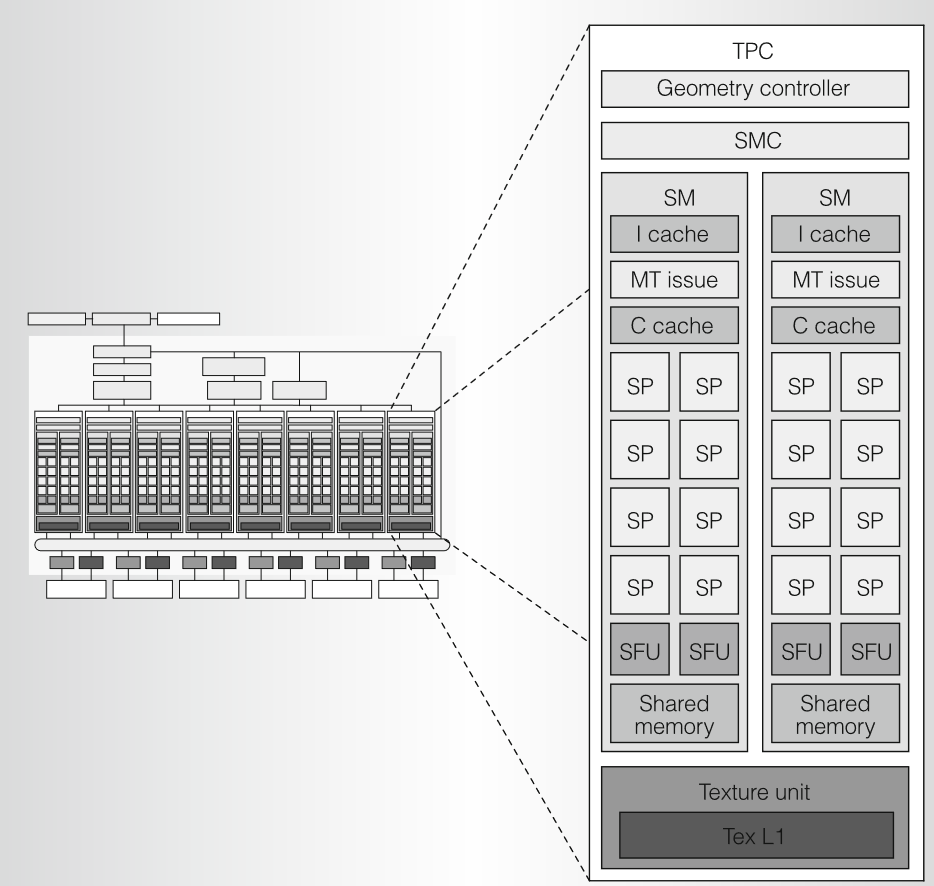
几何控制器Geometry controller
几何控制器通过引导 TPC 中的所有基元和顶点属性以及拓扑流,将逻辑图形顶点流水线映射到物理 SM 上;几何控制器管理专用的片上输入和输出顶点属性存储,并根据需要转发内容。DX10 有两个阶段处理顶点和基元:顶点着色器和几何着色器。
- 顶点着色器独立于其他顶点处理一个顶点的属性。典型的操作包括位置空间变换以及颜色和纹理坐标生成。
- 几何着色器在顶点着色器之后,处理整个基元及其顶点。典型的操作包括用于模板阴影生成的边缘拉伸和立方体贴图纹理生成。几何着色器输出图元,用于裁剪、视图转换和光栅化为像素片段等后期阶段。
SM(Streaming multiprocessor)
SM 由 8 个流处理器 (SP) 核、2 个特殊功能单元 (SFU)、1 个多线程取指和发射单元 (MT Issue)、1 个指令缓存、1 个只读常量缓存和 16 KB 读/写共享存储组成。每个 SP 内核都有一个标量乘加 (MAD) 单元。SM 将其两个 SFU 单元用于超越函数和属性插值,即从定义基元的顶点属性插值像素属性。每个SFU还包含4个浮点乘法器。SM 使用 TPC 里的纹理单元作为第三个执行单元,并使用 SMC 和 ROP 单元来实现外部内存加载、存储和原子访问。为了在运行多个不同的程序时有效地并行执行数百个线程,SM 是硬件多线程的,支持24 个 SIMD 线程束,每个线程束32个线程,可以在硬件中管理和执行多达 768 个并发线程,且调度开销为零。每个 SM 线程都有自己的线程执行状态,可以执行独立的代码路径。计算程序的并发线程可以使用单个 SM 指令在屏障处同步。
SM 的 SIMT 多线程指令单元以 32 个并行线程(称为 warps)为一组创建、管理、调度和执行。组成 SIMT warp 的各个线程属于同一类型,并且在同一程序地址处一起开始,但它们可以自由地独立分支和执行。在每个指令发出时,SIMT 多线程指令单元选择一个准备执行的 warp,并向该 warp 的活跃线程发出下一条指令。SIMT 指令同步广播到warp的活跃并行线程;由于独立的分支或预测,单个线程可能处于非活跃状态。SM 将 warp 线程映射到 SP 内核,每个线程以自己的指令地址和寄存器状态独立执行。当 warp 的所有 32 个线程都采用相同的执行路径时,SIMT 处理器实现了全部效率和性能。
如果 warp 的线程通过数据依赖的条件分支发散,则 warp 会按顺序执行每个分支路径,禁用不在该路径上的线程;当所有路径完成时,线程将重新聚合到原始执行路径。SM 使用分支同步堆栈来管理发散和聚合的独立线程。分支发散仅发生在 warp内;不同的 Warp 独立执行,无论它们执行的是公共代码路径还是不相交的代码路径。SIMD 指令一起控制多个数据通道的向量,并向软件公开向量宽度,而 SIMT 指令单独控制一个线程的执行和分支行为。
SIMT warp调度。SIMT 在 32 个线程之间有效地共享 SM 取指和发射单元。SM warp 调度器以处理器时钟速率(1.5GHz)的一半运行,在每个周期中,从 24 个warp中选择一个来执行 SIMT warp指令。发出的 warp 指令作为两组 16 个线程在四个处理器周期内执行。SP核和SFU单元独立执行指令,调度程序通过交替在它们之间发出指令可以使两者都处于完全占用状态。为不同warp程序和程序类型的动态组合实现零开销warp调度是一个具有挑战性的设计问题。记分牌对每个周期的warp发射进行限定,指令调度器对所有就绪的warp进行优先级排序,并选择优先级最高的warp发射。优先级考虑了 Warp 类型、指令类型和 SM 中执行的所有 Warp 的“公平性”。
SM 指令。Tesla SM 执行标量指令,与以前的 GPU 向量指令架构不同。着色器程序变得越来越长,标量越来越多,甚至越来越难以完全占用先前架构中四个向量单元中的两个。以前的架构采用向量打包(结合子向量)以提高效率,但这使硬件调度器和编译器变得复杂。标量指令更简单且易于编译。纹理指令仍然使用向量,采用源坐标向量并返回过滤后的颜色向量。高级图形和计算语言编译器生成中间指令,例如 DX10 向量指令或 PTX 标量指令,然后对其进行优化并转换为二进制 GPU 指令。优化器可轻松将 DX10 向量指令扩展为多个 Tesla SM 标量指令。PTX标量指令可以一对一的优化为Tesla SM标量指令。PTX 为编译器提供稳定的目标 ISA,并提供与不断发展的GPU二进制指令集架构的兼容性。由于中间语言使用虚拟寄存器,因此优化器会分析数据依赖关系并分配实际寄存器,消除死代码,在可行的情况下将指令折叠,并优化 SIMT 分支发散点和聚合点。
指令集体系结构。Tesla SM 是基于寄存器的指令集,包括浮点、整数、位、转换、超越函数、流程控制、内存加载/存储和纹理操作。SP 核是 SM 中的主要处理器,执行基本的浮点运算,包括加法、乘法和乘加;还实现了各种整数运算、比较和转换运算。SFU支持超越函数和平面属性插值的计算。
- 浮点运算和整数运算包括加法、乘法运算、乘法加法、最小值、最大值、比较运算以及整数和浮点数之间的转换。浮点指令为取反和绝对值提供源操作数修饰符
- 超越函数指令包括余弦、正弦、指数、对数、倒数和平方根
- 属性插值指令可高效生成像素属性
- 按位运算包括左移、右移、逻辑运算符和移动
- 控制流包括分支、调用、返回、陷阱和屏障同步。浮点和整数指令还可以为每个线程设置零、负数、进位和溢出的状态标志,线程程序可以使用这些标志进行条件分支
- 内存访问指令。为了支持计算和 C/C++ 语言需求,Tesla SM 除了图形纹理获取和像素输出外,还实现了内存加载/存储指令。内存加载/存储指令使用整数字节和寄存器加偏移地址寻址,以利用传统的编译器优化代码。对于计算,加载/存储指令可以访问三个读/写内存空间:
- 用于每个线程、私有、临时数据的N 个本地内存(在外部 DRAM 中实现)
- 用于低延迟访问同一 SM 中协作线程共享数据的N 个共享内存
- 用于计算应用程序的所有线程共享的数据的N 个全局内存(在外部 DRAM 中实现)
SM控制器SMC。SMC 控制多个 SM,对共享纹理单元、加载/存储路径和 I/O 路径进行仲裁。SMC 同时处理三个图形工作负载:顶点、几何图形和像素。它将这些输入类型中的每个都打包到warp中,启动着色器处理,并分解结果。每种输入类型都有独立的 I/O 路径,SMC 负责它们之间的负载平衡。SMC 支持基于驱动程序建议的分配、当前分配和额外资源分配的相对的静态和动态负载均衡。
纹理单元。纹理单元每个周期处理一组四个线程(顶点、几何、像素或计算)。纹理指令的源操作数是纹理坐标,输出是筛选的样本,通常为四分量 (RGBA) 颜色。纹理是通过 SMC 连接的 SM 外部的一个独立单元。发射的 SM 线程可以继续执行,直到有数据依赖关系才停止。每个纹理单元都有 4 个纹理地址生成器和 8 个过滤器单元。
与独立执行并行着色器线程的图形编程模型不同,并行计算编程模型要求并行线程之间同步、通信、共享数据和协作才能有效地得到计算结果。为了管理大量可以协作的并发线程,Tesla 计算架构引入了协作线程阵列CTA (cooperative thread array),在 CUDA 术语中称为线程块。CTA 是并发线程阵列,这些线程执行相同的线程程序,可以协作计算结果。CTA 由 1 到 512 个并发线程组成,每个线程都有一个唯一的线程 ID (TID),编号为 0 到 m。程序员在线程中声明 1D、2D 或 3D CTA 维度,TID 有一维、二维或三维索引。CTA 的线程可以在全局或共享内存中共享数据,并且可以使用屏障指令同步。CTA 线程程序使用其 TID 来选择工作和索引共享数据数组。多维 TID 可以消除索引数组时的整数除法和余数运算。每个 SM 最多可同时执行 8 个 CTA,具体取决于 CTA 资源需求。程序员或编译器声明 CTA 程序所需的线程数、寄存器数、共享内存数和屏障数。当 SM 有足够的可用资源时,SMC 会创建 CTA 并为每个线程分配 TID 编号。SM 以 32 个并行线程的 SIMT warp同时执行 CTA 线程。
 并行粒度。下图显示了 GPU 计算模型中的并行粒度级别和并行读/写内存共享的级别。这三个并行粒度级别是:
并行粒度。下图显示了 GPU 计算模型中的并行粒度级别和并行读/写内存共享的级别。这三个并行粒度级别是:
- Thread线程 计算由其 TID 选择的结果元素
- CTA 计算按其 CTA ID 选择的结果块
- Grid网格 计算多个结果块,顺序网格计算顺序相关的应用程序
三个并行读/写内存共享的级别是:
- local memory本地存储 每个执行线程都有一个专用的本地内存,用于寄存器、堆栈帧和可寻址临时变量
- shared memory共享存储 每个执行 CTA 都有一个共享内存,用于访问同一 CTA 中线程共享的数据
- global memory全局存储 网格在全局内存中通信和共享大型数据集
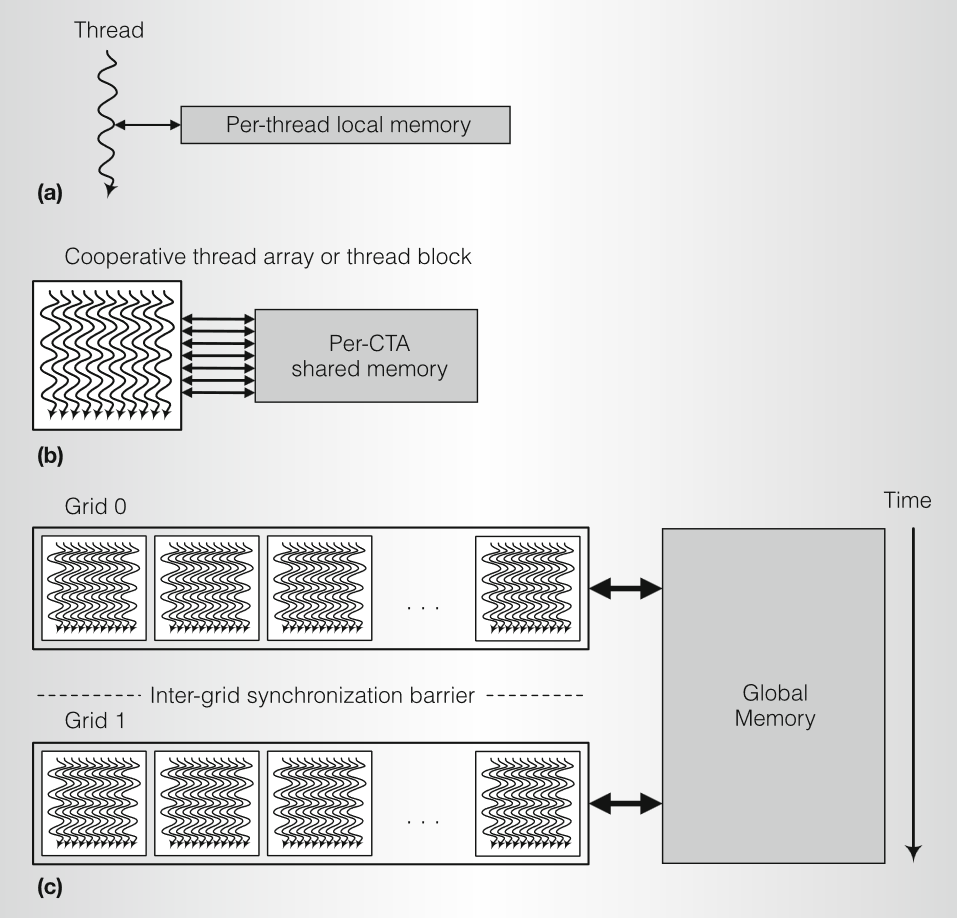 CTA 中通信的线程使用快速屏障同步指令等待对共享内存或全局内存的写入完成,然后再读取 CTA 中其他线程写入的数据。加载/存储内存系统使用宽松的内存顺序,该顺序保证从同一线程到同一地址的读取和写入的顺序,以及屏障同步指令协调的 CTA 线程的顺序。顺序依赖的网格使用网格之间的全局网格间同步屏障来确保全局读/写顺序
CTA 中通信的线程使用快速屏障同步指令等待对共享内存或全局内存的写入完成,然后再读取 CTA 中其他线程写入的数据。加载/存储内存系统使用宽松的内存顺序,该顺序保证从同一线程到同一地址的读取和写入的顺序,以及屏障同步指令协调的 CTA 线程的顺序。顺序依赖的网格使用网格之间的全局网格间同步屏障来确保全局读/写顺序
CUDA 编程模型
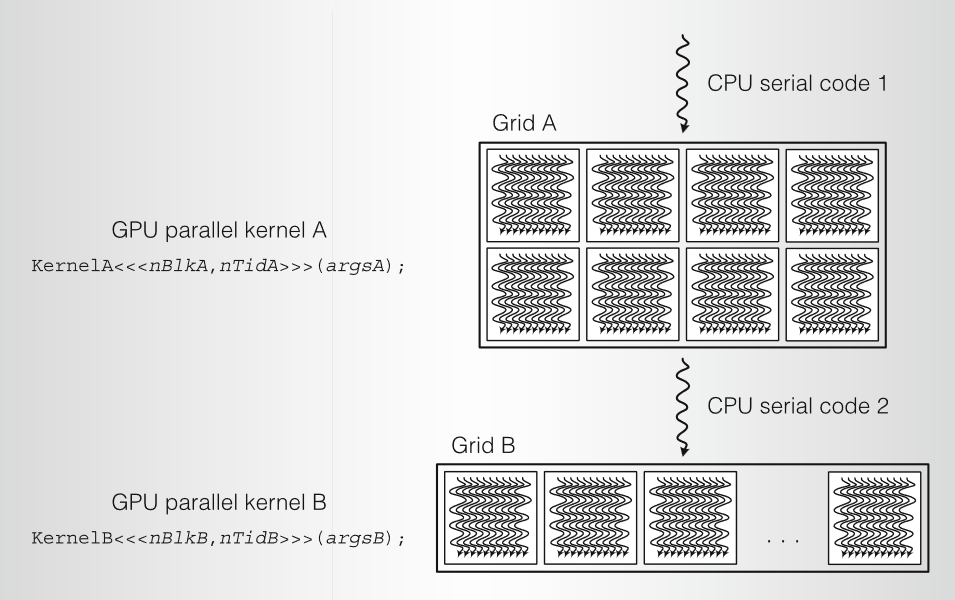
CUDA 是 C 和 C++ 编程语言的最小扩展。程序员编写一个调用并行核函数的串行程序,并行核函数可以是简单的函数,也可以是完整的程序。CUDA 程序在 CPU 上执行串行代码,并在 GPU 上的以并行线程方式执行并行核函数。如前所述,程序员将这些线程组织到线程块和网格的层次结构中。(CUDA 线程块是 GPU CTA)。下图显示了一个 CUDA 程序在异构 CPU-GPU 系统上执行一系列并行核函数。KernelA 和 KernelB 作为 nBlkA 和 nBlkB 线程块 (CTA) 的网格在 GPU 上执行,每个 CTA 实例化 nTidA 和 nTidB 个线程。CUDA 编译器 nvcc 编译包含串行 CPU 代码和并行 GPU 内核代码的 C/C++程序。CUDA 运行时 API 将 GPU 作为具有自己的内存系统的协处理器。CUDA 编程模型在风格上类似于单程序多数据SPMD (single-program multiple-data) 软件模型,它显式地表达并行性,并且每个核函数在固定数量的线程上执行。但是,CUDA 比大多数 SPMD 实现更灵活,因为每个核函数调用都会动态创建一个新网格,其中包含正确数量的线程块和线程。CUDA 使用声明说明符关键字扩展 C/C++:
__global__用于核函数入口__device__用于全局变量__shared__用于共享内存变量
CUDA 核函数只是一个顺序线程的 C 函数。内置变量 threadIdx.{x, y, z} 和块 Idx.{x, y, z} ,提供线程块 (CTA) 中的线程 ID,而块 Idx 提供网格内的 CTA ID。扩展函数调用语法 kernel<<<nBlocks,nThreads>>>(args); 在 nBlock 网格上调用并行核函数,其中每个块实例化 nThreads 并发线程,args 是函数 kernel() 的普通参数。
__global__ void KernelFunc(...);
__shared__ int SharedVar;
KernelFunc<<< 500, 128 >>>(...);
// Explicit GPU memory allocation
cudaMalloc()
cudaFree()
// Memory copy from host to device, etc
cudaMemcpy()
cudaMemcpy2D()
2.6 Fermi
2010年, NVIDIA推出Ferimi架构GF100,采用台积电 40nm 工艺, 有 30 亿晶体管,支持384位的GDDR5内存接口。下图展示了GF100的物理规划图:

Fermi实现了IEEE 754-2008,并显著提高了双精度性能,并且为了提高大规模 GPU 计算的可行性和可靠性,内存使用纠错码 (ECC) 保护、采用64 位统一寻址、缓存内存层次结构以及针对 C、Cpp、Fortran、OpenCL 和 DirectCompute 的指令。为了说明 GPU 计算架构,下图显示了配置了 16 个SM的第三代 Fermi 计算架构:
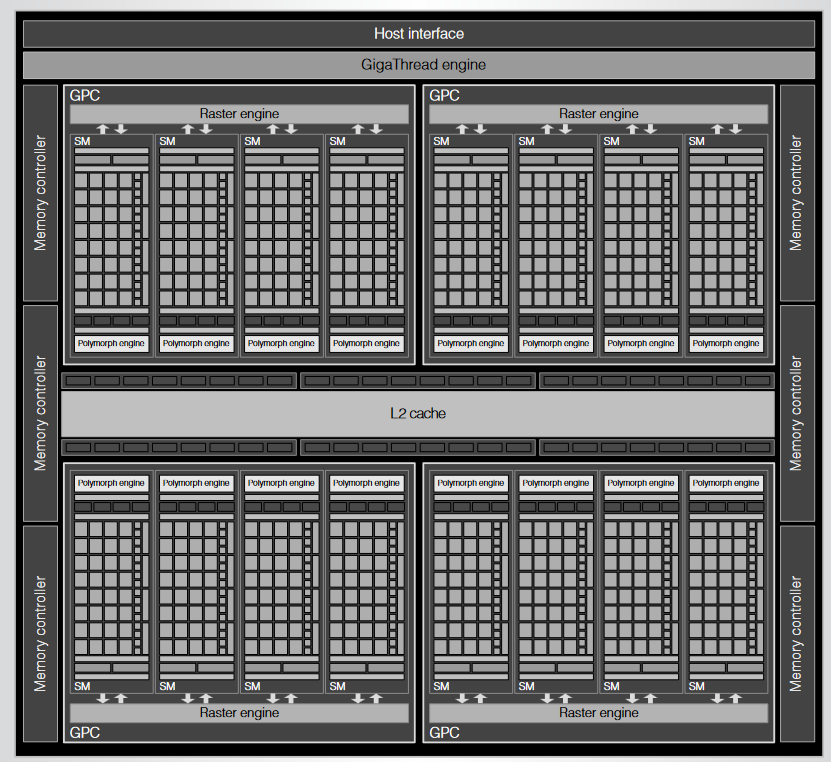 每个SM有 32 个 CUDA 核,总共 512 个。GigaThread 工作调度器将 CUDA 线程块分发给可用的SM,动态平衡 GPU 上的计算工作负载,并在适当的时候并行运行多个核函数。SM调度和执行 CUDA 线程块和单个线程。每个SM可执行多达 1,536 个并发线程,来掩藏DRAM 内存加载的长延迟。为了平衡了其并行计算能力,GPU使用专门的并行内存。Fermi GPU 有 6 个高速 GDDR5 DRAM 接口,每个接口 64 位。其 40 位地址可处理高达 1 TB 的地址空间。
每个SM有 32 个 CUDA 核,总共 512 个。GigaThread 工作调度器将 CUDA 线程块分发给可用的SM,动态平衡 GPU 上的计算工作负载,并在适当的时候并行运行多个核函数。SM调度和执行 CUDA 线程块和单个线程。每个SM可执行多达 1,536 个并发线程,来掩藏DRAM 内存加载的长延迟。为了平衡了其并行计算能力,GPU使用专门的并行内存。Fermi GPU 有 6 个高速 GDDR5 DRAM 接口,每个接口 64 位。其 40 位地址可处理高达 1 TB 的地址空间。
SM
SM执行单元包括 32 个 CUDA 处理器核、16 个加载/存储单元和 4 个特殊功能单元 (SFU)。64 KB 的可配置的共享存储/L1 缓存、128 KB 寄存器文件、指令缓存以及两个多线程 warp 调度器和指令分发单元。SM实现了对 1,536 个并发线程零开销多线程和线程调度。为了有效地管理和执行这些单独的线程,SM采用了第一个统一计算 GPU 中引入的单指令多线程 (SIMT) 架构。 SIMT 指令逻辑在称为 warps 的 32 个并行线程组中创建、管理、调度和执行并发线程。
CUDA线程块包括一个或多个warp。每个 Fermi SM都有两个 warp 调度器和两个分发单元,每个分发单元选择一个 warp 并将指令分发到 16 个 CUDA 核、16 个加载/存储单元或 4 个 SFU 。由于 warp 独立执行,因此SM可以向适当的 CUDA 核、加载/存储单元和 SFU发射两个 warp 指令。
为了支持 C、CPP 和标准单线程编程语言,每个SM线程都是独立的,有私有寄存器、条件码和预测、线程私有内存和堆栈帧、指令地址和线程执行状态。SIMT 指令控制单个线程的执行,包括算术、内存访问以及分支和控制流指令。
 CUDA 核每个时钟可以执行一个标量浮点或整数指令。SM有 32 个CUDA 核,每个时钟可以执行32 个算术线程指令。整数单元实现32位精度标量整数运算,包括32位乘法和乘加运算,并支持64位整数运算。Fermi整数单元增加了位域插入和提取、位反转和计数功能。Fermi CUDA 核浮点单元实现了 IEEE 754-2008 浮点运算标准,用于 32 位单精度和 64 位双精度结果,包括融合乘加 (FMA) 指令。FMA 通过在中间乘积和加法中保持完全精度,然后将最终总和四舍五入以形成结果,从而在不损失精度的情况下计算 D = A * B + C。
CUDA 核每个时钟可以执行一个标量浮点或整数指令。SM有 32 个CUDA 核,每个时钟可以执行32 个算术线程指令。整数单元实现32位精度标量整数运算,包括32位乘法和乘加运算,并支持64位整数运算。Fermi整数单元增加了位域插入和提取、位反转和计数功能。Fermi CUDA 核浮点单元实现了 IEEE 754-2008 浮点运算标准,用于 32 位单精度和 64 位双精度结果,包括融合乘加 (FMA) 指令。FMA 通过在中间乘积和加法中保持完全精度,然后将最终总和四舍五入以形成结果,从而在不损失精度的情况下计算 D = A * B + C。
内存结构
Fermi引入了一个用于加载、存储和原子访问的并行的缓存内存层次结构。SM的加载/存储单元执行加载、存储和原子内存访问指令。32 个活动线程的warp提供 32 个单独的字节地址的指令访问内存。加载/存储单元将 32 个单独的线程访问合并为最少数量的内存块访问。Fermi 引入了可配置容量的 L1 缓存,以帮助不可预测或不规则的内存访问,以及可配置容量共享内存。每个SM有 64 KB 的片上存储,可配置为 48 KB 共享存储和 16 KB L1 缓存,或 16 KB 共享存储和 48 KB L1 缓存。
所有SM共享768 KB 统一L2缓存。L2 缓存与 6 个 64 位 DRAM 接口和 PCIe 接口连接,PCIe 接口与主机 CPU、系统内存和 PCIe 设备连接。L2可以缓存通过PCIe接口访问的DRAM内存位置和系统内存页。统一的 L2 缓存负责来自SM的加载、存储、原子和纹理指令,以及来自 L1 缓存的请求,并填充SM指令缓存和统一数据缓存。
2.7 Kepler
2012年,NVIDIA 发布Kepler 架构,GK110 GPU采用台积电的 28 纳米工艺制造,面积 561 mm²,晶体管数量为 70.8 亿个。GK110物理版图如下所示:

GK110 包括5个GPC,15 个 SMX 单元和 6 个 64 位内存控制器,
 Kepler相对上一代,主要增加下列功能:
Kepler相对上一代,主要增加下列功能:
- 动态并行性(Dynamic Parallelism) 增加了 GPU 生成新任务、同步结果以及通过专用的硬件加速路径控制该任务调度的功能,所有这些都不涉及 CPU。通过在程序执行过程中提供灵活性,适应并行数量和形式,程序员可以利用更多的并行性,更有效地利用 GPU。此功能允许结构化程度较低、更复杂的任务轻松有效地运行,从而使应用程序的大部分内容能够完全在 GPU 上运行。Fermi在kernel启动时要知道问题的规模和参数,所有工作都是从主机 CPU 启动的,将运行到完成,并将结果返回给 CPU。在 Kepler 中,任何kernel都可以启动另一个kernel,并且可以创建必要的流、事件并管理处理额外工作所需的依赖项,而无需主机 CPU 交互。
- Hyper-Q Fermi支持从不同流启动16 路并发,但最终这些流在同一个硬件工作队列中多路复用。这会导致错误的流内依赖关系,要求一个流中的依赖kernel完成,然后才能执行其他流中的其他kernel。虽然可以通过使用广度优先的启动顺序在一定程度上缓解,但随着项目复杂性的增加,越来越难以有效管理。Kepler 通过其 Hyper-Q 改进了此功能。Hyper-Q 允许 32 个硬件管理连接( Fermi 提供的单个连接),增加主机和 GPU 中 CUDA 工作分发器 (CWD) 逻辑之间的连接总数(工作队列)。Hyper-Q 允许从多个 CUDA 流、多个消息传递接口 (MPI) 进程,甚至从进程中的多个线程进行连接。以前遇到跨任务错误串行化从而限制 GPU 利用率的应用程序可以在不更改任何现有代码的情况下将性能提高多达 32 倍。每个 CUDA 流都在自己的硬件工作队列中进行管理,优化了流间依赖关系,一个流中的操作将不再阻塞其他流,使流可以并发执行,而无需专门定制启动顺序以消除可能的错误依赖。在基于 MPI 的并行计算机系统中Hyper-Q 具有显著优势。传统的基于 MPI 的算法通常在多核 CPU 系统上运行,分配给每个 MPI 进程的工作量会相应地缩放。这可能会导致单个 MPI 进程的工作量不足,无法完全占用 GPU。虽然多个 MPI 进程可以共享一个 GPU,但这些进程可能会因错误的依赖关系而成为瓶颈。Hyper-Q 消除了这些错误的依赖关系,大大提高了 MPI 进程之间 GPU 共享的效率
- 网格管理单元(Grid Management Unit) Kepler 引入的新功能,例如 CUDA 内核能够通过动态并行直接在 GPU 上启动工作,这要求 Kepler 中的 CPU 到 GPU 工作流程提供比 Fermi 设计更多的功能。在 Fermi 上,一个线程块网格将由 CPU 启动,从运行到完成,通过 CUDA 工作分配器CWD (CUDA Work Distributor)创建从主机到 SM 的简单单向工作流。Kepler 允许 GPU 有效地管理 CPU 和 CUDA 创建的工作负载,从而改进了 CPU 到 GPU 的工作流程。Kepler可以像 Fermi 一样从 CPU 启动网格,但 CUDA 也可以在 Kepler SMX 单元中以编程方式创建新的网格。为了管理 CUDA 创建的网格和主机发起的网格,Kepler 中引入了一个新的网格管理单元GMU(Grid Management Unit)。该控制单元管理传递到 CWD 以发送到 SMX 单元执行的网格并确定其优先级。Kepler的CWD中保存已经准备好调度的网格,最多调度32个活动网格,这是Fermi CWD容量的两倍。Kepler CWD 通过双向链路与 GMU 通信,允许 GMU 暂停新网格的调度,并保留待处理和暂停的网格,直到需要。GMU 还与 Kepler SMX 单元直接连接,以允许通过动态并行在 GPU 上启动额外工作的网格并将新工作发送回 GMU,以便进行优先级排序和调度。如果调度额外工作负载的内核暂停,GMU 将使其保持非活动状态,直到相关工作完成
- NVIDIA GPUDirect GPUDirect使位于网络上的不同服务器中的 GPU 能够无需经过 CPU的内存直接交换数据。GPUDirect 中的 RDMA 功能允许第三方设备(如 SSD、NIC 和 IB 适配器)直接访问同一系统中多个 GPU 上的内存,从而显著降低到GPU 内存的MPI发送和接收消息的延迟,并且减少了对系统内存带宽的需求,释放了 GPU DMA 引擎供其他 CUDA 任务使用
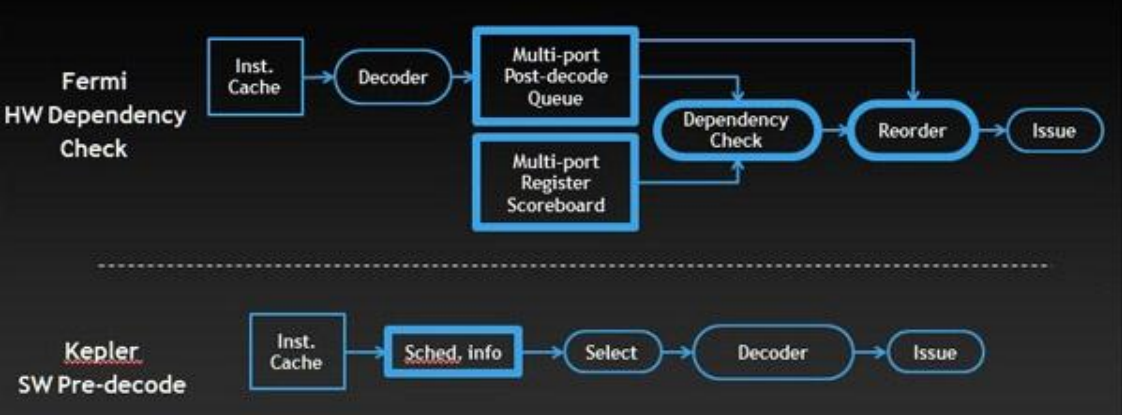
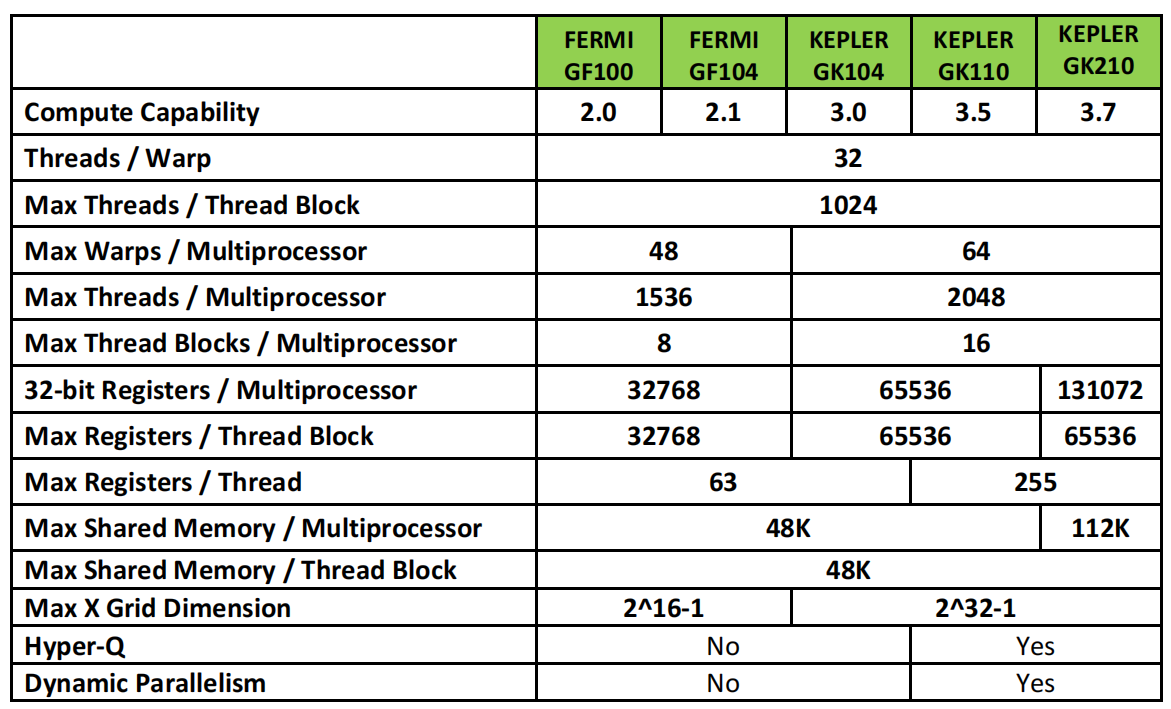
下表列出了Fermi和Kepler GPU的计算能力的对比:
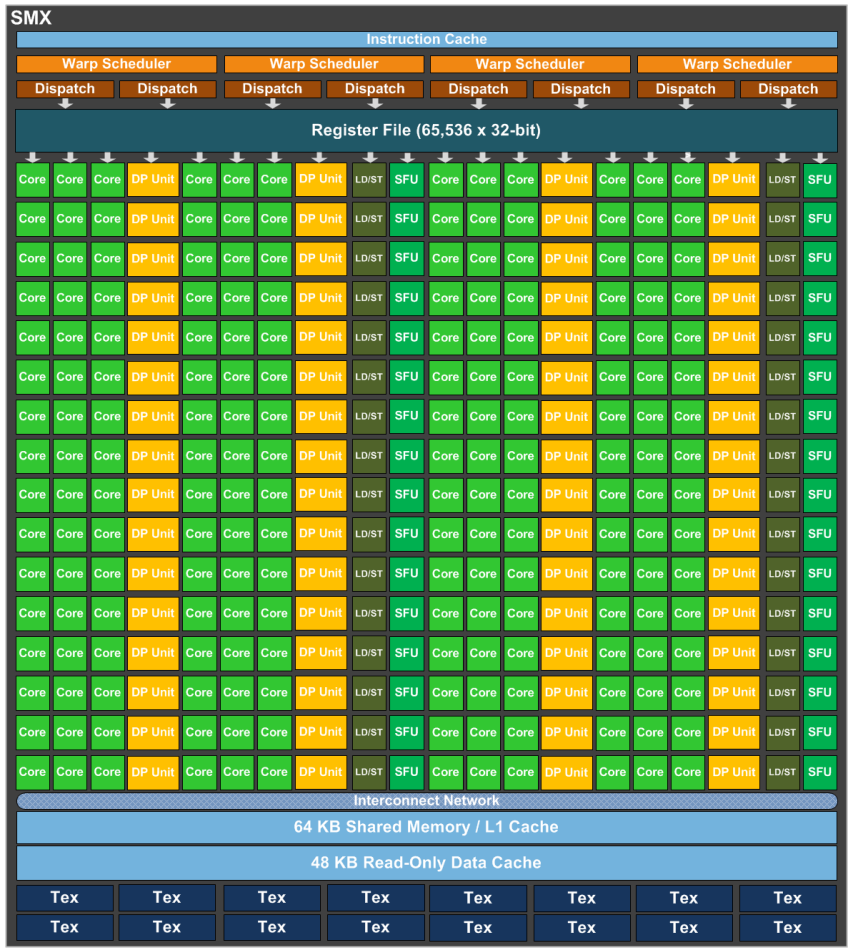
Streaming Multiprocessor (SMX)
SMX包含192 个单精度 CUDA 核、64 个双精度单元、32 个特殊功能单元 (SFU) 和 32 个加载/存储单元 (LD/ST)。
 每个CUDA核有完整流水线的浮点和整数算术逻辑单元。SMX 单元中的计算核使用 GPU 主时钟,而不是 2x 着色器时钟。2x 着色器时钟是在 G80 Tesla 架构 GPU 中引入的,并用于所有后续的 Tesla 和 Fermi 架构 GPU。以更高的时钟速率运行执行单元允许芯片以更少的执行单元实现给定的目标吞吐量,这本质上是一种面积优化,但更快的时钟逻辑更耗电。
每个CUDA核有完整流水线的浮点和整数算术逻辑单元。SMX 单元中的计算核使用 GPU 主时钟,而不是 2x 着色器时钟。2x 着色器时钟是在 G80 Tesla 架构 GPU 中引入的,并用于所有后续的 Tesla 和 Fermi 架构 GPU。以更高的时钟速率运行执行单元允许芯片以更少的执行单元实现给定的目标吞吐量,这本质上是一种面积优化,但更快的时钟逻辑更耗电。
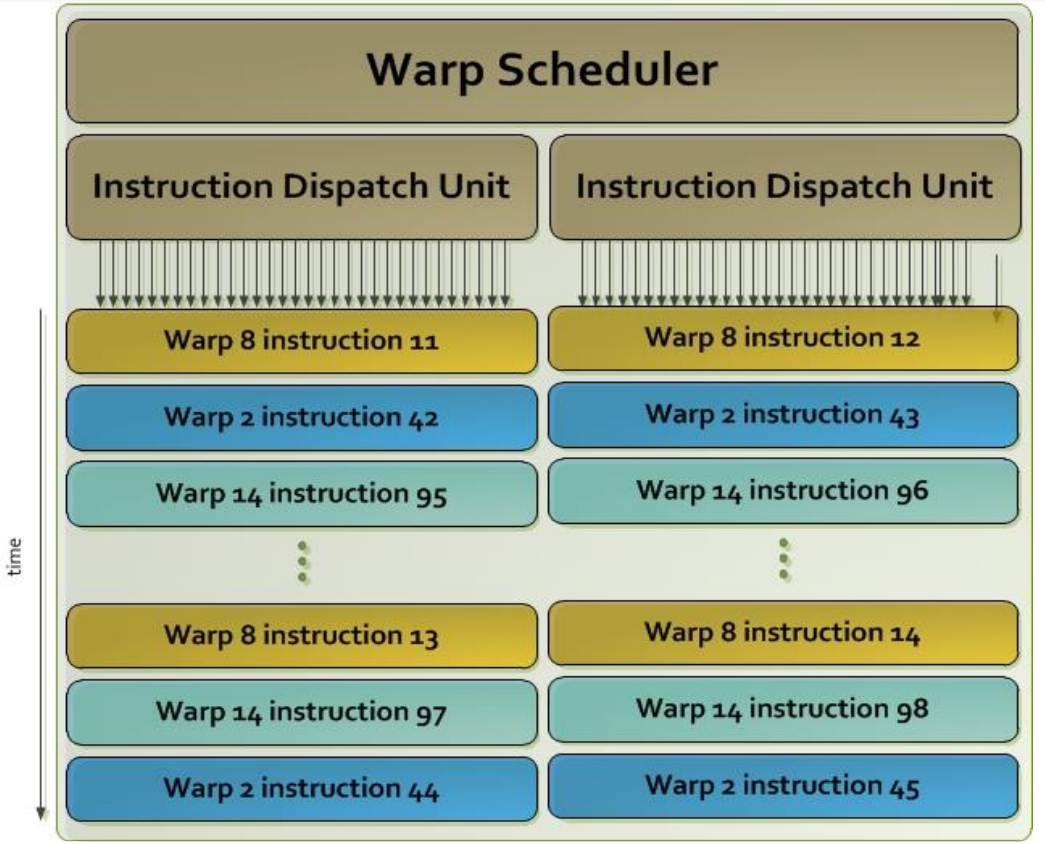
SMX 以 32 个并行线程组作为一个warp来调度。每个 SMX 有 4 个 warp 调度器和 8 个指令分发单元,允许同时发射和执行 4 个 warp。4 个 warp 调度器每周期选择选择四个warp,每个warp分发两个独立的指令。Fermi不支持双精度指令与其他指令配对,但是Kepler允许双精度指令与其他指令配对。
 Kelper和Fermi的调度器都包含类似的硬件单元来处理调度功能,包括:
a) 用于纹理和加载等长延迟操作的寄存器记分板
b) warp间调度决策,用于在符合条件的候选者中选择最优的warp
c) 用于线程块级调度的GigaThread 引擎
Kelper和Fermi的调度器都包含类似的硬件单元来处理调度功能,包括:
a) 用于纹理和加载等长延迟操作的寄存器记分板
b) warp间调度决策,用于在符合条件的候选者中选择最优的warp
c) 用于线程块级调度的GigaThread 引擎
然而,Fermi的调度器还包含一个复杂的硬件阶段,以防止数据路径本身的数据冒险。多端口寄存器记分板跟踪任何尚未准备好有效数据的寄存器,依赖关系检查器模块根据记分板分析大量完全解码的warp指令的寄存器使用情况,以确定哪些符合发射条件。对于 Kepler,这些信息都是确定的(计算流水线延迟是不变的),因此编译器可以预先确定指令何时准备好发出,并在指令本身中提供这些信息。因此可以用一个简单的硬件模块替换几个复杂且功耗高的模块;该模块提取预先确定的延迟信息,并在warp间调度时使用这些信息来屏蔽warp。
在GK110中,一个线程可以访问的寄存器数量增加了四倍,每个线程可以访问多达255个寄存器。
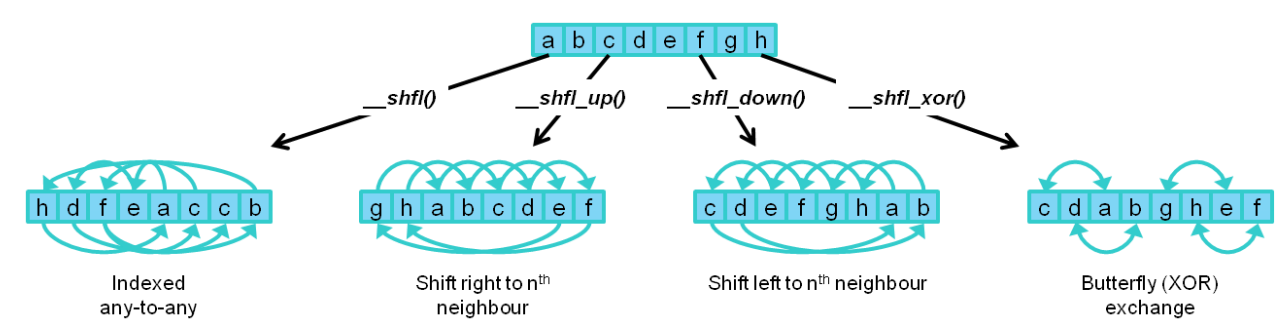
为了进一步提高性能,Kepler 实现了一个新的 Shuffle 指令,允许 warp 中的线程共享数据。之前,warp中的线程需要单独的存储和加载操作才能通过共享内存传递数据。使用 Shuffle 指令,warp中的线程可以以任何可以想象的排列方式从warp中的其他线程读取值。Shuffle 支持任意索引引用 - 即从任何其他线程读取任何线程。有用的随机排序子集,包括下一个线程(向上或向下偏移固定量)和warp中线程之间的异或“蝴蝶”样式排列,也可作为 CUDA 内部函数使用。与共享内存相比,Shuffle 存储和加载操作只需一步即可执行。Shuffle 还可以减少每个线程块所需的共享内存量,因为在 warp 级别交换的数据永远不需要放在共享内存中。
 原子内存操作在并行编程中非常重要,支持并发线程对共享数据结构正确执行读-修改-写操作。原子操作(如 add、min、max 和 compare-and-swap)的读取、修改和写入操作的执行不能被其他线程中断。原子内存操作广泛用于并行排序、reduction和并行数据结构,而无需串行化线程执行的锁。与Fermi相比,Kepler GK110/210上的全局内存原子操作的吞吐量提高了 9 倍。Kepler GK110 还扩展了对全局内存中 64 位原子操作的原生支持。除了
原子内存操作在并行编程中非常重要,支持并发线程对共享数据结构正确执行读-修改-写操作。原子操作(如 add、min、max 和 compare-and-swap)的读取、修改和写入操作的执行不能被其他线程中断。原子内存操作广泛用于并行排序、reduction和并行数据结构,而无需串行化线程执行的锁。与Fermi相比,Kepler GK110/210上的全局内存原子操作的吞吐量提高了 9 倍。Kepler GK110 还扩展了对全局内存中 64 位原子操作的原生支持。除了 atomicAdd、atomicCAS 和 atomicExch之外,GK110 还支持atomicMin ,atomicMax, atomicAnd, atomicOr, atomicXor。不支持的其他原子操作(例如,64 位浮点原子)可以使用比较和交换 (CAS) 指令进行模拟。
内存结构
Kepler的内存层次结构与 Fermi类似。Kepler 架构支持用于加载和存储的统一内存请求路径,每个 SMX 有一个 L1 缓存。Kepler GK110 还支持编译器直接使用额外的新缓存来存储只读数据。
 在 Kepler GK110 架构中,与上一代 Fermi 架构一样,每个 SMX 都有 64 KB 的片上存储,可以配置为 48 KB 共享存储和 16 KB 的 L1 缓存,或 16 KB 的共享存储和 48 KB 的 L1 缓存;另外,Kepler 还支持共享内存和 L1 缓存之间分配 32KB / 32KB,从而在配置共享内存和 L1 缓存的分配方面具有更大的灵活性。为了支持每个 SMX 单元的吞吐量增加,与 Fermi SM 相比,64b 和更大加载操作的共享内存带宽也增加了一倍,达到每个内核时钟 256B。对于 GK210 架构,可配置内存总量翻了一番,达到 128 KB,最多允许 112 KB 共享内存和 16 KB 的 L1 缓存。其他可能的内存配置包括 32 KB L1 缓存和 96 KB 共享内存,或 48 KB L1 缓存和 80 KB 共享内存。
在 Kepler GK110 架构中,与上一代 Fermi 架构一样,每个 SMX 都有 64 KB 的片上存储,可以配置为 48 KB 共享存储和 16 KB 的 L1 缓存,或 16 KB 的共享存储和 48 KB 的 L1 缓存;另外,Kepler 还支持共享内存和 L1 缓存之间分配 32KB / 32KB,从而在配置共享内存和 L1 缓存的分配方面具有更大的灵活性。为了支持每个 SMX 单元的吞吐量增加,与 Fermi SM 相比,64b 和更大加载操作的共享内存带宽也增加了一倍,达到每个内核时钟 256B。对于 GK210 架构,可配置内存总量翻了一番,达到 128 KB,最多允许 112 KB 共享内存和 16 KB 的 L1 缓存。其他可能的内存配置包括 32 KB L1 缓存和 96 KB 共享内存,或 48 KB L1 缓存和 80 KB 共享内存。
除了 L1 缓存之外,Kepler 还为已知在函数期间为只读的数据引入了一个 48KB 的缓存。在Fermi 中,只有纹理单元才能访问此缓存。在 Kepler 中,除了显著增加此缓存的容量以及纹理性能外,SM 可以直接访问缓存以进行一般加载操作。使用只读路径可以消除共享/L1 缓存路径的加载和工作集占用空间。此外,只读数据缓存的更高标记带宽支持全速未对齐的内存访问模式。只读路径的使用可以由编译器自动管理,也可以由程序员显式管理。通过使用 C99 标准const __restrict关键字访问已知为常量的任何变量或数据结构,编译器可能会标记以通过只读数据缓存加载。程序员还可以显式地将此路径与__ldg() 内部函数一起使用。
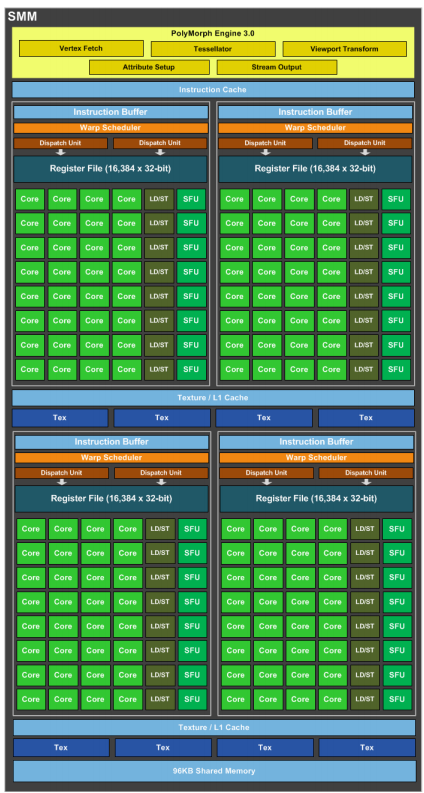
2.8 Maxwell
2014年,NVIDIA发布Maxwell架构;GM200 GPU 采用 Maxwell 2.0 架构,使用台积电的 28 纳米工艺制造,面积 601 mm²,晶体管数量为 80 亿个。下图展示了GM200的物理版图:
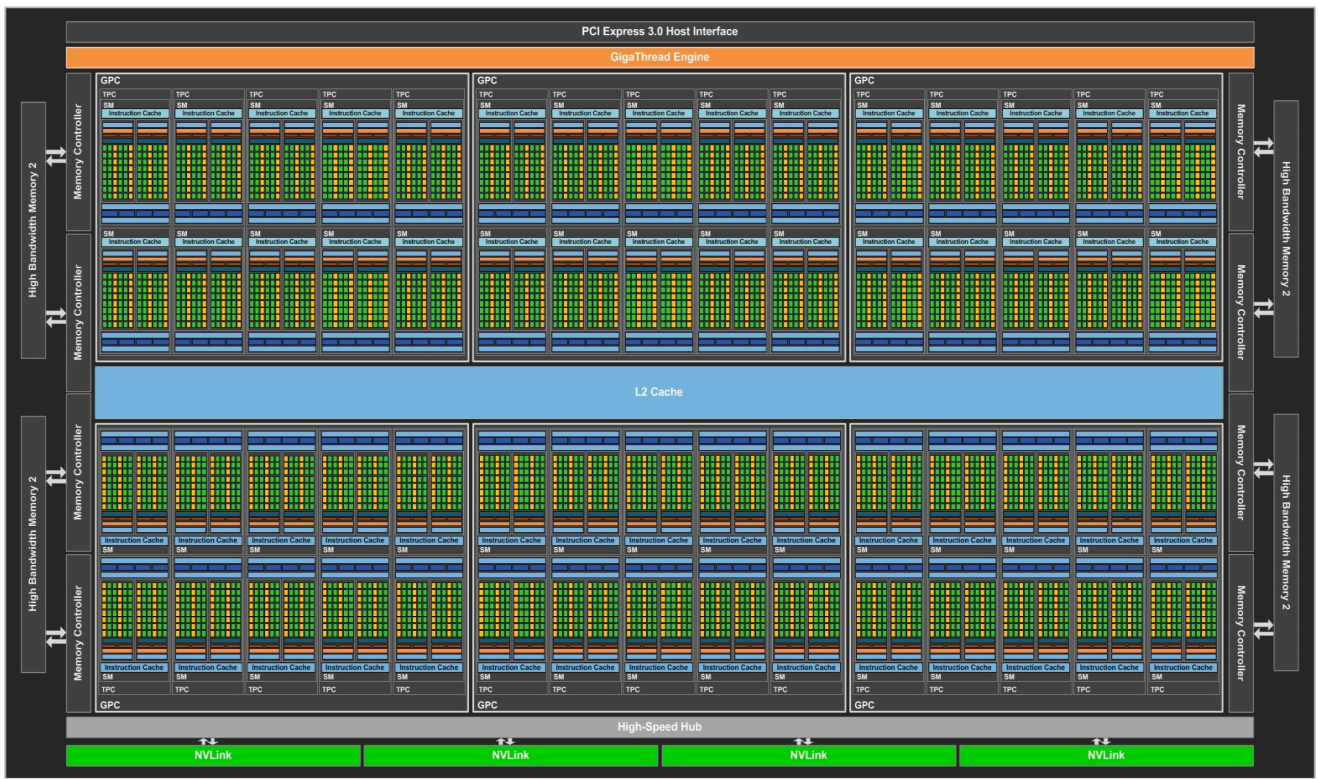 GM200 由 6 个 GPC(Graphics Processing Cluster)、24 个SMM和 6 个内存控制器组成。L2缓存一共2MB。
GM200 由 6 个 GPC(Graphics Processing Cluster)、24 个SMM和 6 个内存控制器组成。L2缓存一共2MB。
 每个 SMM 包含四个 warp 调度器,每个 warp 调度器每个时钟能够分发一个 warp 的两个指令。每个 SM 总共 128 个 CUDA 核,分成4个块,各有 32 个 CUDA 核,与warp线程数一致,以及用于调度的专用资源和指令缓冲。SMM有单独的96KB共享存储,但是每个线程块最大只能使用48KB;每个 SMM 还有 4 个 DP 单元。
每个 SMM 包含四个 warp 调度器,每个 warp 调度器每个时钟能够分发一个 warp 的两个指令。每个 SM 总共 128 个 CUDA 核,分成4个块,各有 32 个 CUDA 核,与warp线程数一致,以及用于调度的专用资源和指令缓冲。SMM有单独的96KB共享存储,但是每个线程块最大只能使用48KB;每个 SMM 还有 4 个 DP 单元。
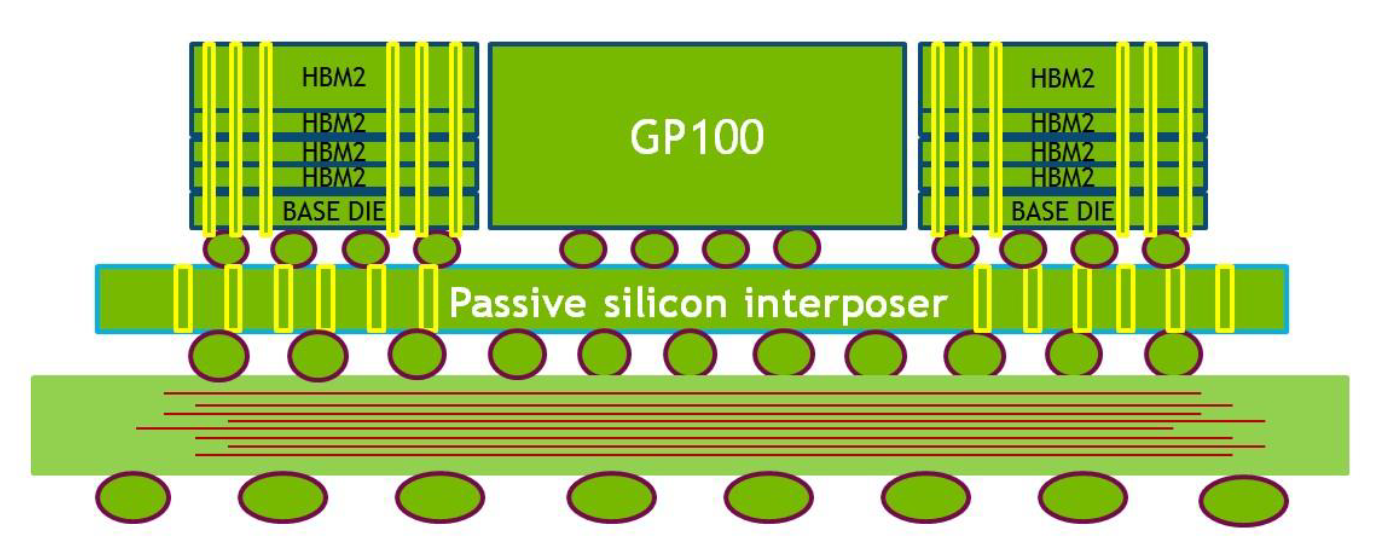
2.9 Pascal
2016年,NVIDIA推出Pascal架构,GP100采用台积电16nm工艺,面积610 mm²,153亿晶体管;支持8x512位宽的HBM,容量16GB;下图展示了GP100的物理版图,HBM I/O 位于顶部和底部,NVLink 和PCIe I/O 位于左侧:
 GP100 是首款支持硬件页面故障的 NVIDIA GPU,结合 49 位 (512 TB) 虚拟寻址,GPU 和 CPU 可以使用统一的虚拟地址空间。GP100 中新增的另一个重要的功能是计算抢占 ,允许以指令级粒度抢占计算任务,而不是像以前的 Maxwell 和 Kepler GPU 架构那样以线程块粒度抢占。计算抢占可防止长时间运行的应用程序独占系统或超时。
GP100 是首款支持硬件页面故障的 NVIDIA GPU,结合 49 位 (512 TB) 虚拟寻址,GPU 和 CPU 可以使用统一的虚拟地址空间。GP100 中新增的另一个重要的功能是计算抢占 ,允许以指令级粒度抢占计算任务,而不是像以前的 Maxwell 和 Kepler GPU 架构那样以线程块粒度抢占。计算抢占可防止长时间运行的应用程序独占系统或超时。
GP100 由 6 个 GPC,30 个 TPC(每个包括 2 个 SM),60 个 Pascal SM。
 每个 SM 有 64 个 CUDA 核和 4 个纹理单元。因此,GP100 一共有 3840 个单精度 CUDA 核和 240 个纹理单元。GP100 SM 分为两个处理块,每个处理块有 32 个单精度 CUDA 核、一个指令缓冲区、一个warp调度器和两个分发单元。GP100 SM 的 CUDA 核总数是 Maxwell SM 的一半,但寄存器文件大小相同的,并支持类似的warp和线程块占用。
每个 SM 有 64 个 CUDA 核和 4 个纹理单元。因此,GP100 一共有 3840 个单精度 CUDA 核和 240 个纹理单元。GP100 SM 分为两个处理块,每个处理块有 32 个单精度 CUDA 核、一个指令缓冲区、一个warp调度器和两个分发单元。GP100 SM 的 CUDA 核总数是 Maxwell SM 的一半,但寄存器文件大小相同的,并支持类似的warp和线程块占用。
 GP100 SM 有专用64 KB共享内存和 L1 缓存,该缓存也可用作纹理缓存。统一的 L1/纹理缓存充当内存访问的合并缓冲区,在将数据发送到warp之前收集warp里线程请求的数据。每个内存控制器都连接到 512 KB 的 L2 缓存,因此,GP100总共包括 4096 KB 的 L2 缓存。GP100 GPU 连接到四个 HBM2 DRAM 堆栈,每个 HBM2 DRAM 堆栈由一对内存控制器控制;Tesla P100 配备四个 4 芯片 HBM2 堆栈,总共 16 GB 的 HBM2 内存。
GP100 SM 有专用64 KB共享内存和 L1 缓存,该缓存也可用作纹理缓存。统一的 L1/纹理缓存充当内存访问的合并缓冲区,在将数据发送到warp之前收集warp里线程请求的数据。每个内存控制器都连接到 512 KB 的 L2 缓存,因此,GP100总共包括 4096 KB 的 L2 缓存。GP100 GPU 连接到四个 HBM2 DRAM 堆栈,每个 HBM2 DRAM 堆栈由一对内存控制器控制;Tesla P100 配备四个 4 芯片 HBM2 堆栈,总共 16 GB 的 HBM2 内存。
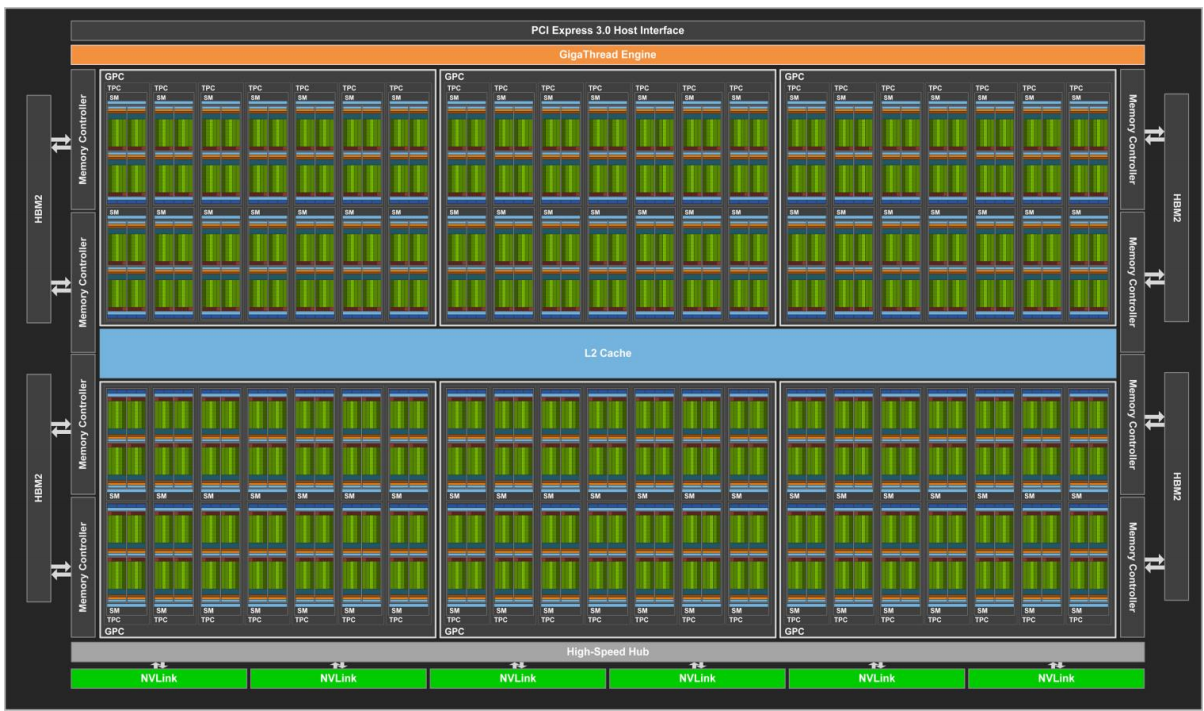
2.10 Volta
2017年,NVIDIA推出Volta架构,V100采用台积电12nm工艺,面积815 mm²,211亿晶体管;V100物理版图如下所示:
 完全版GV100一共6个GPC,每个GPC有7个TPC,每个TPC有2个SM,一共84个SM;V100一共80个SM。
完全版GV100一共6个GPC,每个GPC有7个TPC,每个TPC有2个SM,一共84个SM;V100一共80个SM。
 Volta架构一些主要新特性包括:
Volta架构一些主要新特性包括:
- Multi Processor Service Volta 的MPS(Multi Processor Service)可以允许多个应用程序同时在GPU 执行。 但是,由于所有应用程序共享内存资源,因此,如果一个应用程序要求很高的DRAM 带宽,或者其请求超额订阅了 L2 缓存,可能会干扰其他应用程序;并且只支持完整的物理 GPU 粒度使用。
- 独立线程调度 Volta 架构引入了对互斥等算法防饥饿的支持,当编译器识别编程语言指定的可见机器步骤时,确保每个线程最终都会取得进展。下面代码用一个保护进入关键部分的简单的自旋锁来说明Volta 架构的新功能。当且仅当调度程序确保每个线程能独立的向前推进时,多个线程才可以同时调用以下示例中的函数
demo_A。此自旋锁在 CUDA C++ 1.1 中在语法上是合法的,但在 Volta 架构上的 CUDA C++ 9.0 之前不完全支持:enum { unlocked = 0, locked = 1 }; volatile int mutex = unlocked; void demo_A() { /* Among throughput processors, only Volta is guaranteed to run this critical section. */ while(atomicCAS(&mutex,unlocked,locked)==locked) ; mutex = unlocked; }在之前的设计中,执行发散优化可能会延迟任何线程对关键部分的执行,直到所有线程终止循环,从而导致程序进入活锁状态。Volta 架构中的执行发散优化通过确保没有线程无限期挂起来解决此问题。当保留在循环中的线程执行可见的计算步骤(如原子操作)时,调度程序会为其他线程提供进行等效向前推进的机会。
- 灵活的屏障 在 CUDA 中,最常见的同步是块中所有线程之间的屏障。如果一个块中的所有线程都调用相同次数的屏障,每个线程中的相应调用会相互同步。这是 CUDA C++ 1.0 屏障原语背后的原始想法,称为
__syncthreads(),如下面的demo_B函数中使用:extern bool is_odd(int); extern bool is_even(int); volatile bool is_sound = true; void demo_B() { const int x = threadIdx.x; if(is_odd(x) || is_even(x)) { /* The assertion does not fire on Volta, but may fire on other throughput processors. */ assert(is_sound); __syncthreads(); is_sound = false; } }这个函数的合理性问题与CUDA和类似的并行系统中对同步的额外限制有关,特别是当Warp执行发散时禁止线程调用
__syncthreads()。例如,demo_B可能会因逻辑运算符||的短路控制流而变得不健全。在 Volta 中引入独立线程调度能够消除限制。 - 改进的执行收敛性 有些程序具有比任何实现都更趋同的执行潜力。考虑下面具有静态不确定执行分歧的程序:
extern bool is_equal(int, int); void demo_C() { for(int i = 0;i < 1024; ++i) if(is_equal(threadIdx.x, i)) { /* Other throughput processors run this block with execution divergence, but Volta may avoid it. */ } }函数
demo_C在 SIMT 处理器上执行速度可能很慢,因为线程在执行条件指令时会串行化。预测最里面的块可能被所有线程执行并不足以避免这种串行化。Volta 架构支持的收敛优化可用于此类情况。下面的程序使用shuffle操作在线程之间交换值。demo_D使用 CUDA 9.0 中引入的 Cooperative Groups聚合来自整个 Warp 的数据,消除了应用 Warp 优化所需的猜测,并使高性能程序员的工作效率更高。执行路径重新收敛可以看作是性能优化,而 Warp 中的显式同步仍然受支持。#include <cooperative_groups.h> int demo_D(int *ptr) { cg::coalesced_group g = cg::coalesced_threads(); int prev; /* Elect the first active thread to perform atomic add. */ if(g.thread_rank() == 0) prev = atomicAdd(ptr, g.size()); /* Broadcast previous value within the Warp and add each active thread’s rank to it. */ prev = g.thread_rank() + g.shfl(prev, 0); return prev; }
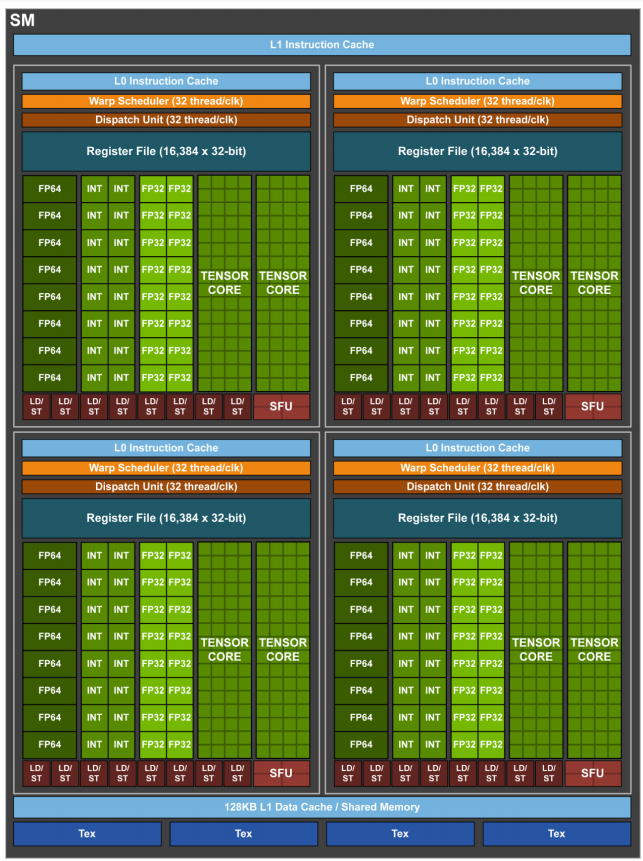
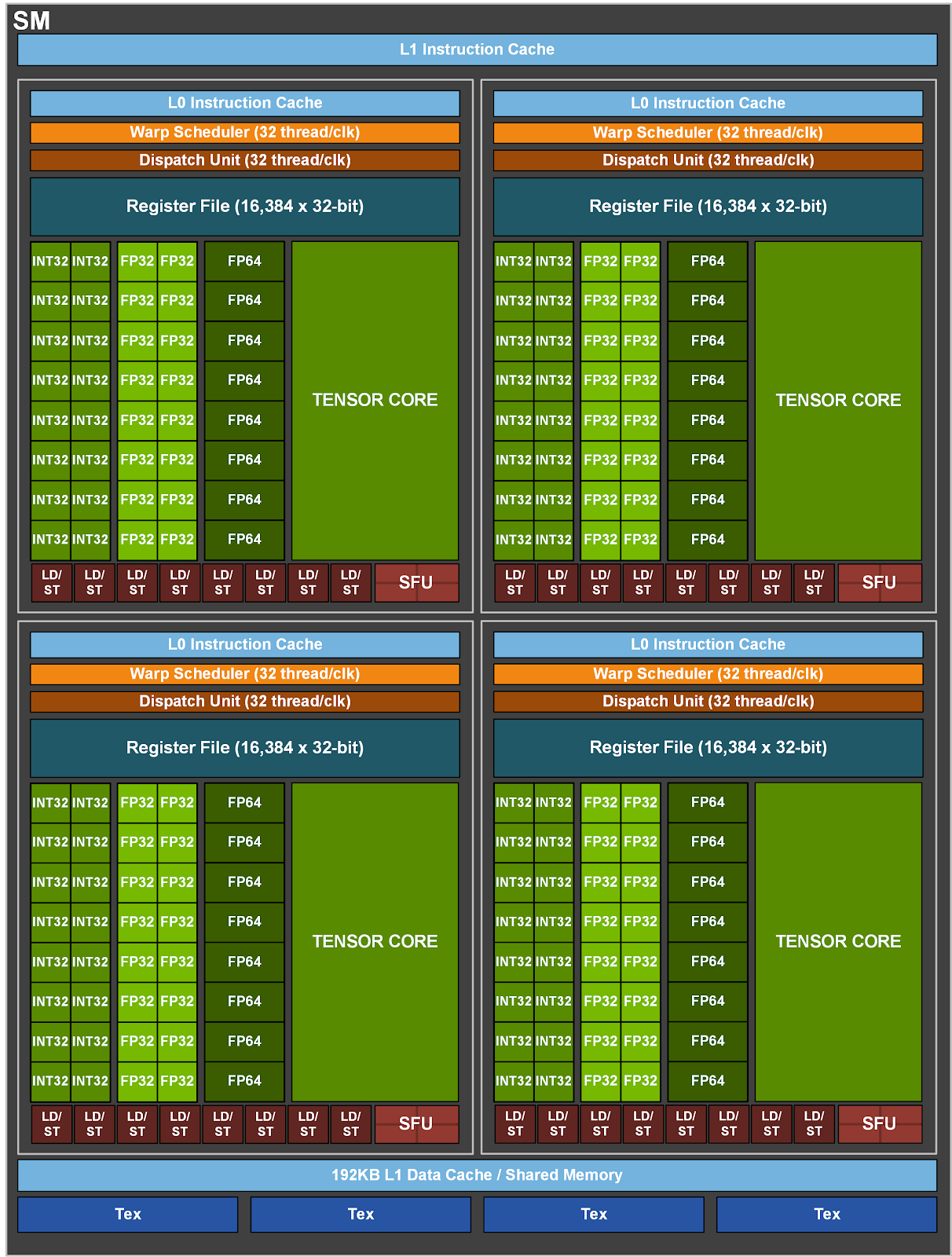
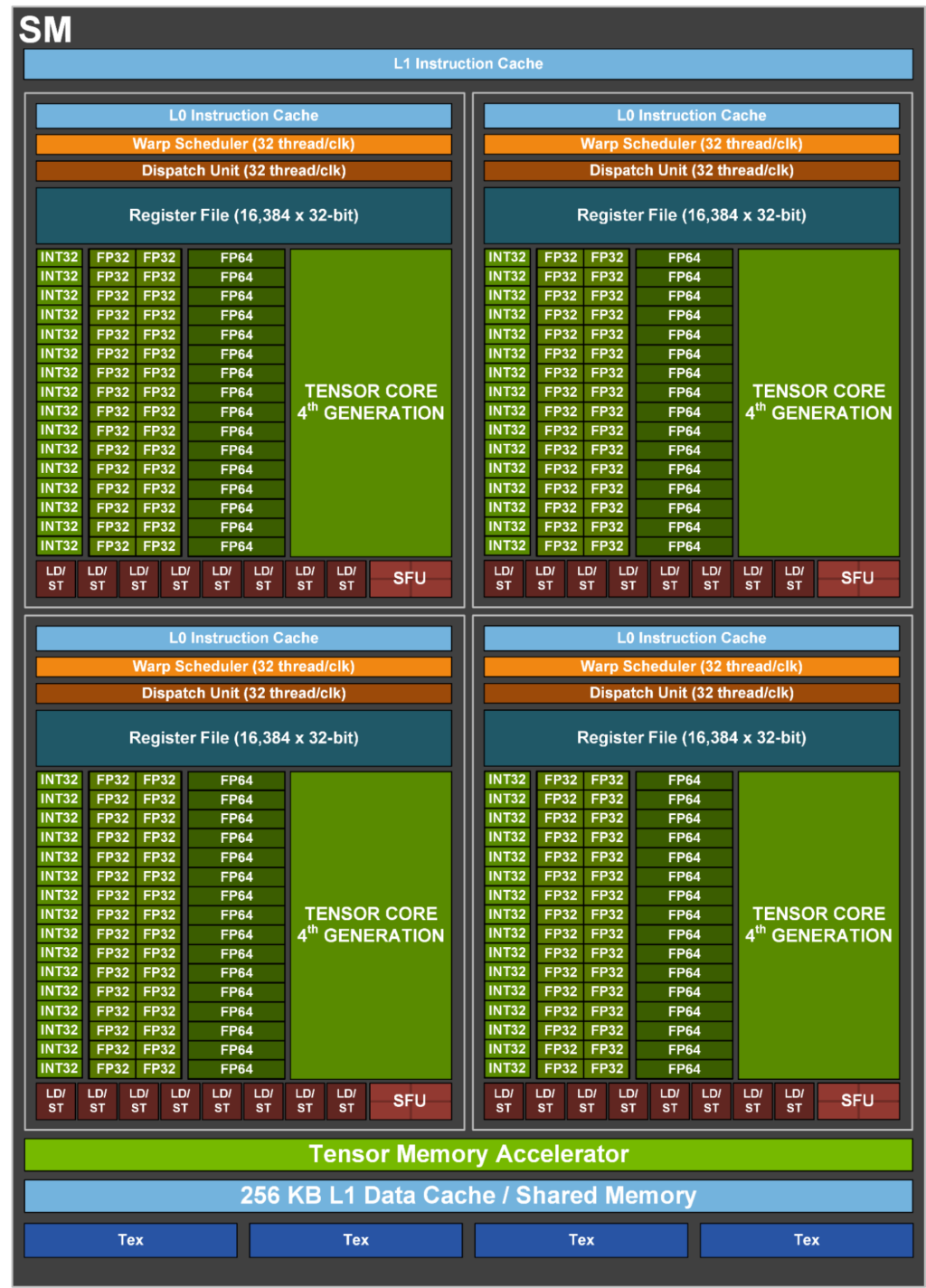
每个SM有64 个FP32核和32 个FP64核,并且分成4个部分,每一部分有16个FP32核,8个FP64核,16个INT32核,2个混合精度张量核(Tensor Core),一个L0指令缓存,一个warp调度器,一个分发单元,以及64 KB寄存器文件。
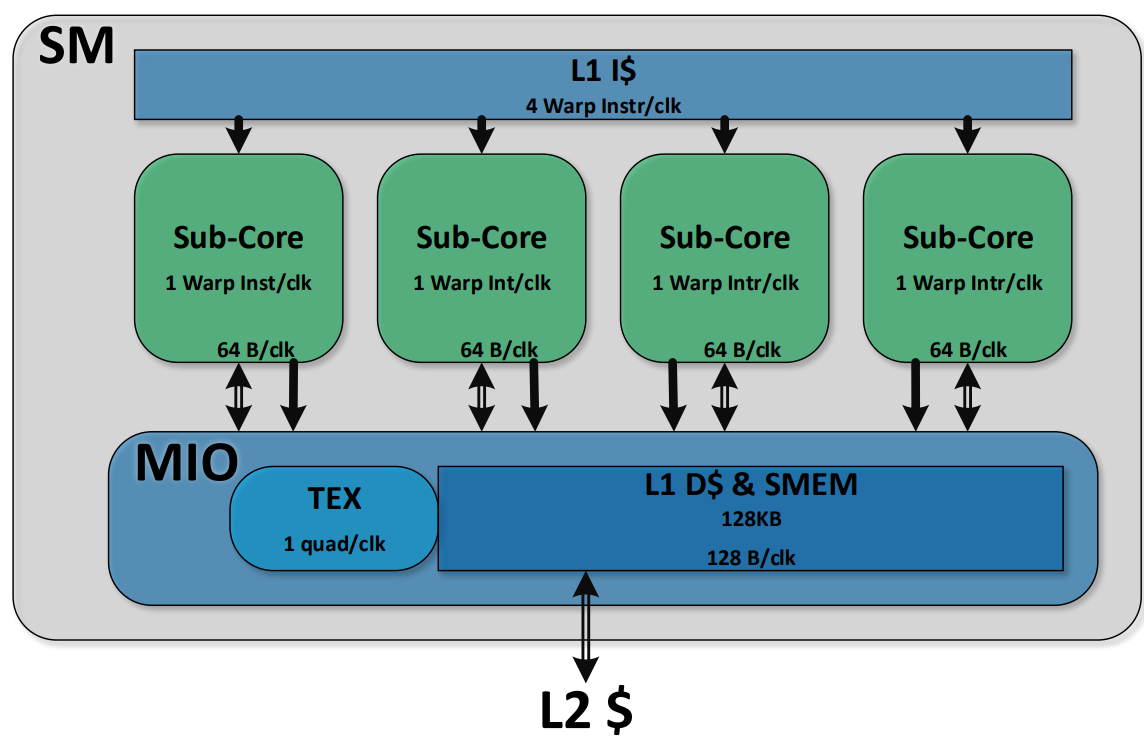
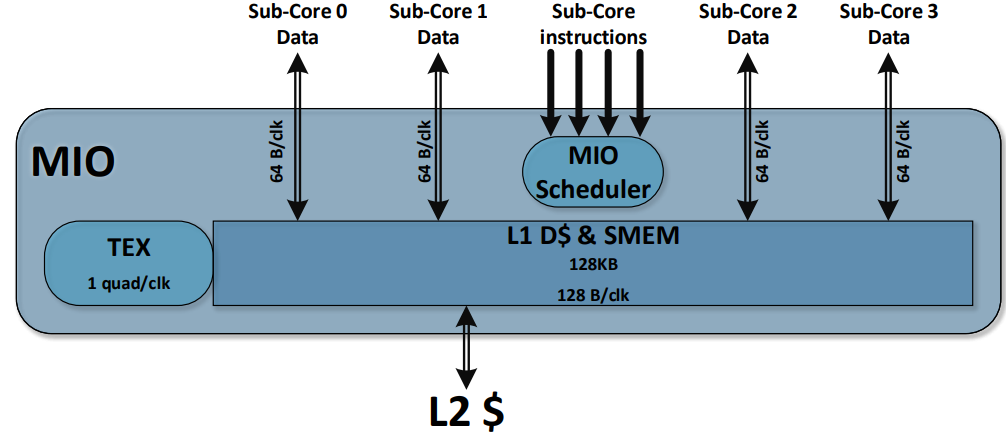
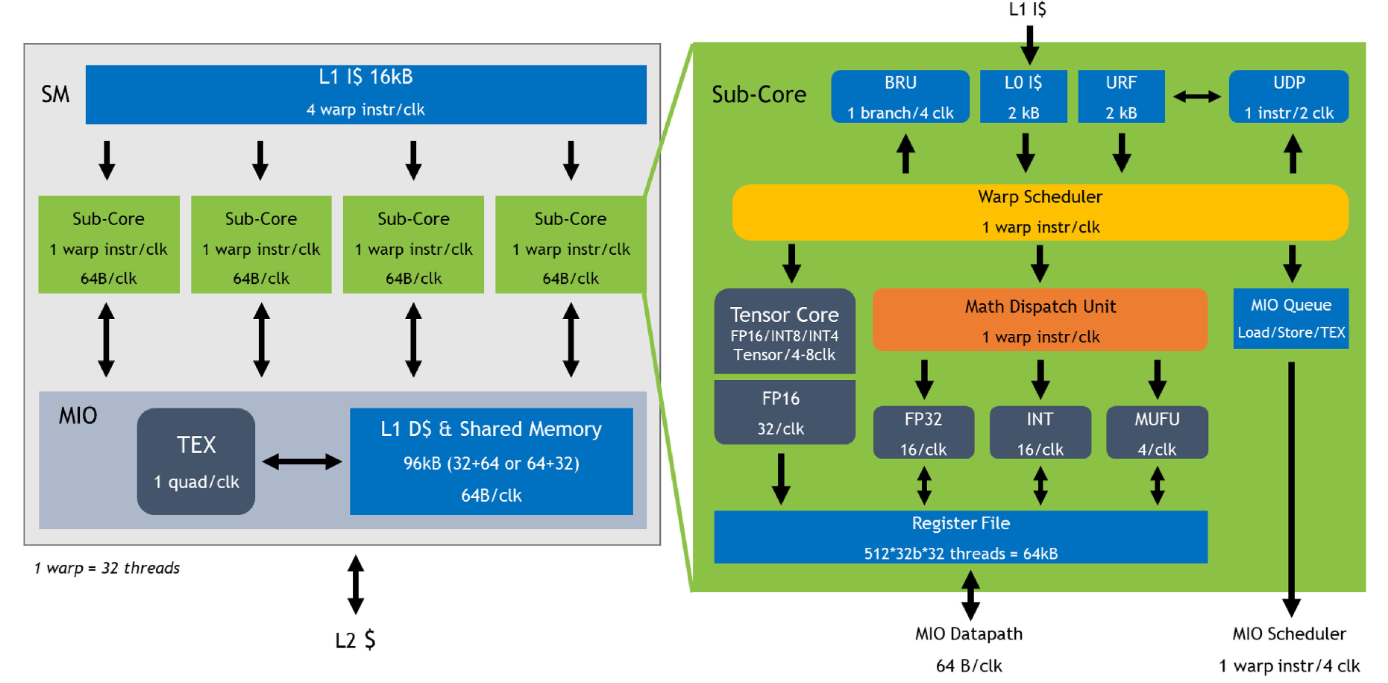
 Volta SM由四个独立调度的Sub-Core组成。SM 执行 Warp的 SIMT 调度,每个Sub-Core调度器每个时钟可以调度一个 Warp 指令。将数据路径和调度器拆分可以最大限度地提高局部性,并降低数据路径、寄存器文件和调度器的功耗。全局内存加载和存储缓存操作、共享内存 (SMEM) 暂存器操作和纹理 (TEX) 操作将发送到共享内存和 I/O (MIO) 单元。四个 SM Sub-Core将其 MIO 指令发送到共享的 MIO 单元调度执行。MIO 调度器在纹理单元或统一共享内存和 L1 数据缓存上调度执行。TEX单元每个时钟可以执行一个像素的四边形纹理指令,纹理操作所需的数据来自 L1 数据缓存。共享的 MIO 单元在Sub-Core之间提供统一的线程间通信,从而实现高效、协作的线程执行。四个Sub-Core共享一个 L1 指令缓存,每个时钟可以发送四个 Warp 指令。
Volta SM由四个独立调度的Sub-Core组成。SM 执行 Warp的 SIMT 调度,每个Sub-Core调度器每个时钟可以调度一个 Warp 指令。将数据路径和调度器拆分可以最大限度地提高局部性,并降低数据路径、寄存器文件和调度器的功耗。全局内存加载和存储缓存操作、共享内存 (SMEM) 暂存器操作和纹理 (TEX) 操作将发送到共享内存和 I/O (MIO) 单元。四个 SM Sub-Core将其 MIO 指令发送到共享的 MIO 单元调度执行。MIO 调度器在纹理单元或统一共享内存和 L1 数据缓存上调度执行。TEX单元每个时钟可以执行一个像素的四边形纹理指令,纹理操作所需的数据来自 L1 数据缓存。共享的 MIO 单元在Sub-Core之间提供统一的线程间通信,从而实现高效、协作的线程执行。四个Sub-Core共享一个 L1 指令缓存,每个时钟可以发送四个 Warp 指令。
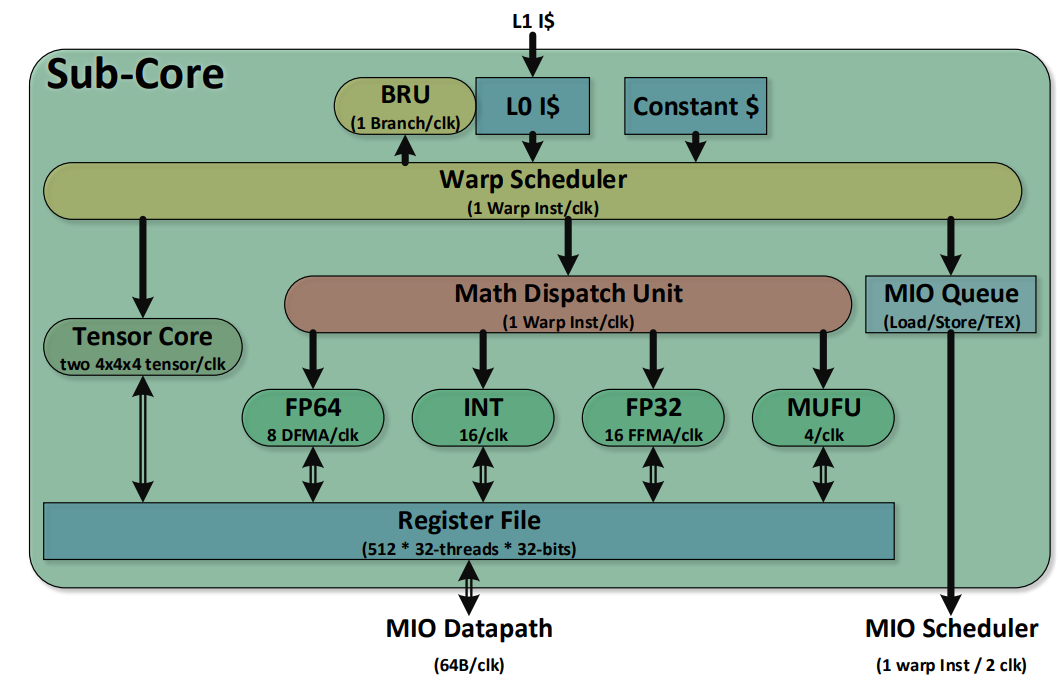
每个时钟SM Sub-Core都可以从L0指令缓存中发出一个Warp 指令。指令被发送到本地分支单元 (BRU)、数学分发单元、张量核或共享 MIO 单元。数学分发单元每个时钟可以将一个Warp指令调度到四个执行单元:整数指令 (INT)、32 位浮点指令 (FP32)、64 位浮点指令 (FP64) 和其他超越指令 (MUFU)。数学分发单元能够保持两个或多个执行单元得到充分利用,具体取决于正在执行的程序中的指令组合。每个 SM Sub-Core还包含两个 4x4x4 张量核,Warp 调度器向张量核发射矩阵乘法运算;张量核从寄存器文件接收输入矩阵,执行多个 4x4x4 矩阵乘法,直到全矩阵乘法完成,并将生成的矩阵写回寄存器文件中。
 每个 SM 有8 个张量核,每个Sub-Core有2个;每个张量核每个时钟执行 64(4x4x4) 个浮点运算,SM 中的8个张量核每个时钟总共执行 1,024 次浮点运算。每个张量核在 4x4 矩阵上运行并执行以下操作:D=A×B+C,其中 A、B、C 和 D 是 4x4 矩阵。矩阵乘法输入 A 和 B 是 FP16 矩阵,而累积矩阵 C 和 D 可以是 FP16 或 FP32 矩阵;FP16 乘法产生全精度乘积,然后使用 FP32 与其他中间乘积累加,形成 4x4x4 矩阵乘法。
每个 SM 有8 个张量核,每个Sub-Core有2个;每个张量核每个时钟执行 64(4x4x4) 个浮点运算,SM 中的8个张量核每个时钟总共执行 1,024 次浮点运算。每个张量核在 4x4 矩阵上运行并执行以下操作:D=A×B+C,其中 A、B、C 和 D 是 4x4 矩阵。矩阵乘法输入 A 和 B 是 FP16 矩阵,而累积矩阵 C 和 D 可以是 FP16 或 FP32 矩阵;FP16 乘法产生全精度乘积,然后使用 FP32 与其他中间乘积累加,形成 4x4x4 矩阵乘法。
内存结构
SM的L1 数据缓存为 128 KB,每个时钟最多可执行 32 个线程的加载和存储,最多可提供 128B。L1 数据缓存与 SMEM存储统一,128 KB 的 L1 数据存储中最多可以动态配置96 KB 用作 SMEM。L1 数据缓存加载和存储与 SMEM 加载和存储采用相同的执行路径。因此,L1 加载和存储缓存命与 SMEM 加载和存储有相同的带宽和延迟。所有SM共享6MB的L2缓存。8个512位宽的内存控制器一共提供900 GB/s带宽,支持16 GB HBM2内存。
2.11 Turing
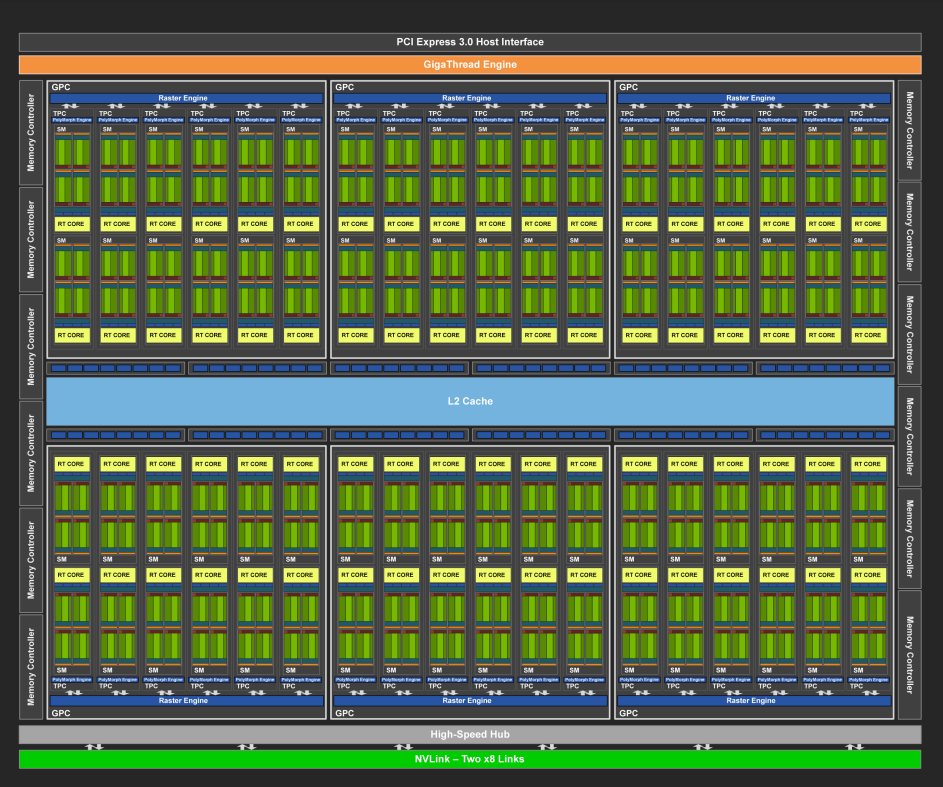
2018年,NVIDIA推出Turing架构;TU102 GPU采用台积电12 nm工艺,面积754 mm²,包含186亿晶体管, TDP功耗250W,支持384位宽的GDDR6内存,最高24GB。TU102的物理版图如下所示:
 TU102 GPU 包括 6 个图形处理集群GPC (Graphics Processing Cluster),36 个纹理处理集群TPC (Texture Processing Cluster) 和 72 个SM(Streaming Multiprocessor)。每个 GPC 都包括一个专用光栅引擎和 6 个 TPC,每个 TPC 包括 2 个 SM。每个 SM 包含 64 个 CUDA 核、8 个 Tensor 核、256 KB 寄存器文件、4 个纹理单元和 96 KB 的 L1/共享内存。SM 中的新 RT Core 处理光线追踪加速。Turing GPU 架构继承了 Volta 架构中首次引入的增强型多进程服务MPS (Multi-Process Service) 功能。
在 Pascal GPU 架构之前,NVIDIA GPU 使用单个多输入/输出 (MIO) 接口作为 SLI 桥接技术,以允许第二个(或第三个或第四个)GPU 将其最终渲染的帧输出传输到物理连接到显示器的主 GPU。Pascal 通过使用更快的双 MIO 接口增强了 SLI 桥接器,提高了 GPU 之间的带宽,允许更高分辨率的输出,并为 NVIDIA Surround 提供了多个高分辨率显示器。Turing TU102使用 NVLink 而不是 MIO 和 PCIe 接口进行 SLI GPU 到 GPU 的数据传输。TU102 GPU 包括两个 x8 NVLink 2 链路,每个链路在两个 GPU 之间提供每个方向 25 GB/秒的峰值带宽(50 GB/秒的双向带宽),支持双向 SLI,但不支持 3 路和 4 路 SLI 配置。
TU102 GPU 包括 6 个图形处理集群GPC (Graphics Processing Cluster),36 个纹理处理集群TPC (Texture Processing Cluster) 和 72 个SM(Streaming Multiprocessor)。每个 GPC 都包括一个专用光栅引擎和 6 个 TPC,每个 TPC 包括 2 个 SM。每个 SM 包含 64 个 CUDA 核、8 个 Tensor 核、256 KB 寄存器文件、4 个纹理单元和 96 KB 的 L1/共享内存。SM 中的新 RT Core 处理光线追踪加速。Turing GPU 架构继承了 Volta 架构中首次引入的增强型多进程服务MPS (Multi-Process Service) 功能。
在 Pascal GPU 架构之前,NVIDIA GPU 使用单个多输入/输出 (MIO) 接口作为 SLI 桥接技术,以允许第二个(或第三个或第四个)GPU 将其最终渲染的帧输出传输到物理连接到显示器的主 GPU。Pascal 通过使用更快的双 MIO 接口增强了 SLI 桥接器,提高了 GPU 之间的带宽,允许更高分辨率的输出,并为 NVIDIA Surround 提供了多个高分辨率显示器。Turing TU102使用 NVLink 而不是 MIO 和 PCIe 接口进行 SLI GPU 到 GPU 的数据传输。TU102 GPU 包括两个 x8 NVLink 2 链路,每个链路在两个 GPU 之间提供每个方向 25 GB/秒的峰值带宽(50 GB/秒的双向带宽),支持双向 SLI,但不支持 3 路和 4 路 SLI 配置。
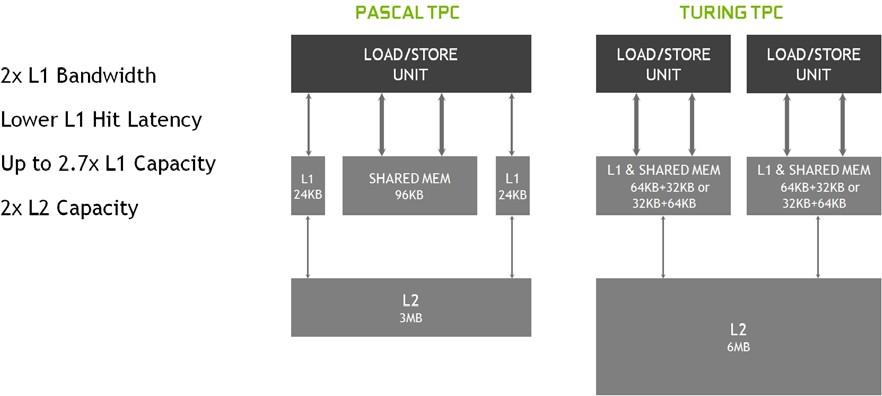
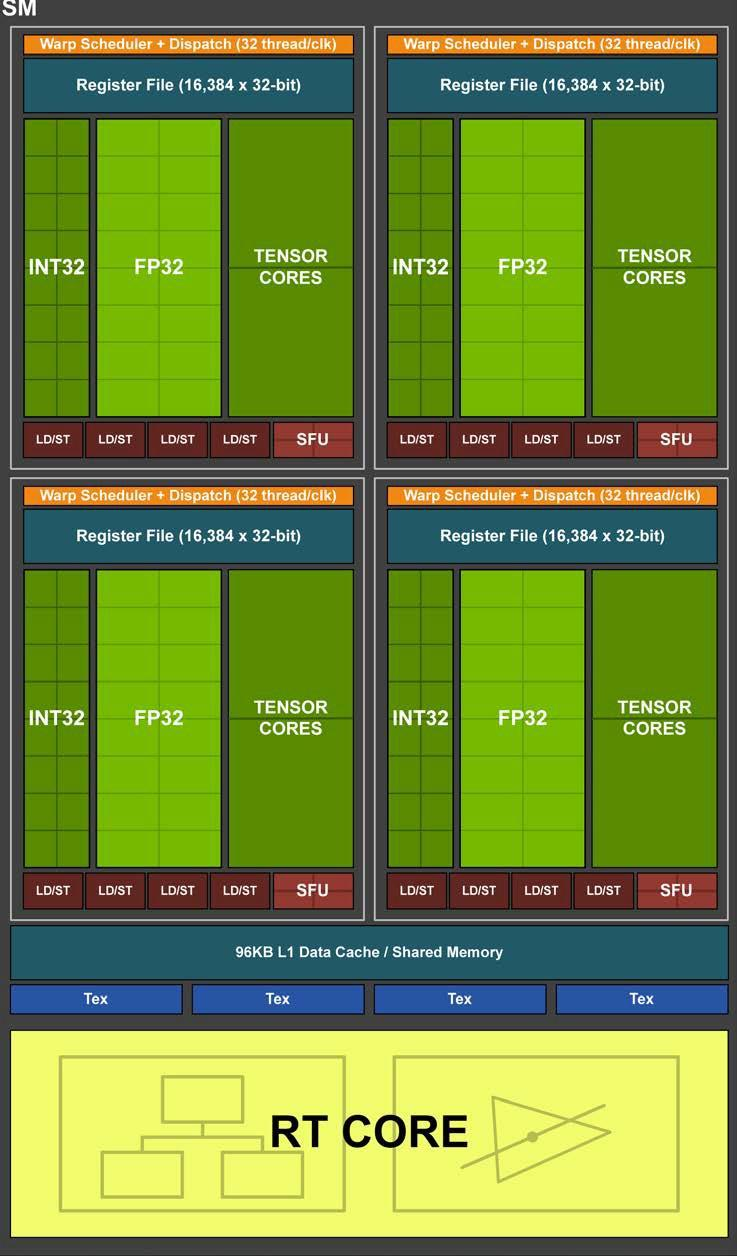
Turing 引入了一种新的SM,显着提高了着色效率,与 Pascal相比,每个 CUDA 核的性能提高了 50%。这些改进是通过两个关键的体系结构更改实现的:
- 首先,Turing SM 增加了一个新的独立整数数据路径,可以与浮点数据路径同时执行指令。在之前几代中,执行整数指令会阻止浮点指令的发射
- 其次,重新设计了 SM 内存路径,将共享内存、纹理缓存和内存加载缓存统一成一个单元。L1 缓存的带宽增加了 2 倍
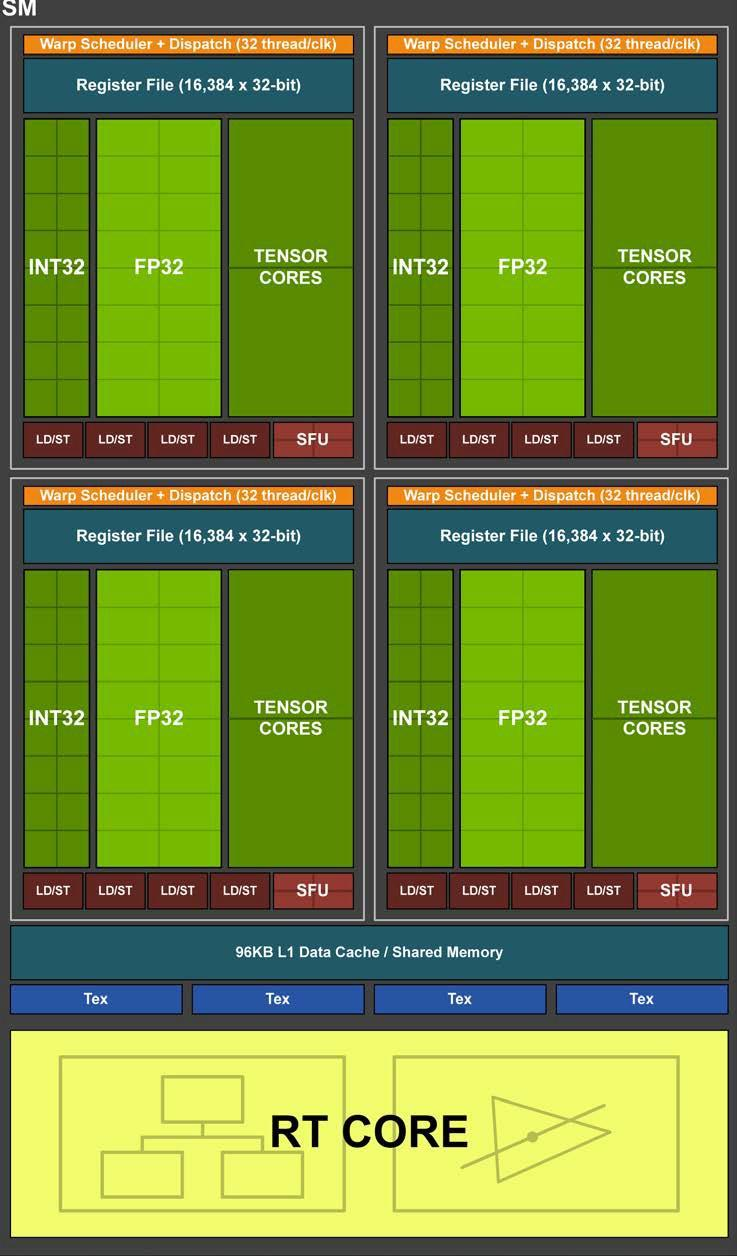 Turing SM 被划分为四个处理块,每个处理块有 16 个 FP32 核、16 个 INT32 核、两个 Tensor 核、一个 warp 调度器和一个调度单元。每个处理块包括一个新的 L0 指令缓存和一个 64 KB 的寄存器文件。四个处理块共享一个 96 KB 的 L1 数据缓存/共享内存,传统的图形工作负载可以将 96 KB L1/共享内存划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域;而计算工作负载可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。Turing对核心执行数据路径进行了重大改造。现代着色器程序通常混合使用浮点算术指令(如 FADD 或 FMAD)以及用于寻址和获取数据的整数加法、用于浮点比较或最小值/最大值处理结果的简单指令;平均每 100 条浮点指令会和36 条整数指令共同执行。之前的着色器体系结构中,非 FP 指令执行时,浮点数据路径会处于空闲状态。Turing在每个 CUDA 核旁边添加了第二个并行执行单元,可以与浮点单元并行执行。
Turing SM 被划分为四个处理块,每个处理块有 16 个 FP32 核、16 个 INT32 核、两个 Tensor 核、一个 warp 调度器和一个调度单元。每个处理块包括一个新的 L0 指令缓存和一个 64 KB 的寄存器文件。四个处理块共享一个 96 KB 的 L1 数据缓存/共享内存,传统的图形工作负载可以将 96 KB L1/共享内存划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域;而计算工作负载可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。Turing对核心执行数据路径进行了重大改造。现代着色器程序通常混合使用浮点算术指令(如 FADD 或 FMAD)以及用于寻址和获取数据的整数加法、用于浮点比较或最小值/最大值处理结果的简单指令;平均每 100 条浮点指令会和36 条整数指令共同执行。之前的着色器体系结构中,非 FP 指令执行时,浮点数据路径会处于空闲状态。Turing在每个 CUDA 核旁边添加了第二个并行执行单元,可以与浮点单元并行执行。
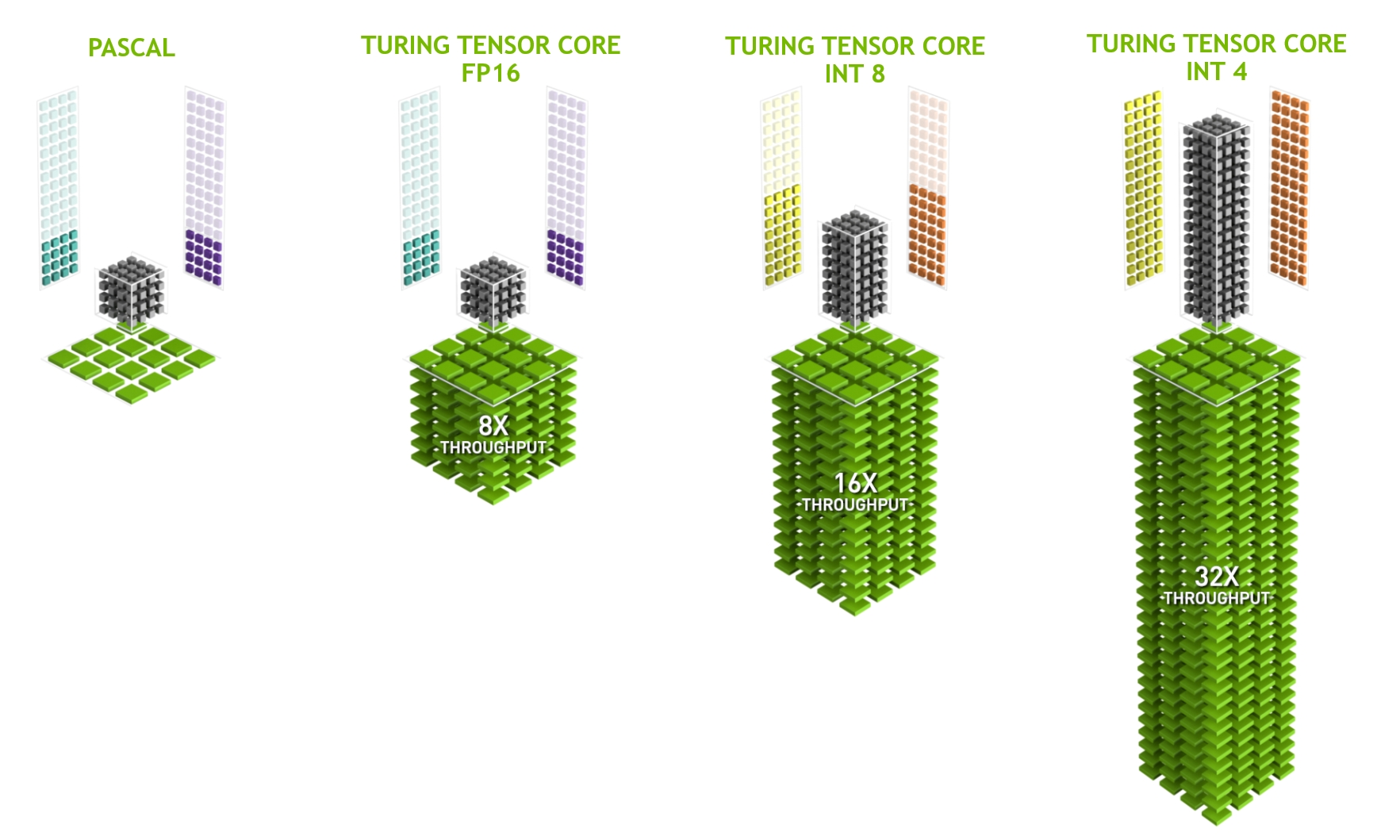
 Turing GPU 包括新版本的 Tensor Core 设计,增加了新的 INT8 和 INT4 精度模式。
Turing GPU 包括新版本的 Tensor Core 设计,增加了新的 INT8 和 INT4 精度模式。
Turing 内存结构
Turing SM包含一个 96 KB 的 L1 数据缓存/共享内存,传统的图形工作负载可以将 96 KB L1/共享内存划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域;而计算工作负载可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。TU102 GPU 配备 6 MB 二级缓存。Turing 是第一个支持 GDDR6 内存的 GPU 架构,支持384位宽,可以提供 14 Gbps带宽。
2.12 Ampere
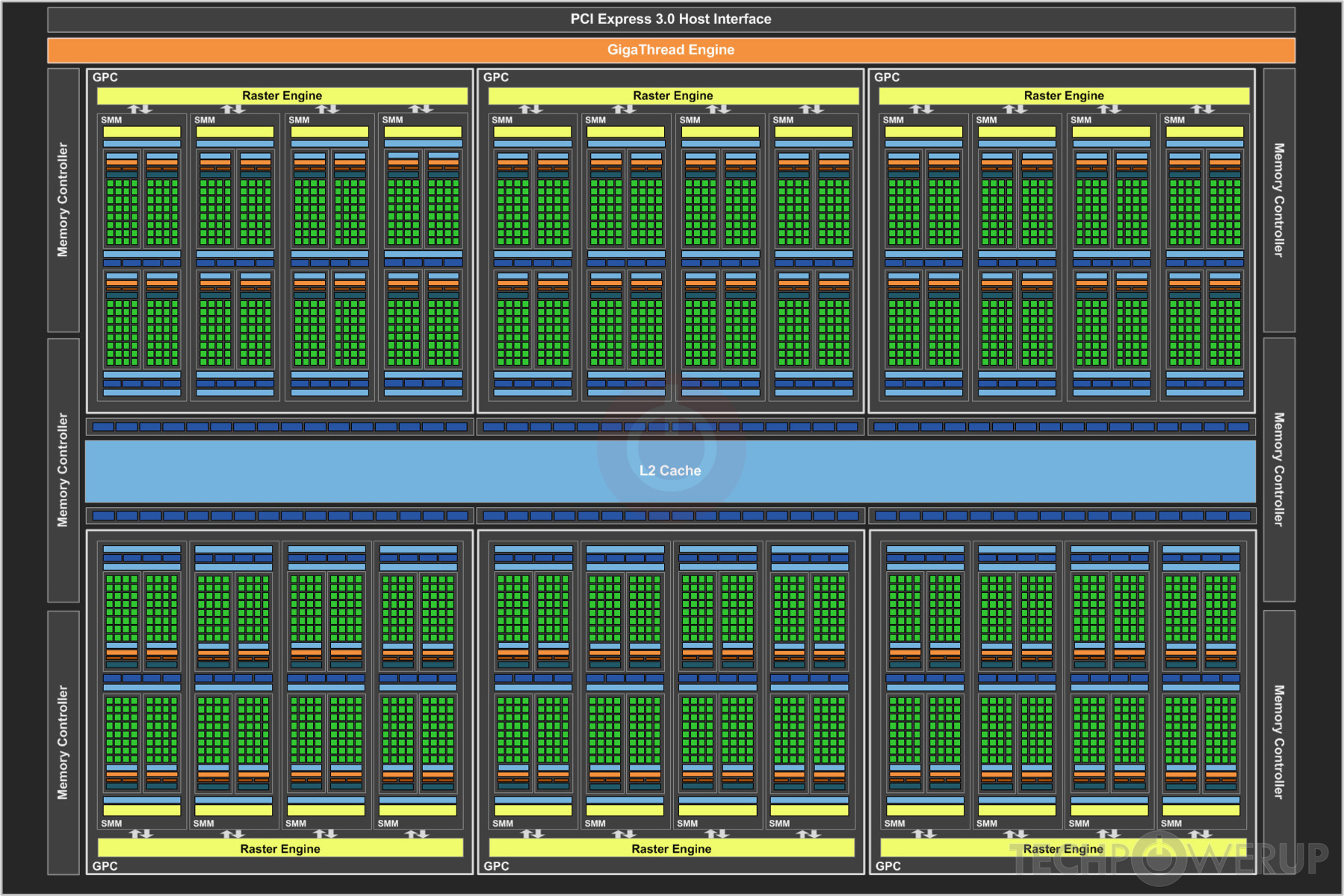
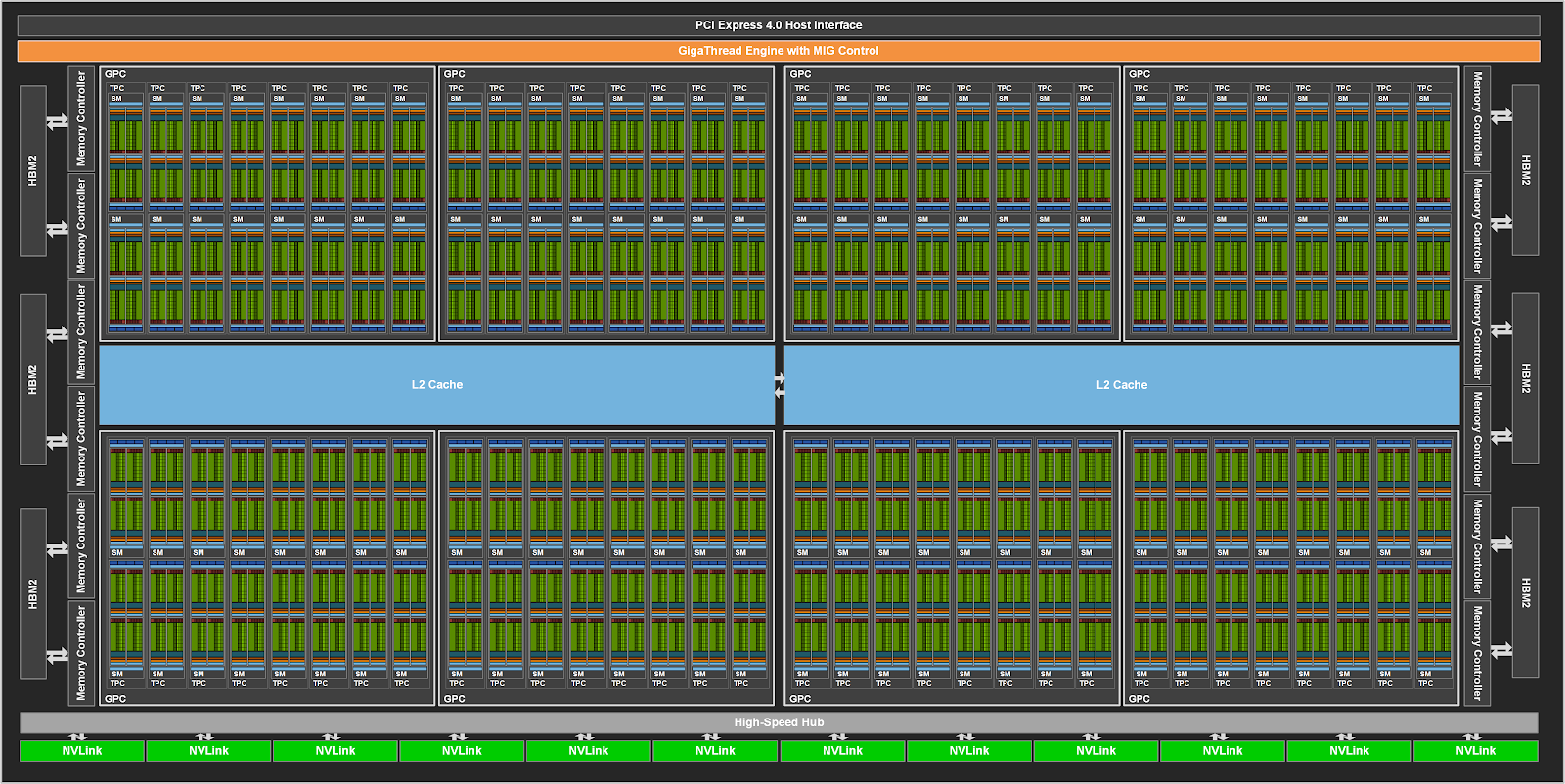
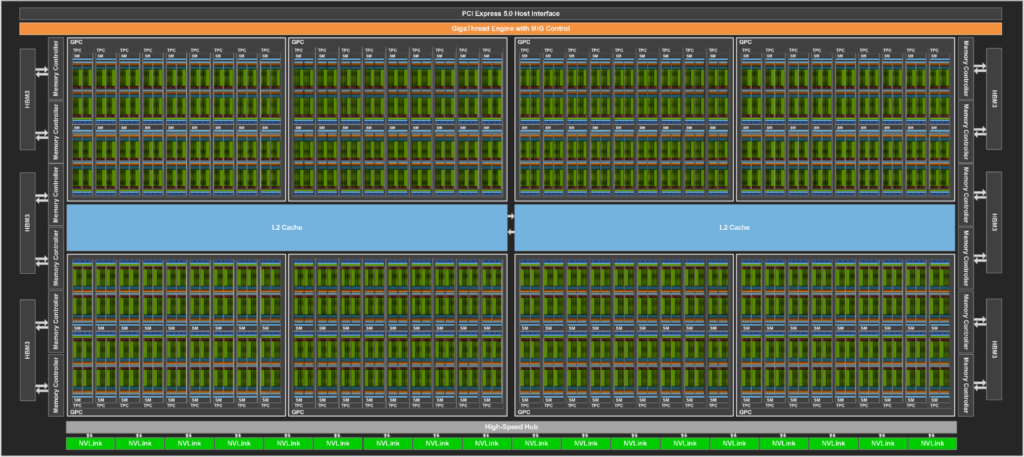
2020年,NVIDIA推出Ampere架构,采用TSMC 7nm FFN工艺,面积826mm^2,一共542亿晶体管;完整GA100物理版图如下所示:
 Ampere GPU 中两个 SM 共同组成一个纹理处理器集群TPC,其中 8 个 TPC组成了一个GPU 处理集群(GPC);一共 8 个GPC。因此,GA100 GPU 的完整实现包括以下单元:
Ampere GPU 中两个 SM 共同组成一个纹理处理器集群TPC,其中 8 个 TPC组成了一个GPU 处理集群(GPC);一共 8 个GPC。因此,GA100 GPU 的完整实现包括以下单元:
- 8 个 GPC,每个GPC有8 个 TPC,每个TPC有2 个 SM,一共128 个 SM
- 每个SM有64 个 FP32 CUDA 核,每个完整 GPU 8192 个 FP32 CUDA 核
- 每个SM有4 个第三代 Tensor Core,每个完整 GPU 512 个 Tensor Core
- 6 个 HBM2,12 个 512 位内存控制器 A100 基于 GA100,有 108 个 SM;A100 Tensor Core GPU 实现包括以下单元:
- 7 个 GPC,每个GPC有7 或 8 个 TPC,每个TPC有2 个 SM,最多108 个 SM
- 每个 SM有 64 个 FP32 CUDA 核,一共6912 个 FP32 CUDA 核
- 每个SM有4 个第三代 Tensor Core,每个 GPU 432 个Tensor Core
- 5 个 HBM2,10 个 512 位内存控制器
SM
每个SM有192 KB 的共享内存和 L1 数据缓存组合;与 V100 和 Turing GPU 类似,A100 SM 还包括单独的 FP32 和 INT32 核,允许同时执行 FP32 和 INT32 操作;许多应用程序都具有执行指针算术计算(整数内存地址计算)的内部循环,这些浮点计算受益于同时执行 FP32 和 INT32 指令。流水线循环的每次迭代都可以更新地址(INT32 指针算术)并加载下一次迭代的数据,同时在 FP32 中处理当前迭代。另外,SM主要增加一些指令和功能包括:
- 增加新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过 L1 缓存,并且无需使用中间寄存器文件 (RF)。异步复制可减少寄存器文件带宽,更有效地利用内存带宽,并降低功耗。顾名思义,当 SM 执行其他计算时,可以在后台完成异步复制
- 用于新的异步复制指令的基于共享内存的屏障单元(异步屏障)。这些屏障可使用 CUDA 11 以符合 ISO C++ 的屏障对象的形式获得。异步屏障将屏障到达和等待操作分开,可用于从全局内存到共享内存的异步复制与 SM 中的计算重叠。可借助这些屏障使用 CUDA 线程实现生产者-消费者模型。屏障还提供了以不同粒度同步 CUDA 线程的机制,而不仅仅是warp或块级别
- L2 缓存管理和驻留控制的新指令
- CUDA Cooperative Groups 支持的新warp级reduction指令。
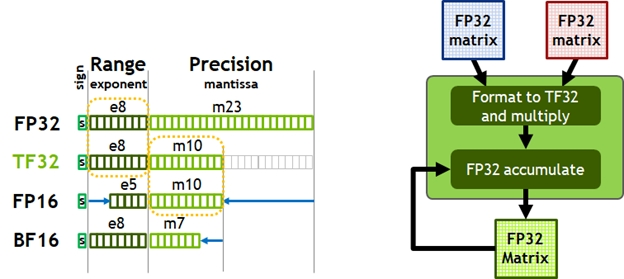
 Volta 和 Turing 每个 SM 有 8 个 Tensor Core,每个 Tensor Core 每个时钟执行 64 个 FP16/FP32 混合精度融合乘加 (FMA) 运算。A100 SM 包括新的第三代 Tensor Core,每个核每个时钟执行 256 个 FP16/FP32 FMA 操作;每个 SM 有四个 Tensor Core,每个时钟总共提供 1024 次密集的 FP16/FP32 FMA 操作。Tensor Core支持数据类型包括 FP16、BF16、TF32、FP64、INT8、INT4 和 Binary。Ampere 架构引入了对 TF32 的支持,使 AI 训练能够默认使用张量核心,而无需用修改。非张量运算继续使用 FP32 数据路径,而 TF32 张量核心读取 FP32 数据并使用与 FP32 相同的范围,但内部精度降低,然后生成标准 IEEE FP32 输出。TF32 包括一个 8 位指数(与 FP32 相同)、10 位尾数(与 FP16 相同精度)和 1 个符号位。
Volta 和 Turing 每个 SM 有 8 个 Tensor Core,每个 Tensor Core 每个时钟执行 64 个 FP16/FP32 混合精度融合乘加 (FMA) 运算。A100 SM 包括新的第三代 Tensor Core,每个核每个时钟执行 256 个 FP16/FP32 FMA 操作;每个 SM 有四个 Tensor Core,每个时钟总共提供 1024 次密集的 FP16/FP32 FMA 操作。Tensor Core支持数据类型包括 FP16、BF16、TF32、FP64、INT8、INT4 和 Binary。Ampere 架构引入了对 TF32 的支持,使 AI 训练能够默认使用张量核心,而无需用修改。非张量运算继续使用 FP32 数据路径,而 TF32 张量核心读取 FP32 数据并使用与 FP32 相同的范围,但内部精度降低,然后生成标准 IEEE FP32 输出。TF32 包括一个 8 位指数(与 FP32 相同)、10 位尾数(与 FP16 相同精度)和 1 个符号位。
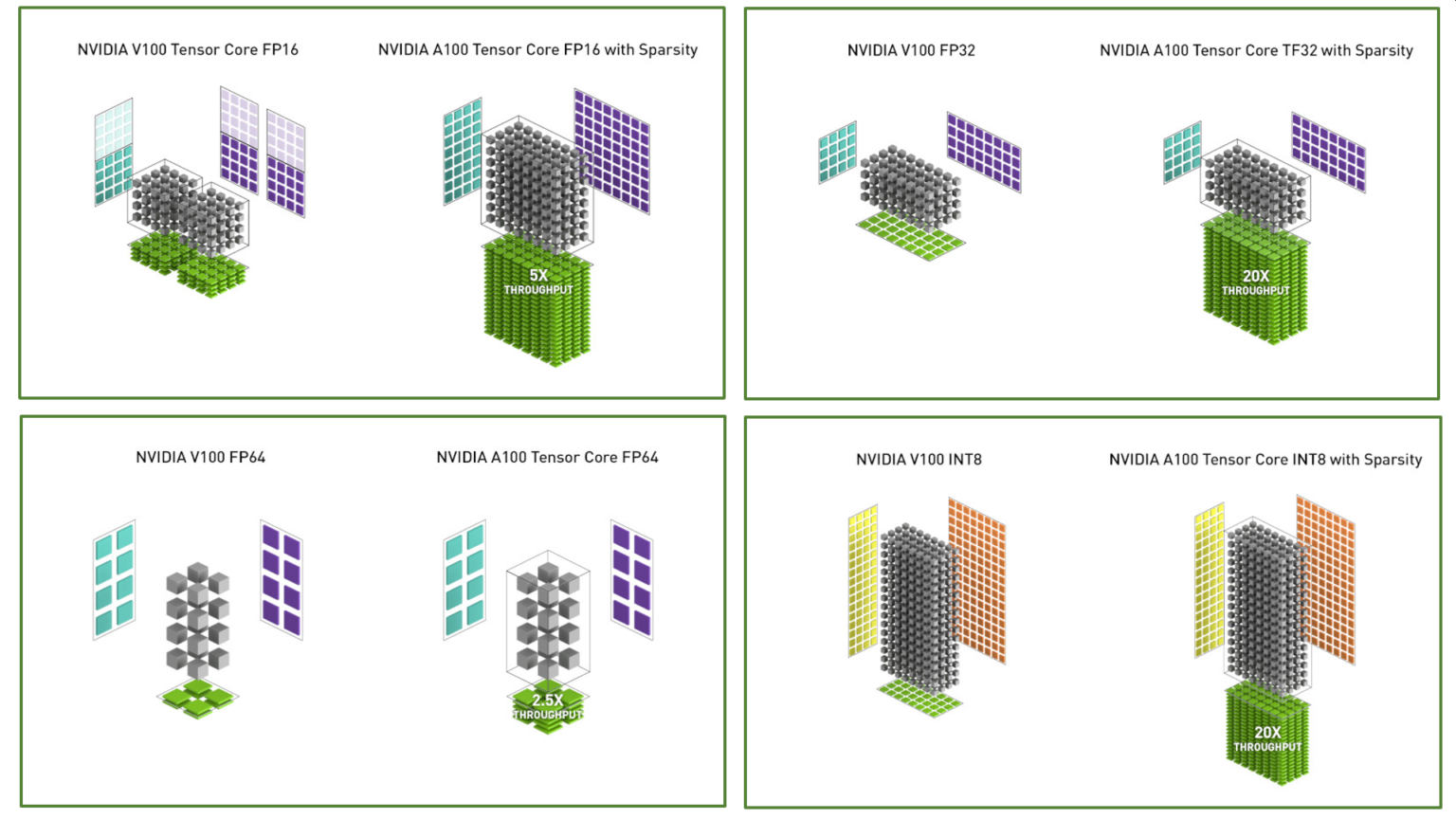
 下图比较了 V100 和 A100 FP16 Tensor Core 操作,并将 V100 FP32、FP64 和 INT8 标准操作与 A100 TF32、FP64 和 INT8 Tensor Core 操作进行了比较。
下图比较了 V100 和 A100 FP16 Tensor Core 操作,并将 V100 FP32、FP64 和 INT8 标准操作与 A100 TF32、FP64 和 INT8 Tensor Core 操作进行了比较。
 Tensor Core还支持FP64计算,新的双精度矩阵乘加指令取代了 V100 上的 8 条 DFMA 指令,从而减少了取指,调度,寄存器读取开销,以及数据路径功耗和共享内存读取带宽。每个 SM 每周期可计算 64 个 FP64 FMA(或 128 个 FP64 操作)。
Tensor Core还支持FP64计算,新的双精度矩阵乘加指令取代了 V100 上的 8 条 DFMA 指令,从而减少了取指,调度,寄存器读取开销,以及数据路径功耗和共享内存读取带宽。每个 SM 每周期可计算 64 个 FP64 FMA(或 128 个 FP64 操作)。
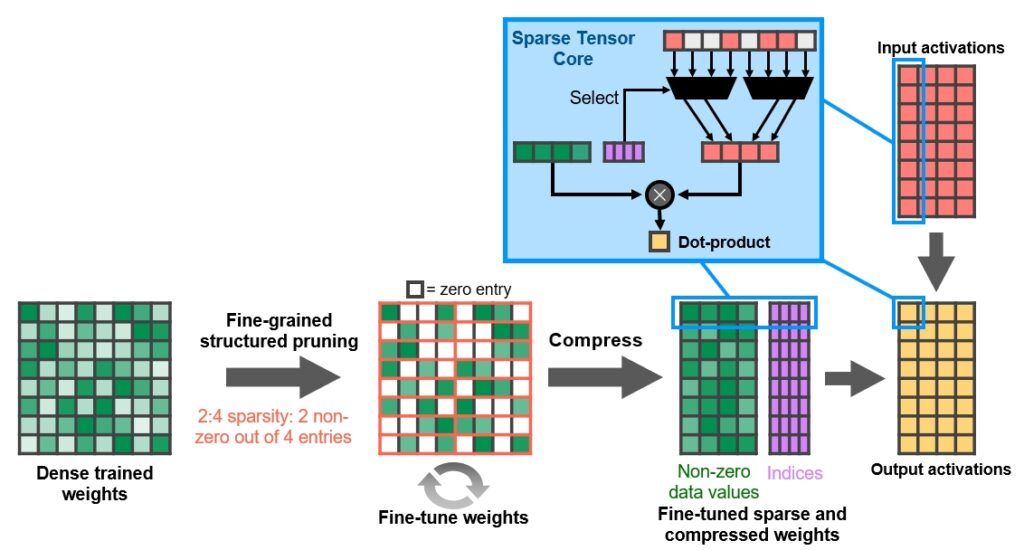
A100 Tensor Core GPU 包含新的稀疏 Tensor Core 指令,这些指令跳过对值为零的条目的计算,从而使 Tensor Core 计算吞吐量翻倍。通过新的 2:4 稀疏矩阵定义支持稀疏计算,该定义允许在每个四输入向量中有两个非零值。A100 支持行上 2:4 的结构稀疏性,如图所示:
 NVIDIA 开发了一种简单而通用的方法使用这种 2:4 结构化稀疏模式进行推理。首先使用密集权重对网络进行训练,然后应用细粒度的结构化剪枝,最后通过额外的训练步骤对剩余的非零权重进行微调。
NVIDIA 开发了一种简单而通用的方法使用这种 2:4 结构化稀疏模式进行推理。首先使用密集权重对网络进行训练,然后应用细粒度的结构化剪枝,最后通过额外的训练步骤对剩余的非零权重进行微调。
内存结构
A100 GPU 包括 40 MB 的L2缓存; L2 缓存分为两个分区,以实现更高的带宽和更低的访问延迟。每个 L2 分区本地化缓存直接连接的 GPC 中的 SM 内存访问数据。相比V100,A100 能够提供2.3 倍的 L2 带宽。硬件缓存一致性在整个 GPU 上维护 CUDA 编程模型。L2 缓存是 GPC 和 SM 的共享资源,位于 GPC 之外。
为了优化容量利用率, Ampere 架构提供了L2缓存驻留控制,可以管理要保留或从缓存中逐出的数据,可以留出一部分 L2 缓存用于持久性数据访问。例如,对于深度推理工作,可以将乒乓缓冲区永久缓存在 L2 中,以便更快地访问数据,同时避免写回 DRAM。对于深度训练中生产者-消费者链,L2 缓存控制可以优化写入读取数据依赖项的缓存。在 LSTM 网络中,可以优先循环权重缓存并在 L2 中重用。
Ampere 架构增加了计算数据压缩功能,以加速非结构化稀疏性和其他可压缩数据模式。L2 压缩可将 DRAM 读/写带宽提高 4 倍,将 L2 容量提高 2 倍。 采用SXM4 的A100 GPU包括 40 GB HBM2,分为五个HBM2,每个有八个存储器芯片;在1215 MHz (DDR) 数据速率下,A100 HBM2 可提供 1555 GB/s的内存带宽。
虚拟化
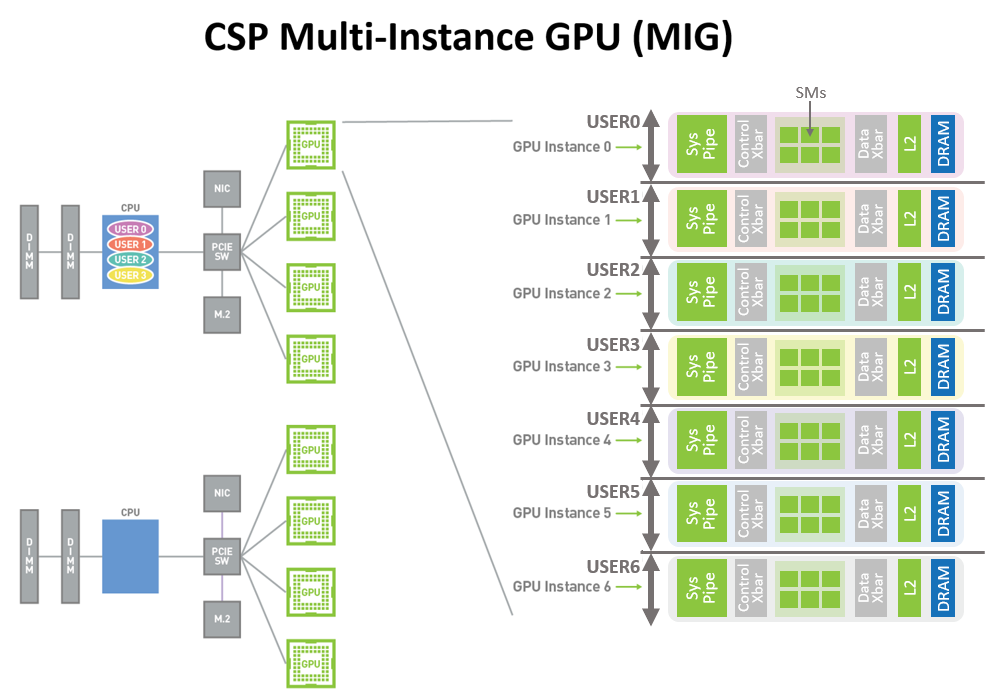
新的MIG-Multi-Instance (GPU) 功能允许将 A100安全地划分为多达 7 个独立的 GPU 实例,为多个用户提供单独的 GPU 资源来加速应用程序。使用 MIG,每个实例的处理器在整个内存系统中都有独立且隔离的路径。片上交叉端口、L2 缓存组、内存控制器和 DRAM 地址总线都唯一分配给单个实例。这可确保单个用户的工作负载能够以可预测的吞吐量和延迟运行,并具有相同的 L2 缓存分配和 DRAM 带宽。
MIG 可提高 GPU 硬件利用率,同时在不同客户端(如 VM、容器和进程)之间提供确定的 QoS 和隔离。MIG 对于具有多租户用例的 CSP(Cloud Service Provider) 特别有益,可以确保一个客户端不会影响其他客户端的工作或调度,提供增强的安全性并保证客户的 GPU 利用率。下图所示的 A100 GPU 新 MIG 功能可以将单个 GPU 划分为多个 GPU 分区,称为 GPU instances.
RAS
Ampere 架构 A100 GPU 包括改进错误/故障归因(归因于导致错误的应用程序)、隔离(隔离故障应用程序,以便它们不会影响在同一 GPU 或 GPU 集群中运行的其他应用程序)和包含(确保一个应用程序中的错误不会泄漏并影响其他应用程序)的新技术。这些故障处理技术对于 MIG 尤为重要,可确保共享单个 GPU 的客户端之间的适当隔离和安全性。
使用NVLink 连接的 GPU 有强大的错误检测和恢复功能。远程 GPU 上的页面错误通过 NVLink 发送回源 GPU。远程访问故障通信是大型 GPU 计算集群的一项关键复原功能,可帮助确保一个进程或虚拟机中的故障不会导致其他进程或虚拟机瘫痪。
同时HBM2支持SECDEC(single-error correcting double-error detection),GPU内部L2缓存,L1缓存和寄存器文件也都是用SECDEC进行保护。
2.13 Hopper
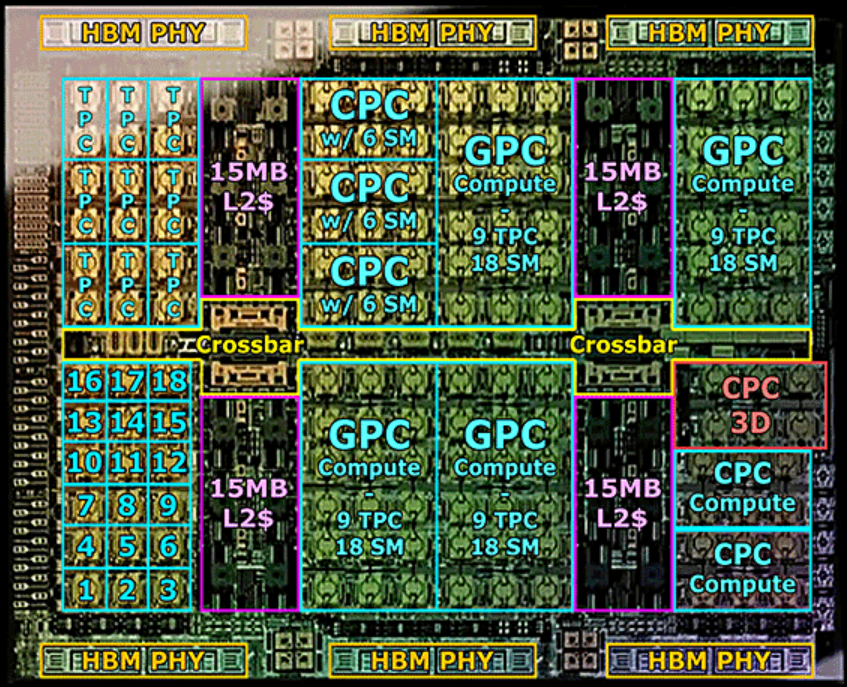
2022年,NVIDIA推出Hopper架构,H100采用台积电4nm工艺,面积814mm^2,一共800亿晶体管;下图是H100的物理版图:
完整的Hopper架构包括
- 8个GPCs, 72 个TPCs (9 TPCs/GPC), 一共144个 SMs(2 SMs/TPC)
- 每个SM有128个 FP32 CUDA核, 一共18432 个FP32 CUDA核
- 每个SM有4个第四代Tensor Core,一共576个
- 6个 HBM3或HBM2e, 12 个512位的内存控制器
- 60 MB的 L2缓存
- NVLink 4.0和PCIe Gen 5
采用SXM5的H100 GPU包括:
- 8个 GPCs, 66个 TPCs, 一共132个 SMs(2 SMs/TPC)
- 每个SM有128个 FP32 CUDA核, 一共16896个 FP32 CUDA核
- 每个SM有4个第四代Tensor Core,一共528个
- 5个 HBM3,12 个512位的内存控制器,一共80 GB HBM3
- 50 MB的 L2缓存
- NVLink 4.0 和PCIe Gen 5
采用PCIe Gen 5的H100 GPU包括:
- 7或8 个GPCs, 57个 TPCs, 一共114 SM
- 每个SM有128个 FP32 CUDA核, 一共14592个 FP32 CUDA核
- 每个SM有4个第四代Tensor Core, 一共456个
- 5个 HBM2e,12 个512位的内存控制器,一共80 GB HBM2e
- 50 MB的 L2缓存
- NVLink 4.0 和PCIe Gen 5
SXM5 和 PCIe H100 GPU 中只有两个 TPC 支持图形处理(即可以运行顶点、几何体和像素着色器)。下图展示了完整的H100的架构框图:

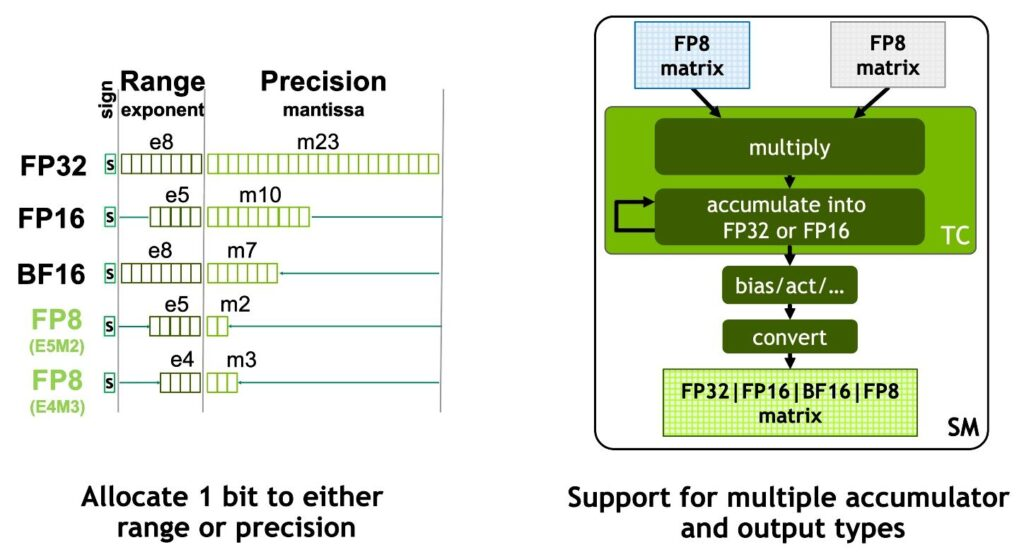
 H100 Tensor Core支持 FP8、FP16、BF16、TF32、FP64 和 INT8数据类型。FP8是H100 Tensor Core新支持的数据类型。如下图所示,Tensor Core 支持 FP32 和 FP16 累加器,以及两种新的 FP8 输入类型:
H100 Tensor Core支持 FP8、FP16、BF16、TF32、FP64 和 INT8数据类型。FP8是H100 Tensor Core新支持的数据类型。如下图所示,Tensor Core 支持 FP32 和 FP16 累加器,以及两种新的 FP8 输入类型:
- E4M3 有 4 个指数位、3 个尾数位和 1 个符号位
- E5M2 有 5 个指数位、2 个尾数位和 1 个符号位
 E4M3 支持需要更小动态范围和更高精度的计算,而 E5M2 提供更宽的动态范围和更低的精度。与 FP16 或 BF16 相比,FP8 将数据存储要求减半,吞吐量翻倍。
E4M3 支持需要更小动态范围和更高精度的计算,而 E5M2 提供更宽的动态范围和更低的精度。与 FP16 或 BF16 相比,FP8 将数据存储要求减半,吞吐量翻倍。
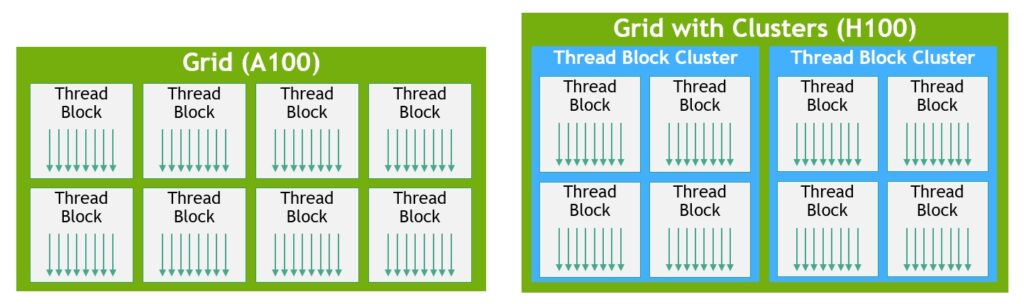
线程块集群(Thread block cluster)功能支持以编程方式控制局部性,其粒度大于单个SM上的单个线程块。这扩展了 CUDA 编程模型,向编程层次结构添加了另一个级别,包括线程、线程块、线程块集群和网格。线程块集群支持跨多个 SM 同时运行的多个线程块,以同步和协作方式获取和交换数据。CUDA 编程模型使用包含多个线程块的网格来利用程序中的局部性。线程块包含在单个 SM 上并发运行的多个线程,其中线程可以使用屏障同步,利用SM 的共享内存交换数据。然而,随着 GPU 增长到 100个 SM 以上,计算程序变得越来越复杂,线程块作为编程模型中唯一局部性单位不足以最大限度地提高执行效率。
线程块集群是一组线程块,保证并发调度到一组 SM 上,其目标是实现跨多个 SM 的线程的高效协作。H100 中的线程块集群在 GPC 内的 SM 之间并发运行。GPC 是硬件层次结构中的一组 SM,在物理上始终靠得很近。线程块群集具有硬件加速屏障和新的内存访问协作功能。GPC 中 SM 使用专用 SM 到 SM 网络在集群中的线程之间提供快速数据共享。在 CUDA 中,网格中的线程块可以选择在线程块启动时分组到集群中,通过CUDA cooperative_groups 使用集群功能。下图左边是由传统 CUDA 编程模型中的线程块组成的网格,右边则是H100的集群层次结构。
分布式共享内存(DSMEM) 允许跨多个 SM 共享内存块进行直接 SM 到 SM 的加载、存储和原子通信。在一个线程块集群,所有线程都可以通过加载、存储和原子操作直接访问其他 SM 的共享内存。DSMEM 支持更高效的 SM 之间的数据交换,不再需要写入和读取全局内存来传递数据。集群专用的 SM 到 SM 网络可确保快速、低延迟地访问远程 DSMEM。与使用全局内存相比,DSMEM 将线程块之间的数据交换速度提高了约 7 倍。
 在 CUDA 中,集群中所有线程块的所有 DSMEM 段都映射到每个线程的通用地址空间中,因此可以使用简单的指针直接引用所有 DSMEM。CUDA 用户可以利用
在 CUDA 中,集群中所有线程块的所有 DSMEM 段都映射到每个线程的通用地址空间中,因此可以使用简单的指针直接引用所有 DSMEM。CUDA 用户可以利用 cooperative_groups API 构建指向集群中任何线程块的通用指针。DSMEM 传输也可以表示为异步复制操作,使用共享内存的屏障同步。
动态规划DP (Dynamic programming) 动态规划 (DP) 通过将复杂的递归问题分解为更简单的子问题来解决复杂的递归问题。通过存储子问题的结果,无需在以后需要时重新计算它们,DP 算法将指数问题集的计算复杂度降低到线性尺度。DP 通常用于广泛的优化、数据处理和基因组学算法。H100 引入了 DPX 指令,与 Ampere相比,DP 算法的性能提高了 7 倍。这些新指令为许多 DP 算法的内循环提供了对高级融合操作数的支持。
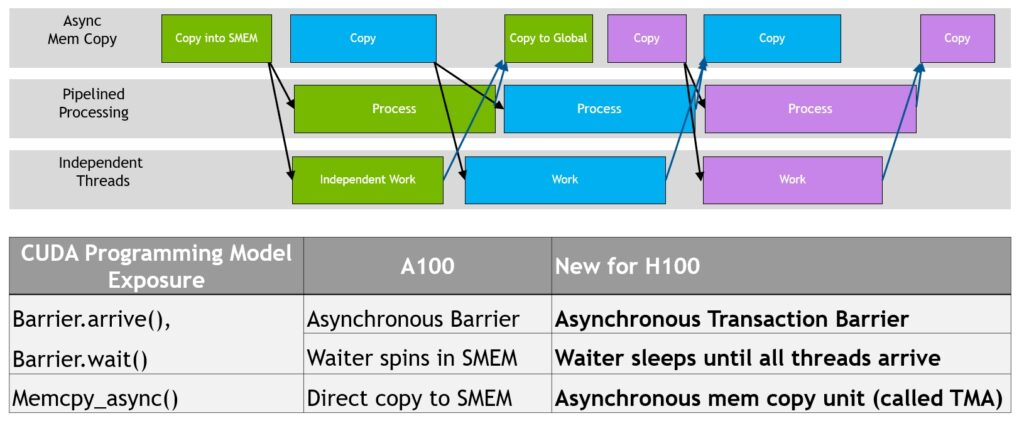
异步执行(Asynchronous execution) Hopper 架构改进了异步执行,并使内存复制与计算和其他独立任务进一步重叠,同时最大限度地减少同步点;主要是张量内存加速器TMA (Tensor Memory Accelerator)和异步事务屏障(asynchronous transaction barrier)。
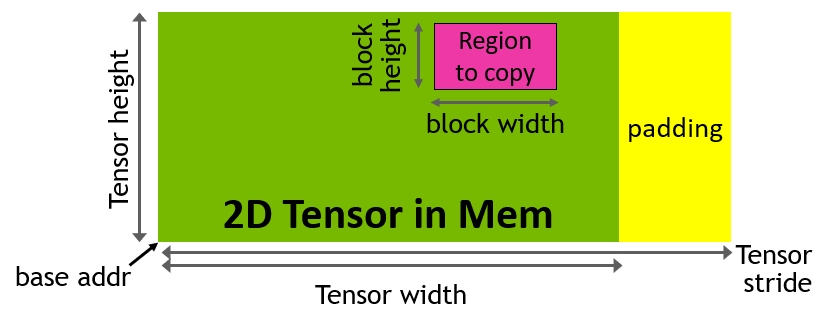
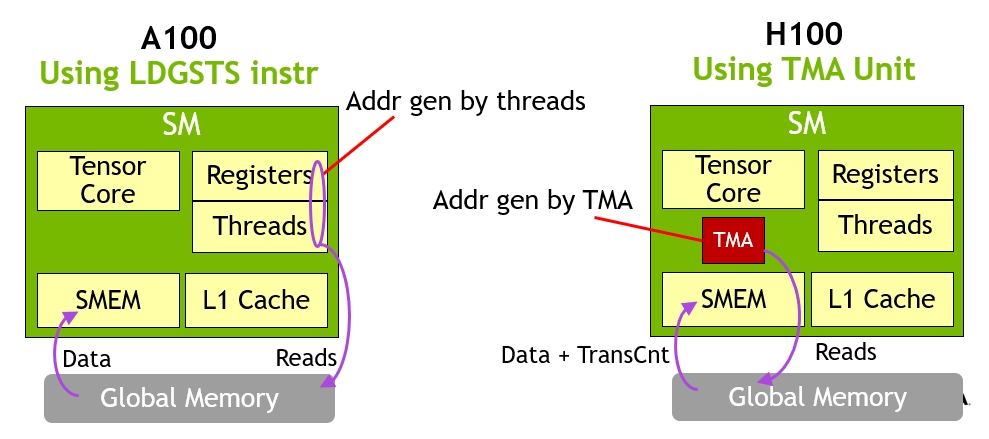
TMA(Tensor Memory Accelerator) Tensor Memory Accelerator(TMA)可以在全局内存和共享内存之间传输大块数据和多维张量,满足Tensor Core对数据的需求。TMA 操作使用复制描述符启动,该描述符使用张量维度和块坐标而不是每个元素寻址来指定数据传输。可以指定高达共享内存容量的大数据块,并将其从全局内存加载到共享内存中,或者从共享内存存储回全局内存。TMA 通过支持不同的张量维度(1D-5D 张量)、不同的内存访问模式、reduction等功能,降低寻址开销并提高效率。
 TMA 操作是异步的,并利用 A100 中引入的基于共享内存的异步屏障。此外,TMA 编程模型是单线程的,warp 中的单个线程被选择发出异步 TMA 操作(
TMA 操作是异步的,并利用 A100 中引入的基于共享内存的异步屏障。此外,TMA 编程模型是单线程的,warp 中的单个线程被选择发出异步 TMA 操作(cuda::memcpy_async )来复制张量。因此,多个线程可以使用cuda::barrier等待数据传输完成。TMA 的优势是释放了线程来执行其他独立工作。在 A100上,异步内存复制使用特殊的LoadGlobalStoreShared指令执行,因此线程负责生成所有地址并在整个复制区域中循环。在 Hopper 上,TMA 负责处理一切。单个线程在启动 TMA 之前创建复制描述符,从那时起,地址生成和数据移动将在硬件中处理。TMA 提供了一个更简单的编程模型,因为它在复制张量段时接管了计算步幅、偏移和边界计算的任务。
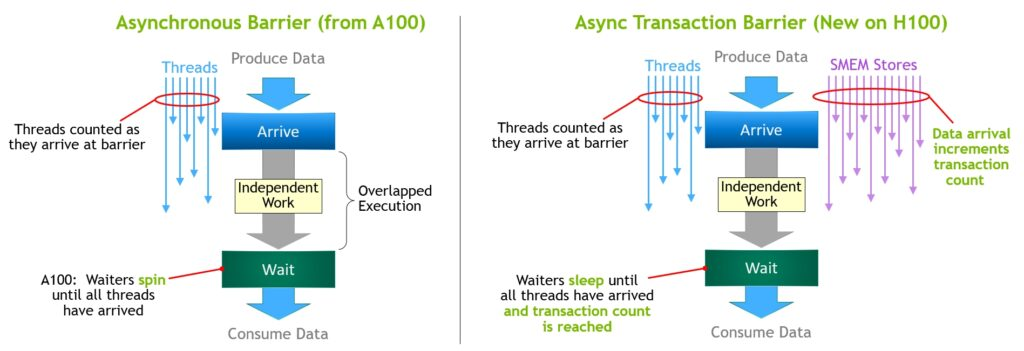
异步事务屏障(Asynchronous transaction barrier) 异步屏障最初是在 NVIDIA Ampere 架构中引入的。比如,一组线程在生成数据,并在屏障之后使用这些数据。异步屏障将同步过程分为两个步骤:
- 首先,当线程生成完其共享数据时,会发出
Arrive信号。此Arrive是非阻塞的,因此线程可以自由地执行其他独立任务 - 最终,当线程需要所有其他线程生成的数据时,线程会执行
Wait,这会阻止线程,直到每个线程都发出Arrive信号
异步屏障的优点是在等待时提前到达的线程能够执行独立工作,这种重叠提高了性能。如果有足够的独立执行的线程,则屏障会变得很轻量,因为Wait指令可以立即退休。Hopper 的新功能是 waiting 线程能够休眠,直到所有其他线程到达。在之前架构,等待线程会在共享内存中的屏障对象上spin。
Hopper增加了称为异步事务屏障(asynchronous transaction barrier)的新形式的屏障。异步事务障碍类似于异步障碍,是一个拆分屏障,不仅计算线程到达,还计算事务。Hopper 包含一个用于写入共享内存的新命令,该命令可传递要写入的数据和事务计数。事务计数实质上是一个字节计数。异步事务屏障在Wait命令下阻止线程,直到所有生产者线程都执行了Arrive,并且所有事务计数的总和达到预期值。异步事务屏障是异步内存复制或数据交换的新原语。集群可以进行线程块到线程块的通信,用于具有隐含同步的数据交换,并且集群功能建立在异步事务屏障之上。
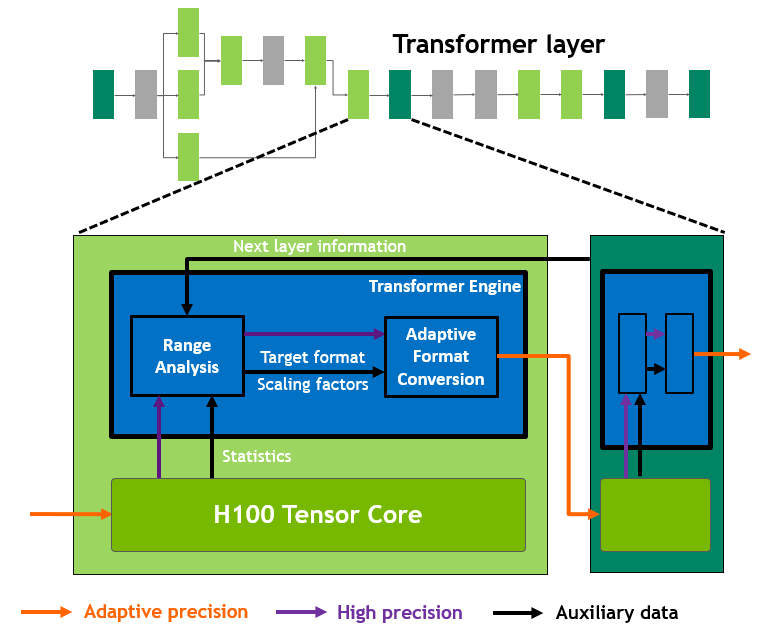
Transformer Engine H100 包括一个新的 Transformer 引擎,使用软件和NVIDIA Hopper Tensor Core 技术来加速 Transformer 的 AI 计算。
 在 Transformer 模型的每一层,Transformer 引擎都会分析 Tensor Core 输出值的统计数据。在了解接下来是哪种类型的神经网络层以及它所需的精度后,transformer engine还可以在将张量存储到内存之前决定将张量转换为哪种目标格式。为了以最佳方式使用可用范围,Transformer engine还使用从张量统计数据计算出的缩放因子将张量数据动态缩放到可表示的范围内。因此,每一层都完全按照其所需的数据范围运行。
在 Transformer 模型的每一层,Transformer 引擎都会分析 Tensor Core 输出值的统计数据。在了解接下来是哪种类型的神经网络层以及它所需的精度后,transformer engine还可以在将张量存储到内存之前决定将张量转换为哪种目标格式。为了以最佳方式使用可用范围,Transformer engine还使用从张量统计数据计算出的缩放因子将张量数据动态缩放到可表示的范围内。因此,每一层都完全按照其所需的数据范围运行。
内存结构
H100 有 50 MB L2 缓存,并使用分区crossbar,缓存直接连接到分区的 GPC 中的 SM 的本地内存访问数据。L2 缓存驻留控制(residency control)可优化容量利用率,有选择地管理缓存中保留在或被逐出的数据。H100 SXM5 GPU 支持 80 GB(五个堆栈)HBM3 内存,提供超过 3 TB/秒的内存带宽;PCIe H100 提供 80 GB 的HBM2e,内存带宽超过 2 TB/秒。HBM3 或 HBM2e DRAM 和 L2 缓存子系统都支持数据压缩和解压缩技术,以优化内存和缓存的使用率和性能。
2.14 Blackwell
Introduced at NVIDIA GTC 2024, the NVIDIA Blackwell architecture is a new class of AI superchip. Crafted with 208 billion transistors, and using the TSMC 4NP process tailored for NVIDIA, it is the largest GPU ever built. The Blackwell architecture also features the new second-generation Transformer Engine, which uses new Blackwell Tensor Core technology combined with TensorRT-LLM innovations, to enable fast and accurate FP4 AI inference.
NVIDIA GB200 Superchip Incl. Two Blackwell GPUs and One Grace CPU
3 AMD
下图展示了AMD GPU 架构的发展变迁历史:

- AMD的GPU的架构始于2008年的Terascale,一共发展了三代,到2010年的Terascale 3;AMD 的 TeraScale 专为可编程图形时代而设计,并通过 DirectX 11 的 DirectCompute API 和基于 VLIW 的架构引入了通用计算。
- TeraScale 3 (VLIW4) 用 4 路 VLIW 设计取代了之前的 5 路 VLIW 设计;还包含一个额外的曲面细分单元,以提高 Direct3D 11 性能。TeraScale 3 在 Radeon HD 6900 中引入。
- 2012年,AMD转向GCN(Graphics Core Next)架构,并持续演进到GCN4;GCN(Graphics Core Next ) 架构转向了更具可编程性的交织向量计算模型,并引入了异步计算,使传统图形和通用计算能够高效地协同工作。
- 2019年,随着对通用计算的性能的追求,发展出了两种架构:
- 针对游戏进行优化,以最大限度地提高每秒帧数的AMD RDNA
- 针对计算进行优化,以突破每秒 flops 极限的CDNA 。CDNA删除了加速图形任务的固定功能硬件,例如光栅化、曲面细分、图形缓存、混合,甚至显示引擎;保留了用于 HEVC、H.264 和 VP9 解码的专用逻辑,用于处理多媒体数据的计算工作负载,例如用于对象检测的机器学习。
新的CDNA架构通过新的矩阵计算引擎增强了标量和向量处理,并添加了 Infinity Fabric 技术以扩展到更大的系统,同时提供开放式 ROCm 生态系统开发应用程序。
下图展示了AMD 的 GPU 架构从固定功能到RDNA/CDNA的演进:

| CDNA | CDNA 2 | CDNA 3 | CDNA 4 | |
| 工艺技术 | 7nm FinFET | 6nm FinFET | 5nm + 6nm FinFET | 3nm + 6nm FinFET |
| 晶体管数 | 256 亿 | 最高可达 580 亿 | 最高可达 1460 亿 | 最高可达 1850 亿 |
| 计算单元数 | 矩阵核心数 | 120 | 440 | 最高可达 220 | 880 | 最高可达 304 | 1216 | 256 | 1024 |
| 内存类型 | 32GB | 最高可达 128GB | 最高可达 256GB | 288 GB |
| HBM2 | HBM2E | HBM3 | HBM3E | HBM3E | |
| 内存带宽(峰值) | 1.2 TB/s | 最高可达 3.2 TB/s | 最高可达 6 TB/s | 8 TB/s |
| AMD Infinity Cache | N/A | N/A | 256 MB | 256 MB |
| GPU 一致性 | N/A | 高速缓存 | 高速缓存和 HBM | 高速缓存和 HBM |
| 支持的数据类型 | INT4、INT8、BF16、FP16、FP32、FP64 | INT4、INT8、BF16、FP16、FP32、FP64 | INT8、FP8、BF16、FP16、TF32、FP32、FP64(支持稀疏性) | INT4、FP4、FP6、INT8、FP8、BF16、FP16、TF32*、FP32、FP64(支持稀疏性) |
| 产品 | AMD Instinct MI100 系列 | AMD Instinct MI200 系列 | AMD Instinct MI300 系列 | AMD Instinct MI350 系列 |
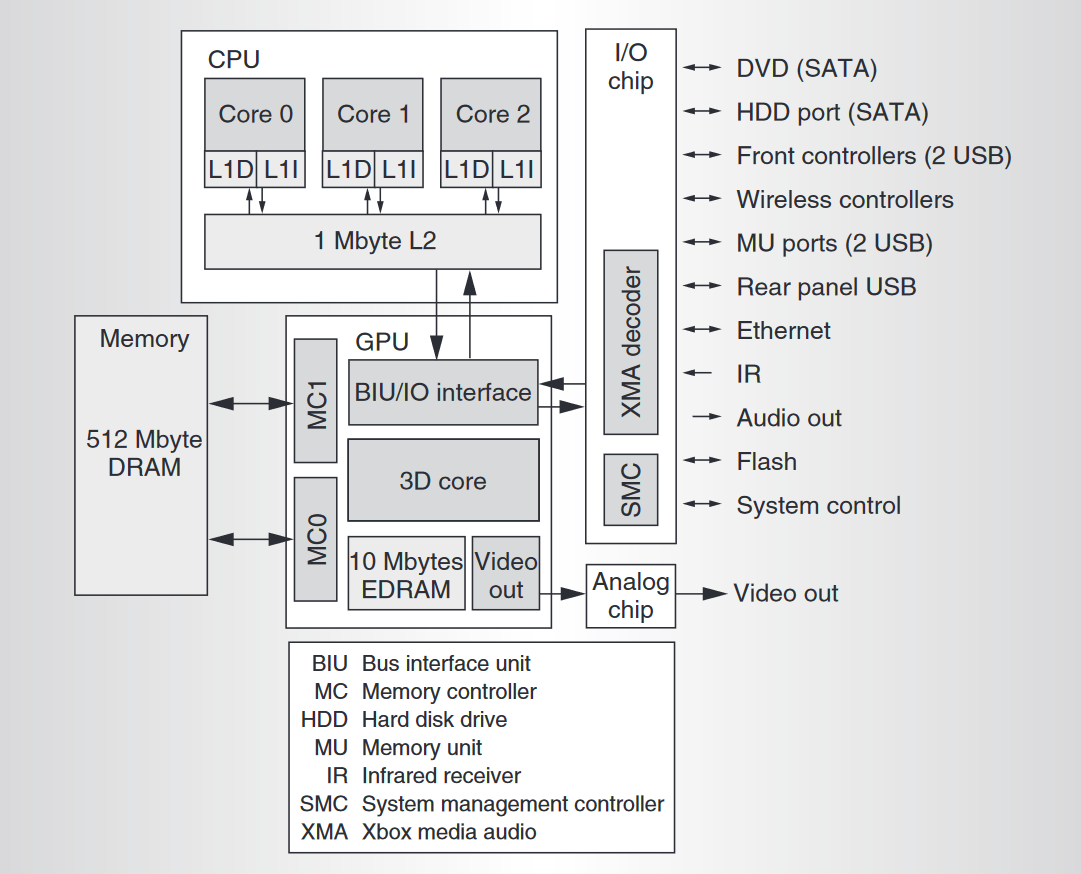
3.1 Xbox 360
2006 年,Xbox 360 搭载的处理器包括3个 CPU 核、48 个统一着色器和 512 MB DRAM 主内。下图显示了 Xbox 360 系统核心芯片组件的框图:
- 3个相同的 CPU 核共享一个 8 路组关联的 1 MB 二级缓存,运行频率为 3.2 GHz。每个核都包含四路SIMD向量单元。
- GPU 3D 核有 48 个并行的统一着色器。
- GPU 还包括 10 MB 嵌入式 DRAM (EDRAM),带宽 256 GB/s,提供可靠的帧和 z 缓冲带宽。
- 由 GPU 控制的 512 MB 统一主内存GDDR3工作在 700 MHz ,工作速率为 1.4 Gbit/pin/s,总带宽为 22.4 GB/s。
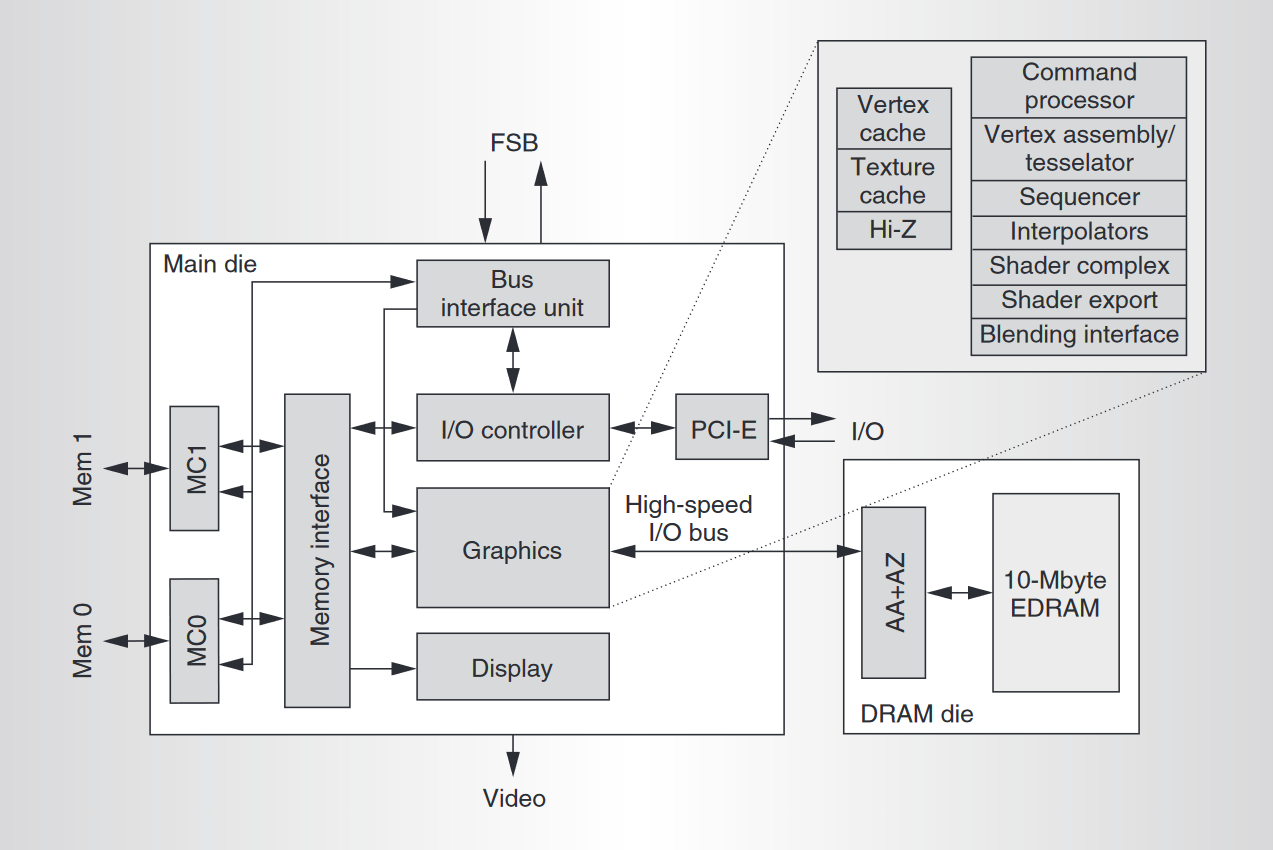
下图显示了 Xbox 360 GPU系统的结构框图:
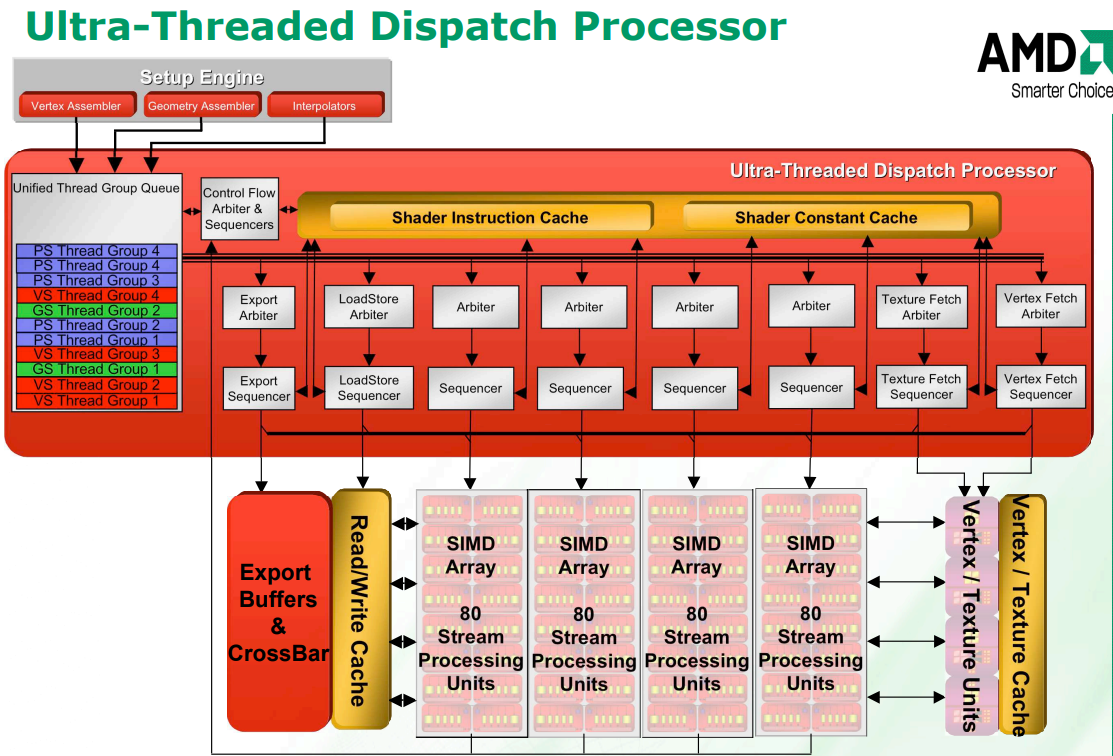 GPU 由以下功能模块组成:
GPU 由以下功能模块组成:
- 总线接口单元(BIU) ,和FSB连接,处理 CPU 发起的事务,以及 GPU 发起的事务,例如侦听和 L2 缓存读取
- I/O 控制器,处理所有内部存储器映射的 I/O 访问,以及通过双通道 PCI-Express 总线 (PCI-E) 与 I/O 芯片之间的事务
- 内存控制器(MC0、MC1),GDDR3 内存控制器,128 字节交织,包含用于图形的激进地址分片和减少 CPU 延迟的快速路径
- 内存接口 内存crossbar和非 CPU 传输(如图形、I/O 和显示器)的缓冲。
- 图形 芯片上最大的模块,包含渲染引擎
- 高速 I/O 总线 图形内核和 EDRAM 芯片之间是芯片到芯片总线(通过基板),工作频率为 1.8 GHz ,提供 28.8 GB/s带宽。当使用多采样抗锯齿时,仅传输像素中心数据和覆盖率信息,然后在 EDRAM 芯片上扩展 • 抗锯齿和 Alpha/A (AA+AZ)处理像素到样本的扩展,以及 z 检验和 alpha 混合。
- 视频显示
下图显示了 GPU和 EDRAM的物理版图。GPU芯片采用台积电 90 纳米工艺,包含 2.32 亿个晶体管。EDRAM 芯片采用NEC 90nm 工艺,包含 1 亿个晶体管。
- GPU来自ATI,运行频率为 500 MHz,由 48 个并行、组合向量和标量着色器 ALU 组成;着色器单元分为三个 SIMD 组,每个组有 16 个处理器,总共有 48 个处理器。
- 每个处理器有一个 5 宽向量单元(总共 5 个 FP32 ALU,一共 240 个单元)组成,每个周期最多可以串行执行两条指令(乘法和加法)。
- SIMD 组中的所有处理器都执行相同的指令,因此总共最多可以同时执行三个指令线程。
- 与早期的图形引擎不同,着色器是动态分配的,这意味着没有不同的顶点或像素着色器引擎——硬件会根据负载自动进行细粒度调整。
- ALU 是 32 位 浮点 ALU,遵循IEEE 754 标准,在舍入模式、非规范化数字(读取时刷新为零)、NaN 处理和异常处理等方面符合图形常见的处理。ALU具有单周期的向量(包括点积)和标量运算。超标量指令在一个指令中对向量、标量、纹理加载和顶点提取进行编码,因此在获取纹理和顶点时,每个周期进行 96 个着色器计算。
- 16 个纹理获取引擎为着色器提供数据,每个引擎能够在每个周期中生成过滤结果。
- 16 个具有内置曲面细分的可编程顶点提取引擎,可以使用它们来代替 CPU 几何生成。
- 16 个插值器。渲染后端可以维持每个周期 8 个像素或每个周期 16 个像素,用于深度和仅模具渲染(用于 z-prepass 或阴影缓冲区)。
- 专用的 z 或混合逻辑和 EDRAM 保证即使在 4× 抗锯齿和透明度下,每个周期也能保持 8 个像素。z-prepass 是一种对命令列表执行首遍渲染的技术,除了遮挡确定外,不应用任何渲染功能。z-prepass 初始化 z-buffer,以便在应用完整纹理和着色器的后续渲染通道中,丢弃的像素不会在被遮挡的像素上花费着色器和纹理资源。借助现代场景深度的复杂性,此技术可显著提高渲染性能,尤其是对于复杂的着色器程序。
3.2 TeraScale 1
2008年,ATI推出了TeraScale的全新架构,应用在Radeon HD 2000系列产品。这是ATI的第一个统一着色器架构,也是ATI与AMD合并后推出的第一个设计。TeraScale旨在与Pixel Shader 4.0和Microsoft的DirectX 10.0 API完全兼容。下图是Radeon HD 2000的结构框图:
 TeraScale是继 XBOX 360 图形处理器之后统一着色器架构:
TeraScale是继 XBOX 360 图形处理器之后统一着色器架构:
- 新的调度处理器可同时处理数千个线程;
- 增加指令缓存和常量缓存
- 320 个离散的独立流处理单元(stream processing unit);
- 标量 ALU实现了专用分支执行单元
- 3个专用取指单元,纹理缓存,顶点缓存,加载/存储缓存;
- 完全支持 DirectX 10.0、Shader Model 4.0
下图展示了统一着色器的架构:

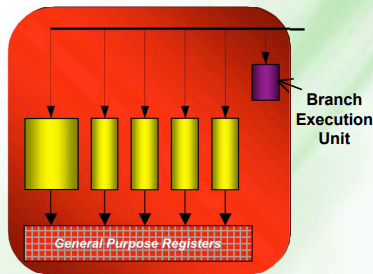
- 着色器指令是可变长度的VLIW(超长指令字),包括分支、循环、堆栈操作,屏障等控制流程指令;算术指令有1到7个64位操作数,其中5个标量操作数,2个常量操作数。
- 着色器处理单元(Shader Processing Unit)由 5 路标量流处理器(stream processor)组成,最多可同时发射 5 个标量 FP32 MAD(乘加),最多支持 5 个整数运算(cmp、逻辑、加法);其中一个流处理单元可以处理超越指令(SIN、COS、LOG、EXP、RCP、RSQ),整数乘法和移位运算。
- 分支执行单元处理流程控制和条件操作,包括全分支的条件代码生成以及ALU 中直接支持预测。1 MB 的 GPR 空间,用于快速寄存器访问。

3.3 TeraScale 2
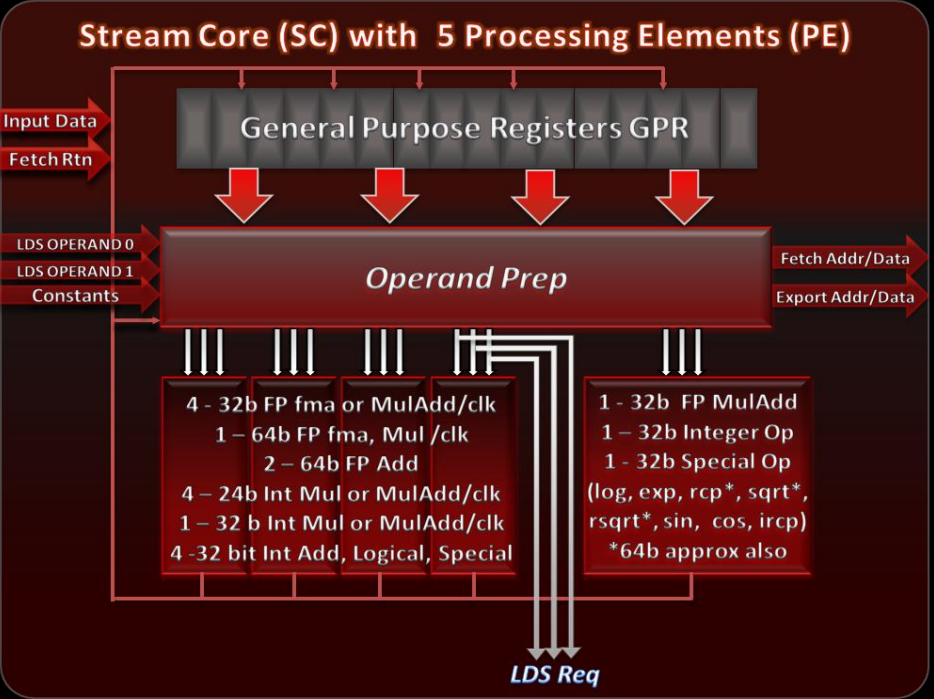
2009年,AMD推出TeraScale 2架构,应用在Radeon HD 5870,处理能力是上一代的两倍 – 2.72 Teraflops 和 27.2 Giga Pixels/s。整体上有两个统一着色器引擎SE(Shader Engine) ,每个着色器引擎有一个光栅器(Rasterizer),16 个像素 ROP 单元,10个SIMD Engine,支持248 个并发wavefront,如下图所示:

每个SIMD Engine有16个Stream Core,如下图所示:

- SIMD 引擎可以同时处理来自多个kernel的 Wavefronts,通过通道掩蔽和分支支持Wavefront内的线程发散,使Wavefront中的每个线程具有独立的程序执行路径;
- Wavefront长度为 64 个线程,其中每个线程可以执行 5 路 VLIW 指令 – 每个时钟执行1/4 Wavefront(16 个线程)分成T0-15、T16-31、T32-47、T48-T63。
- 每个 SIMD 引擎最多支持 8 个work group(用于线程数据共享);
- LDS (Local Data Share)和全局内存访问支持byte、ubyte、short、ushort 访问。私有加载和只读纹理读取通过读取缓存(Read Cache )进行,通过 R/W 缓存实现无序共享一致的加载/存储/原子访问;
每个Stream Core最多接收一个 VLIW 指令,支持 5 个ALU 操作或4 个带有 LDS 操作的ALU 操作(每个线程最多 3 个操作数);每个Stream Core单元有5个PE,如下图所示,其中:
- 4 个 PE(Processing Element),可以支持4 个独立 SP 或整数运算,2 个 DP 加法,1 个 DP fma 或 mult ;
- 1 个特殊功能 PE,支持1 个 SP 或整数运算,SP 或 DP 超越运算;以及操作数准备逻辑,通用寄存器和数据转发和预测逻辑
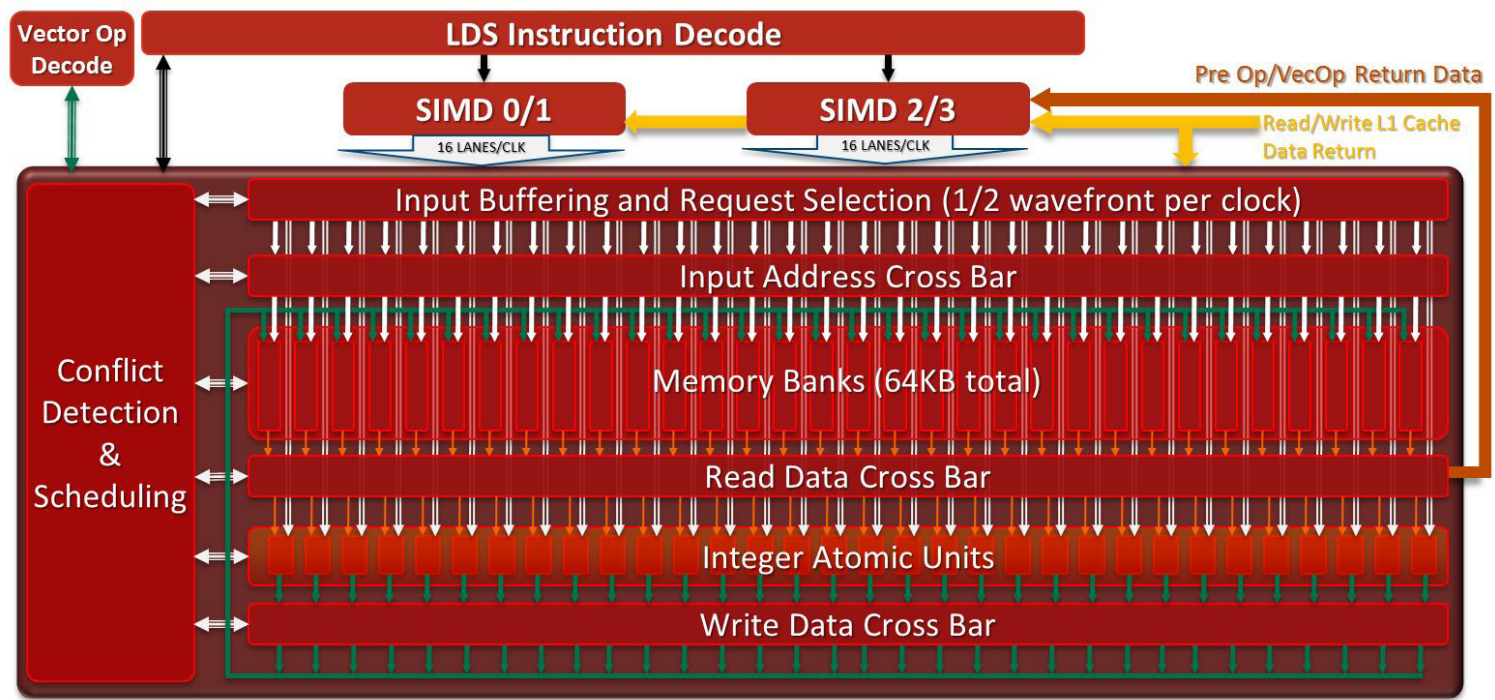
LDS(Local Data Share)用于一个Work Group里的Work Item之间共享数据来提高性能:
• 每个 SIMD 引擎的高带宽访问 (1024b/clk),外部 R/W 带宽的两倍 (512b/clk)
• 每个 SIMD 引擎的低延迟访问,直接读取(无冲突或广播)0 延迟,LDS 间接操作 1 个 VLIW 指令延迟
• 所有bank冲突都经过硬件检测,并在必要时进行序列化,并支持快速广播读取
• 每个线程组调度的 LDS 空间由硬件分配 ,基址和大小存储在wavefront里以便私人访问
 GDS(Global Data Share)与 LDS 类似,不同之处在于它是整个调度网格的共享内存,而不是Work Group, 访问kernel中所有线程之间的全局数据共享内存有25个时钟周期的延迟。GDS与使用常规全局内存优势在于大量线程以少量内存运行(例如追加计数器、缩减)可能会产生阻塞点,并且硬件利用率不足;单独的共享内存 (GDS) 可以释放全局内存,供着色器用于其他wavefront。
GDS(Global Data Share)与 LDS 类似,不同之处在于它是整个调度网格的共享内存,而不是Work Group, 访问kernel中所有线程之间的全局数据共享内存有25个时钟周期的延迟。GDS与使用常规全局内存优势在于大量线程以少量内存运行(例如追加计数器、缩减)可能会产生阻塞点,并且硬件利用率不足;单独的共享内存 (GDS) 可以释放全局内存,供着色器用于其他wavefront。
3.4 TeraScale 3
2010年,Radeon HD 6900中引入TeraScale 3 (VLIW4), 用 4 路 VLIW 设计取代了之前的 5 路 VLIW 设计。
3.5 GCN
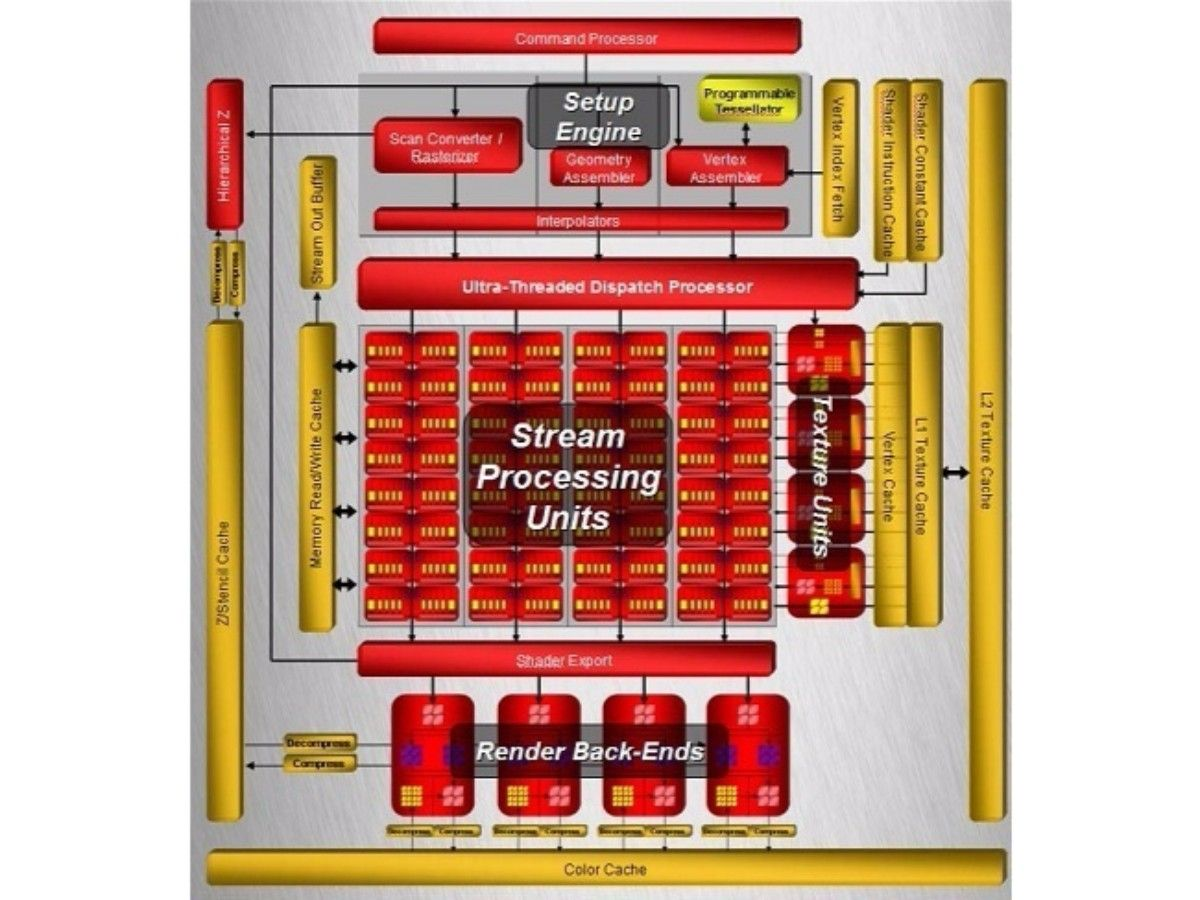
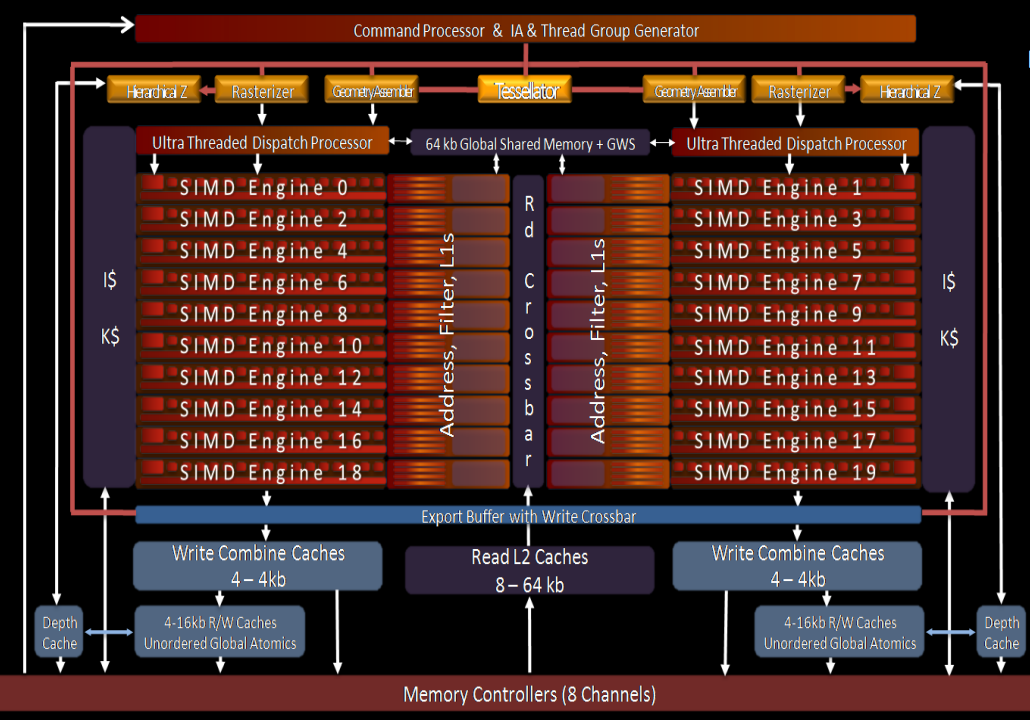
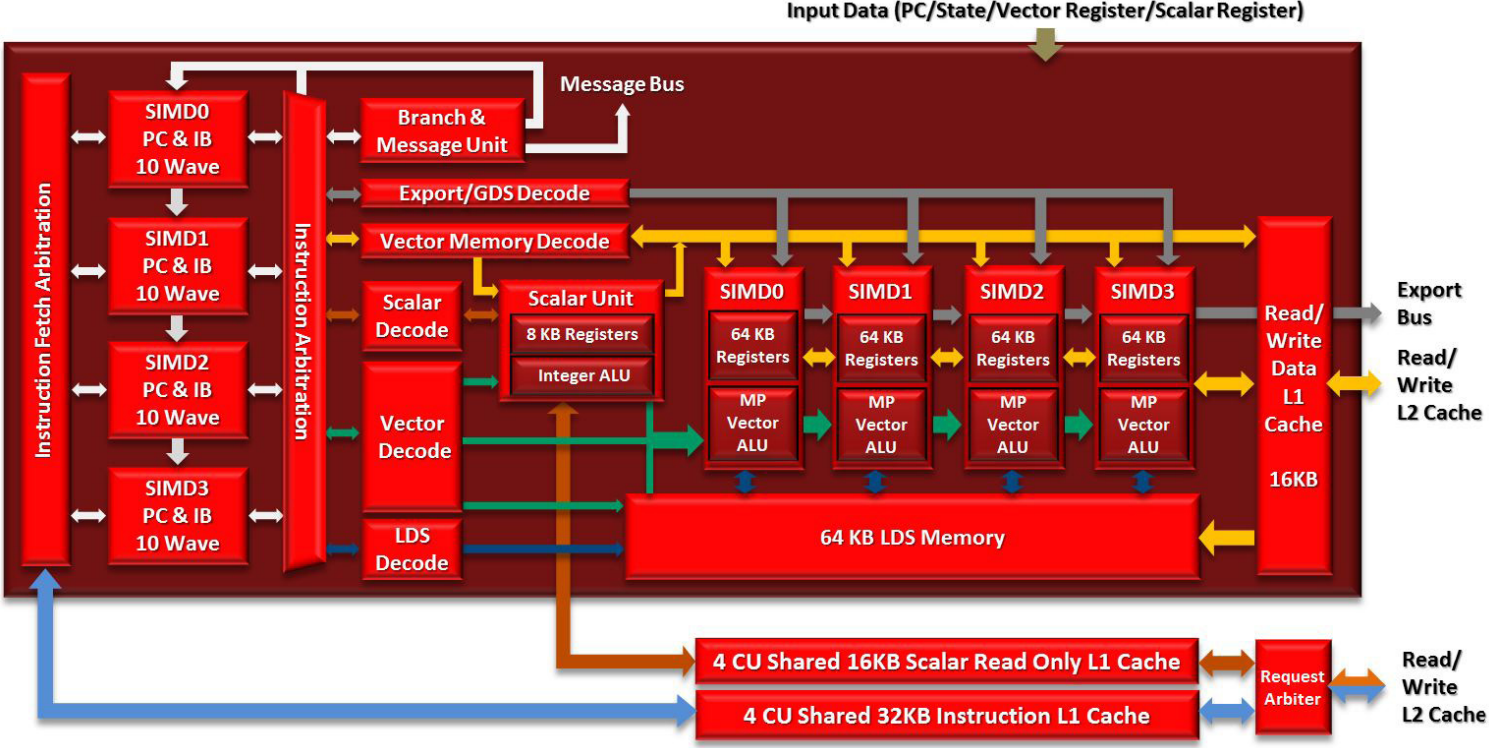
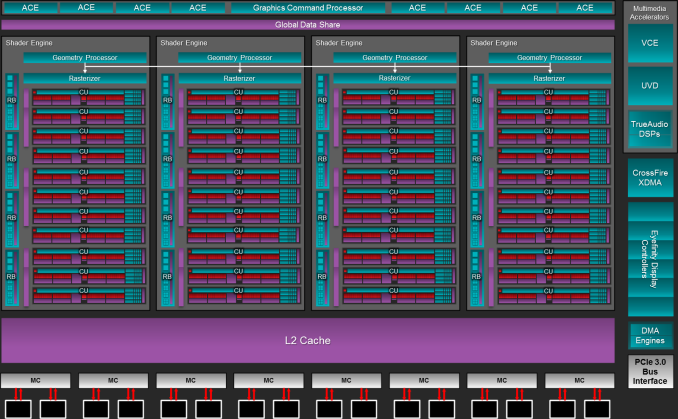
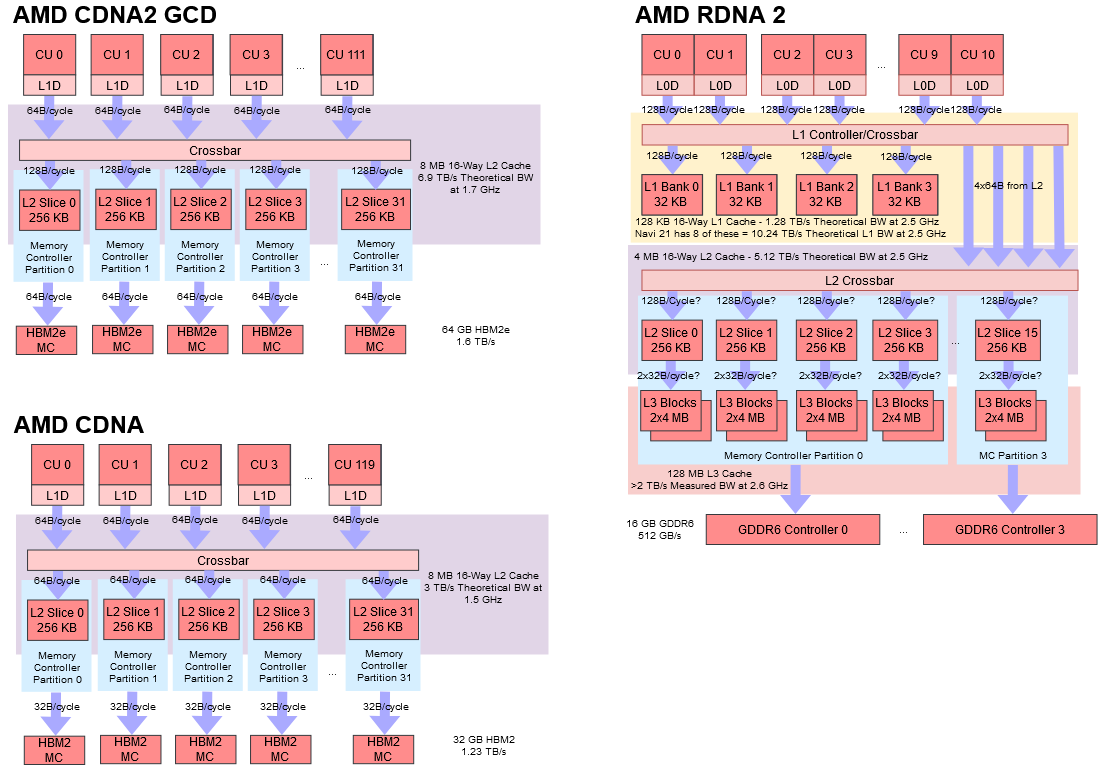
2011 年,AMD 放弃了 TeraScale 架构,转而采用完全重新设计并基于 RISC 微架构的 Graphics Core Next(GCN),目标之一是开发一款适合游戏和 GPGPU 工作的处理器。CU(Compute Unit)计算单元是 GCN 架构的基本计算单元。AMD Radeo HD 7970 分为 2 个原始(primitive)流水线和 4 个像素(pixel)流水线,有 32 个用于着色的计算单元(CU)和 384 位内存接口。GCN 的像素流水线分为 2 个 RBE 和 3 个内存控制器,内存带宽提高了 50%。整体架构如下所示:
 AMD Radeo HD 7970物理布局版图如下所示:
AMD Radeo HD 7970物理布局版图如下所示:
- GCN 集成了一个 I/O 内存管理单元 (IOMMU),可以为GPU 透明的映射x86 地址。因此, GCN 中的 DMA 可以访问可分页的 CPU 内存来移动数据,而无需地址转换的开销;同时,虚拟内存是多任务处理的先决条件,因此对内存有竞争需求的应用程序可以安全地共存。在缓存一致性的同时,GCN 通过硬件和驱动程序支持的组合引入了虚拟内存,消除了内存管理中最具挑战性的方面。
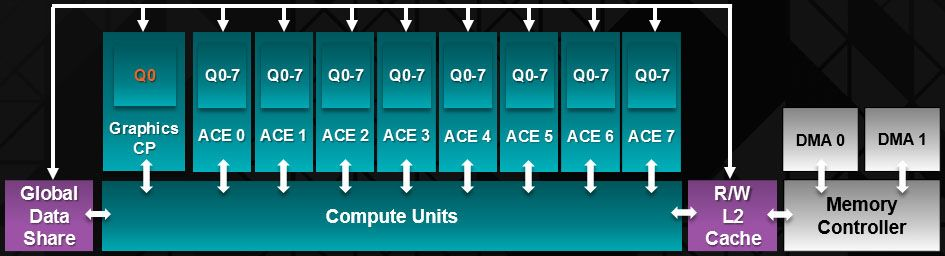
- GCN 命令处理器(Command Processor)负责从驱动程序接收高级 API 命令,并将它们映射到不同的流水线,GCN 中有两个主要流水线。
- 异步计算引擎 (ACE) 负责管理计算着色器,每个 ACE 都可以处理并行的命令流
- 图形命令处理器处理图形着色器和固定函数,图形命令处理器可以为每种着色器类型提供单独的命令流,利用 GCN 的多任务处理创建大量任务
GCN中ACE(Asynchronous Compute Engines) 负责所有计算着色器调度和资源分配,可能有多个独立运行的 ACE。
- 每个 ACE 从缓存或内存中获取命令,并形成任务队列,这是调度的起点。
- 每个任务都有一个调度的优先级,优先级范围从后台到实时。
- ACE 将检查最高优先级任务的硬件要求,并在有足够的资源可用时将该任务启动到 GCN 着色器中。
- 许多任务可以同时执行,由硬件资源限制决定。任务乱序完成,并提前释放资源,因此ACE 必须记录任务以确保正确性。
- 当任务被分发(Dsipatch)到 GCN 着色器时,任务被分解为多个工作组(wrokgroup),这些工作组被分发到各个计算单元进行执行。
- 每个周期,ACE 都可以创建一个工作组,并将一个wavefront从工作组调度到计算单元。
- ACE 通常以独立方式运行,需要使用缓存、内存或 64KB 全局数据共享(Global Data Share)进行同步和通信。
- 因此,ACE可以形成一个任务图,其中各个任务相互依赖。一个 ACE 中的任务可能依赖于另一个 ACE 或部分图形流水线上的任务。
- ACE 可以在任务队列之间切换,方法是停止任务并从其他队列中选择下一个任务。例如,如果当前正在运行的任务图由于依赖关系而正在等待来自图形流水线的输入,则 ACE 可以切换到准备好调度的其他任务队列。ACE 将刷新与旧任务关联的任何工作组(Workgroup),然后将新任务的工作组分发到着色器。
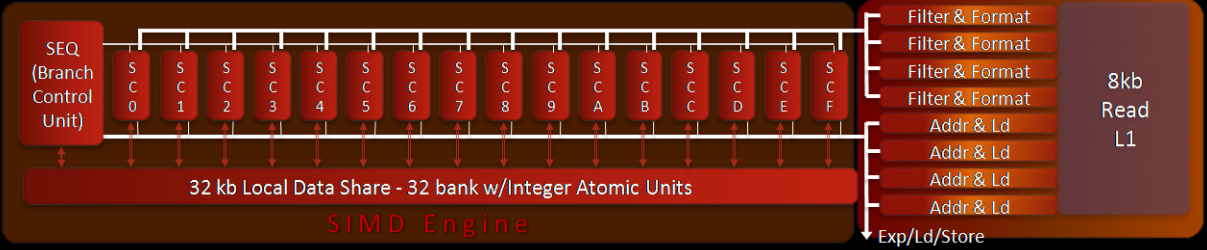
Compute Unit
在 GCN 中,每个 CU 包括 4 个独立的用于向量处理的 SIMD 单元。每个 SIMD 单元同时在 16 个工作项上执行单个操作,但每个单元都可以单独的wavefront上工作。这需要找到要并行处理的多个wavefrnts,而不是依靠编译器在单个wavefront内找到独立的操作。
在GCN中,每个SIMD单元有独立的40比特的程序计数器(Program Counter)和指令缓冲(instruction buffer),支持10个wavefronts;因此,一个CU可以同时支持40个wavefront,可以来自不同的workgroup或者kernel。AMD Radeon HD 7970有32个CU,最多同时支持81,920个wabefront.
- 4个CU组成一个cluster,共享4路组相联32KB L1指令缓存,缓存行64B,一般有8个指令;采用LRU(Least Recently Used )替换算法。L1指令缓存由4个bank组成,每周期可以为4个CU提供32B取指能力;一个CU内的SIMD之间的取指基于Age,调度优先级,指令缓冲利用率来仲裁。
- 指令进入Wavefront指令缓冲之后,CU每周期采用循环仲裁选择一条SIMD指令进行译码和发射;译码之后最多5条指令发射到执行单元,两个标量执行单元和4个向量执行单元。另外,特殊指令 (NOPs, barriers, halts, 跳过预测向量指令)直接在指令缓冲执行。每个CU有16个缓冲来记录屏障(barrier)指令。
- CU支持译码和发射7种类型的指令:
- 分支
- 标量ALU或标量访存
- 向量ALU
- 向量访存
- LDS(Local Data Share)
- GDS(Global Data Share)
- 特殊指令
- 同时只能发射一条一种类型的指令到SIMD,以避免超额订阅执行流水线;同时为了保证顺序执行,每个指令必须来自不同的wavefront。
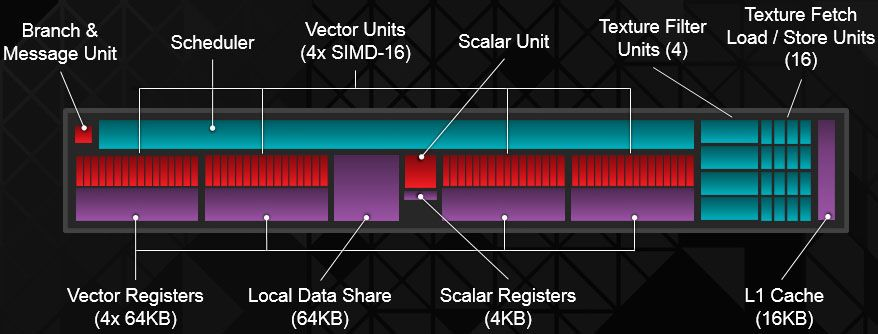 GCN CU里的标量流水线对于性能和功耗至关重要,控制流的处理分布在着色器,可以减少延迟并且减少了和中央调度逻辑通信的功耗。
每个CU有8KB的标量寄存器文件,每个SIMD有512个条目,由10个wavefront共享;一个wavefront可以分配112个用户寄存器和几个用于保留架构状态的寄存器。每个寄存器32比特且相连的寄存器可以组成64比特。
GCN CU里的标量流水线对于性能和功耗至关重要,控制流的处理分布在着色器,可以减少延迟并且减少了和中央调度逻辑通信的功耗。
每个CU有8KB的标量寄存器文件,每个SIMD有512个条目,由10个wavefront共享;一个wavefront可以分配112个用户寄存器和几个用于保留架构状态的寄存器。每个寄存器32比特且相连的寄存器可以组成64比特。 - 第一个标量流水线使用指令编码里的16比特偏移处理条件分支,同时还要负责处理中断和同步。
- 第二个标量流水线作为AGU(Address Generation Unit),用来从标量数据缓存读取数据;ALU是64比特,并支持包括跳转,调用,返回等控制指令,以及预测。
标量L1数据缓存是只读结构,由于标量流水线主要用于控制流指令,所以没有必要将结果写回到存储空间。标量L1的结构和L1指令缓存类似,16KB,4路组相联,64B缓存行,采用LRU替换算法;4个CU组成的cluster共享L1数据缓存,有4个bank,可以提供16B/cycle性能。
GCN里的SIMD不同于之前的VLIW,在VLIW里需要执行一个wavefront里的操作,会导致两个结果:
- 编译器决定了性能,如果wavefront里的并行度不够,硬件利用率会比较低
- 编译器需要小心调度寄存器文件的读写以避免端口冲突;为了避免端口冲突,wavefront不能背靠背的发射ALU操作,因此需要交织wavefront来掩盖延迟。
VLIW非常适用图形应用,但是对于复杂的计算任务需要大量的软件调优并且性能难以预测。GCN架构最大的改变是避免了wavefront内部的指令并行的需求。
由于每个SIMD执行单独的wavefront,向量寄存器文件可以分成独立的4个部分。向量通用寄存器vGPRs(General Purpose Registers)包含64条lane,每条32比特;相连的可以结合成64或128比特。每个SIMD有64KB vGPRs。
每个SIMD包含一个16 lane的向量流水线,兼容IEEE-75单精度和双精度;每条lane可以执行一条单精度融合或非融合的乘加运算或者24比特的整型操作。整型乘加操作对于一个wrokgroup内的地址计算非常有用;一个wavefront在一个周期内发射到SIMD,但是需要4个周期执行完64个work item。 GCN针对多媒体和图形处理也在向量运算单元增加了新的指令;特别是一个4x1的绝对误差和SAD(sum of absolute difference)以及用于8比特颜色32比特像素的4次绝对误差和(Quad SAD)指令。利用这些新指令,一个CU每周期可以执行64个SAD,256个运算。这些指令对于动作识别或视频搜索非常关键。 双精度和32位整型指令在SIMD内降速运行,双精度性能只有单精度的1/2到1/16。更复杂的指令如64位超越函数和除指令由微码实现。
本地数据共享和原子(LOCAL DATA SHARE和ATOMICS)
通信和同步在高性能计算中非常重要,本地数据共享(LDS)是一个显式寻址的内存,充当第三个寄存器文件,专门用于工作组(worjgroup)内的同步或图形的插值。
- GCN 中的 LDS 容量翻了一番,达到 64KB,有 16 或 32 个 bank(取决于产品)。
- 每个 bank 包含 512 个 32 位宽的条目。Bank 可以通过多对多交叉开关和 swizzle 单元读写 32 位值。
- 通常,LDS 每个周期将合并来自两个不同 SIMD 的 16 个通道,因此每 4 个周期完成两个wavefront。自动检测wavefront到 32 个通道中的冲突,并在硬件中解决。访问同一 bank 中不同元素的指令需要额外的周期才能完成。
- 广播是透明的,可以使用 8、16 或 32 位数据作为操作数。
对于图形,LDS 用于对纹理数据执行全速率插值,并且保证不会因访问模式而发生冲突。对于通用计算核,SIMD 可以在 LDS 中加载或存储数据,以避免 scatter 和 gather 访问污染缓存层次结构,或使用DS来放大缓存带宽。此外,原子单元对于工作组内的高性能同步至关重要,并且可以执行浮点最大值、最小值以及比较和交换作。
LDS 指令需要一个地址、两个数据值和一个目的地:
- 地址来自 vGPR
- 目的地可以是vGPR 或直接从 LDS 读取的 SIMD
- 两个数据值可以来自 L1 数据缓存(用于存储到 LDS)或 vGPR(加载或存储)
- 与其他设计不同,专用流水线避免使用向量 ALU 指令进行数据移动,例如将 LDS 加载到寄存器

EXPORT
导出单元(EXPORT)是计算单元对固定功能图形硬件以及全局数据共享 (GDS) 的窗口。完成所有计算后,结果通常会发送到图形流水线中的其他单元。例如,像素被着色后,在最终输出到显示器之前,它们通常会被发送到渲染后端进行深度和模板测试,并进行混合。导出单元将图形流水线的可编程阶段的结果写入固定功能阶段,例如曲面细分、光栅化和渲染后端。
GDS 与本地数据共享相同,不同之处在于它由所有计算单元共享,因此它充当所有wavefront之间的显式全局同步点。GDS 中的原子单元稍微复杂一些,可以处理有序的计数操作。
VECTOR MEMORY
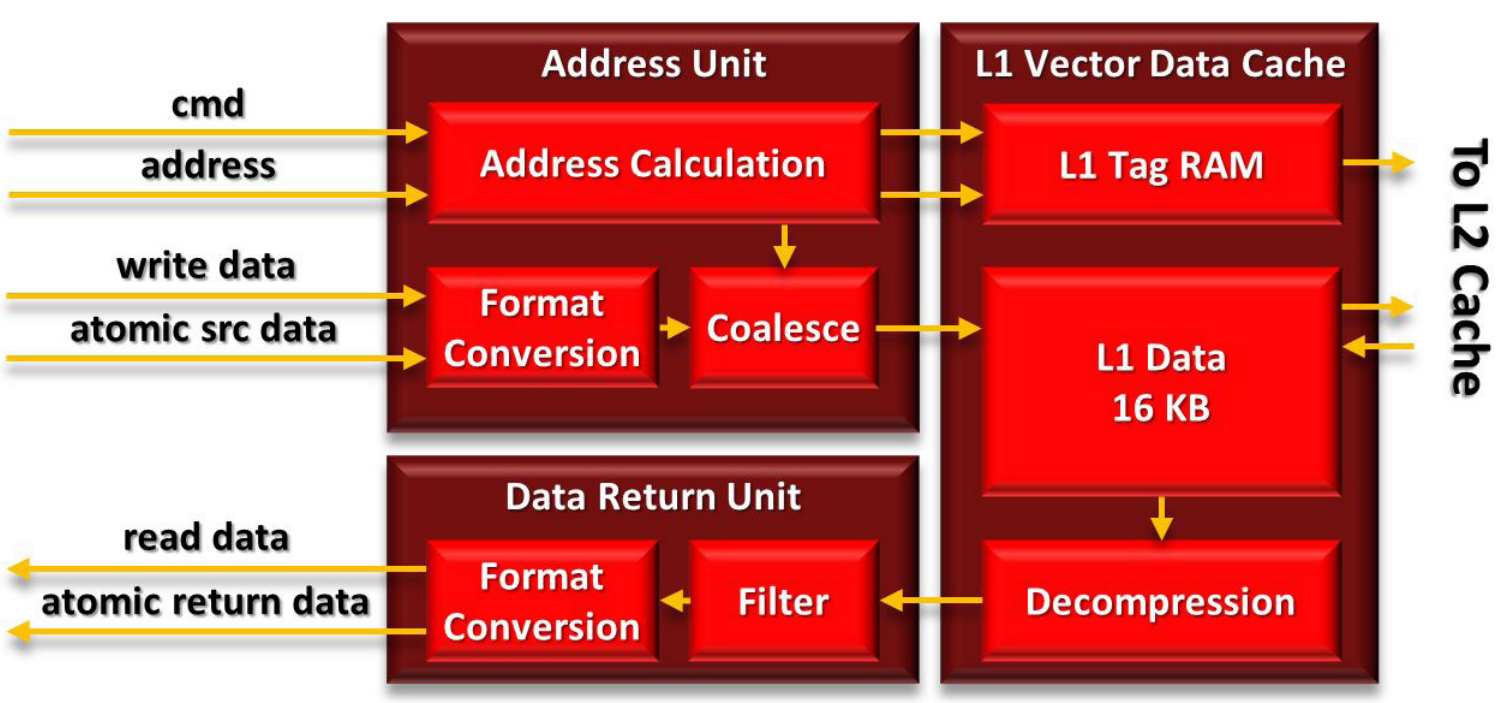
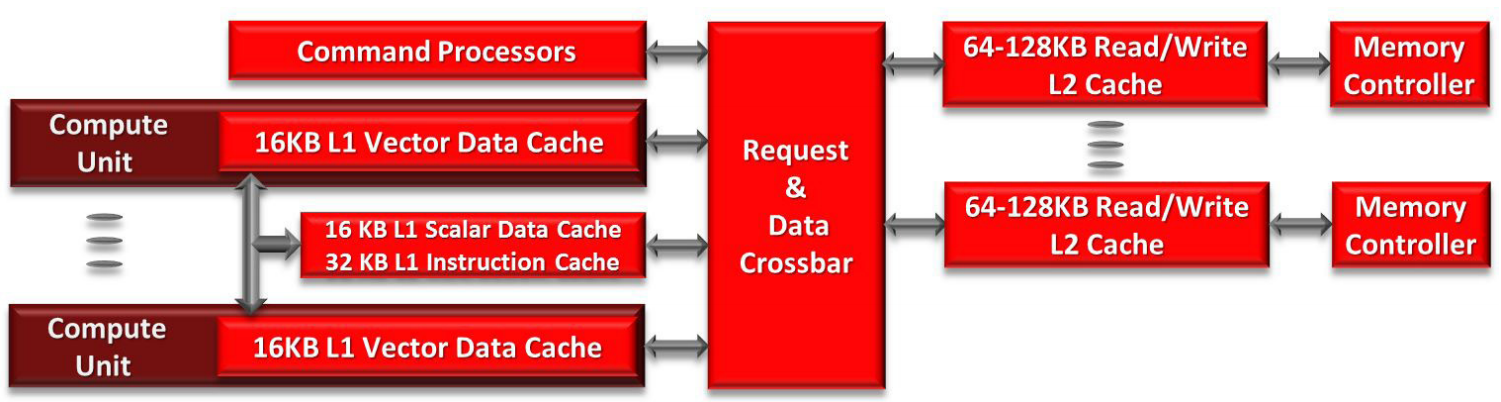
计算单元中的 SIMD 每个时钟周期可以执行 128 次浮点运算,因此需要提供足够的带宽来匹配计算资源。GCN 中最重要的变化无疑是缓存层次结构,从紧密关注的图形设计演变为高性能和可编程的层次结构,既适合通用应用,又可以与 x86 处理器集成用于图形。这些变化从计算单元开始,延伸到整个系统。
GCN 内存层次结构是一个统一的读/写缓存系统,支持虚拟内存和出色的原子作性能,不同于前几代使用的单独读缓存和写缓冲。向量内存指令支持可变粒度的地址和数据,范围从 32 位数据到 128 位像素。
- L1 数据缓存(L1D)为16KB,缓存行64B ,采用LRU 替换,4路组相联结构。
- 与 L2 和其他缓存采用极其宽松的一致性模型保持一致性。从概念上讲,L1D 缓存是工作组内缓存一致的,并通过 L2 缓存实现最终的全局一致性。
- L1D 采用带有脏字节掩码的直写、写分配设计。当wavefront指令中的所有 64 个存储都完成后,缓存行将写回 L2。所有数据都是脏数据的行会保留在 L1D 中,而任何部分干净的行都会从 L1D 中驱逐。
- 还有一些特殊的一致性加载指令可以从 L2 缓存中加载,以确保使用最新的值。一旦 AGU 计算出合并的地址,请求就会探测 L1D 缓存标签。在命中时,缓存会读出完整的 64B 行。对于完全合并的请求,这相当于 16 个数据值或 1/4 的wavefront,尽管较差的局部性可能需要额外的周期。对于计算工作负载,缓存行被写入 vGPR 或 LDS。
- 存储到 L1D 缓存稍微复杂一些。写入数据必须转换为适当的存储格式,然后将写入地址合并为尽可能少的单独事务,然后再命中缓存并最终写入 L2 缓存。
- 如果内存请求在 L1D 缓存中缺失,则将其发送到统一且一致的 L2 缓存,该缓存位于着色器核心之外并与内存控制器连。
- 为了提高效率并减少开销,灵活的内存层次结构也被用于图形,并带有一些专用硬件。地址生成单元每个周期接收 4 个纹理地址,然后计算最近的 16 个采样地址。样本从 L1 数据缓存中读取,并在纹理映射单元或TMU(Texture Mapping Unit)中解压缩。然后,TMU 过滤相邻样本,每个时钟生成多达 4 个最终插值纹理。
- TMU 输出被转换为所需的格式,并最终写入向量寄存器文件以供进一步使用。格式转换硬件还用于将一些图形内核里的值写到内存。
L2 CACHE
GCN 中的分布式 L2 缓存是 GPU 中一致性的中心点。它充当 CU 集群共享的只读 L1 指令和标量缓存以及每个 CU 中的 L1 数据缓存的后盾。L2 缓存在物理上被分区为耦合到每个内存通道的切片中,访问流通过交叉开关结构从计算单元流向缓存和内存分区。
- TMU 输出被转换为所需的格式,并最终写入向量寄存器文件以供进一步使用。格式转换硬件还用于将一些图形内核里的值写到内存。
- 与 L1 数据缓存一样,L2 是虚拟寻址的,因此不需要 TLB。L2 缓存是 16 路组相联,64B 缓存行,采用 LRU 替换算法;采用写回和写分配设计,因此可以吸收所有 L1 数据缓存的写缺失。每个 L2 切片为 64-128KB,可以将 64B 缓存行发送到 L1 缓存。 L2 缓存一致性的一大优势是,很适合执行全局原子操作和在不同wavefront之间同步。虽然 LDS 可用于wabefront内的原子操作,但在某些时候,不同wavefront的结果需要组合。这正是 L2 发挥作用的地方。一个 L2 切片每个周期可以对缓存行执行多达 16 个原子操作。
- GCN 中的整体一致性协议是一种混合模型,将 GPU 的性能和带宽与传统 CPU 的可编程性相结合。从概念上讲,L1 数据缓存对工作组内的本地访问保持严格的一致性。在wavefront结束时或调用屏障时,数据被写入 L2 并在 GPU 上变得全局一致。此模型通常被描述为relaxed consistency,相比严格一致性有巨大的优势,低开销提供的数十个高性能本地访问,同时 L2 为程序员提供了友好的一致性
- 同时,缓存层次结构旨在与 x86 微处理器集成。GCN 虚拟内存系统可以支持 4KB 页,这是 x86 地址空间的自然映射粒度,为将来的共享地址空间铺平了道路。事实上,用于 DMA 传输的 IOMMU 已经可以将请求转换为 x86 地址空间,以帮助将数据移动到 GPU。此外,GCN 中的缓存使用 64B 缓存行,与 x86 处理器大小相同。这为异构系统通过传统缓存在 GPU 和 CPU 之间透明地共享数据奠定了基础,而无需程序员明确的控制。
内存控制器将 GPU 连接在一起,并为系统的每个功能单元提供数据。命令处理器(CP)、ACE、L2 缓存、RBE、DMA 引擎、PCI Express、视频加速器、Crossfire 互连和显示控制器都可以访问本地图形内存。每个内存控制器的宽度为 64 位,由两个独立的 32 位 GDDR5 内存通道组成。对于低成本产品,GDDR5 也可以用 DDR3 内存代替。对于需要较大的内存空间,GDDR5 控制器可以在clasmshell模式下运行,每个通道使用两个 DRAM,从而使容量翻倍。
 现代芯片最大的可靠性问题是片上内存中的软错误soft error(或位翻转)。像 AMD Radeon HD 7970 这样的高端 GPU 拥有超过 12MB 的 SRAM 和寄存器文件,分布在整个 CU 和缓存中。GCN 的片上内存支持 SECDED。第二个可靠性挑战是外部存储器。标准 GDDR5 内存接口使用 CRC 检查传输的数据,并可以重新发送任何损坏的数据。但是,没有 ECC,因此无法知道 DRAM 中保存的数据是否被软错误损坏。GCN 内存控制器具有将 SECDED 应用于 DRAM 的可选模式。受 ECC 保护的数据大约大了 6%,这略微降低了整体内存容量和带宽。
现代芯片最大的可靠性问题是片上内存中的软错误soft error(或位翻转)。像 AMD Radeon HD 7970 这样的高端 GPU 拥有超过 12MB 的 SRAM 和寄存器文件,分布在整个 CU 和缓存中。GCN 的片上内存支持 SECDED。第二个可靠性挑战是外部存储器。标准 GDDR5 内存接口使用 CRC 检查传输的数据,并可以重新发送任何损坏的数据。但是,没有 ECC,因此无法知道 DRAM 中保存的数据是否被软错误损坏。GCN 内存控制器具有将 SECDED 应用于 DRAM 的可选模式。受 ECC 保护的数据大约大了 6%,这略微降低了整体内存容量和带宽。
3.6 GCN2
Hawaii是 GCN 1.1, 即GCN2。AMD 显著增强了 GPU 的前端和后端,将它们各自增加了一倍。
- 前端包含 4 个几何处理器和光栅器对,而在Tahiti上,2 个几何处理器与 4 个光栅器相关联
- 后端包含 64 个 ROP,而Tahiti为 32 个 ROP
- 在计算核心方面,从 32 个 CU 增加到 44 个 CU
- 1MB的L2缓存
 Hawaii 里的 GCN 架构与之前相似。计算单元基本完全相同,有 64 个符合 IEEE 754-2008 标准的着色器,分为 4 个向量单元和 16 个纹理获取加载/存储单元。一些修改包括支持标准调用约定的全局平坦地址、对原生 LOG 和 EXP 运算的精度改进,以及对绝对差分的掩码四和Masked Quad Sum of Absolute Difference(MQSAD) 函数的优化,该函数可加快运动估计算法。
Hawaii 里的 GCN 架构与之前相似。计算单元基本完全相同,有 64 个符合 IEEE 754-2008 标准的着色器,分为 4 个向量单元和 16 个纹理获取加载/存储单元。一些修改包括支持标准调用约定的全局平坦地址、对原生 LOG 和 EXP 运算的精度改进,以及对绝对差分的掩码四和Masked Quad Sum of Absolute Difference(MQSAD) 函数的优化,该函数可加快运动估计算法。
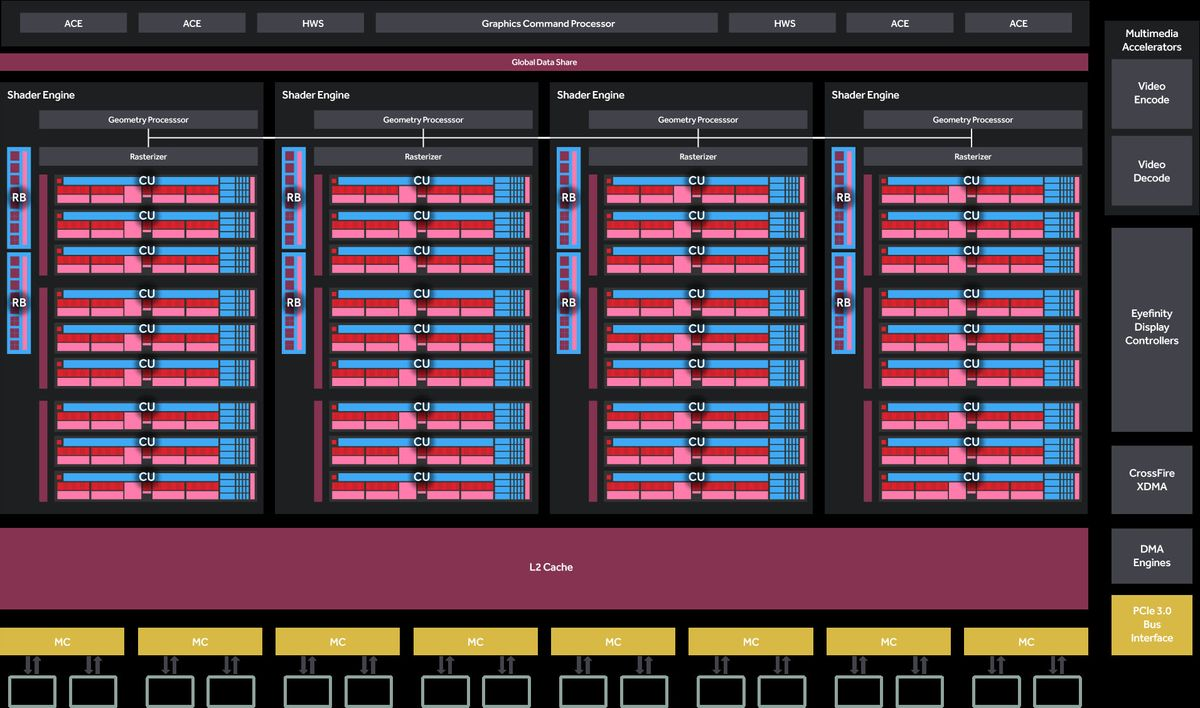 CU 的排列方式有所不同,Tahiti有 32 个计算单元,总共 2048 个着色器和 128 个纹理单元,而Hawaii有 44 个 CU,这些 CU 被组织成 AMD 所说的四个着色器引擎,加起来一共 2816 个聚合着色器和 176 个纹理单元。最大的变化是 AMD 将硬件组织为“着色器引擎”。从概念上类似于 NVIDIA 的 SMX,每个着色器引擎 (SE) 包括着色器/CU、几何处理器、光栅器和 L1 缓存。此外,ROP 也被纳入着色器引擎模型中,每个 SE 承担一小部分 ROP。SE 之外的是命令处理器和 ACE、L2 高速缓存和内存控制器,以及各种专用的非重复功能,如视频解码器、显示控制器、DMA 控制器和 PCIe 接口。
CU 的排列方式有所不同,Tahiti有 32 个计算单元,总共 2048 个着色器和 128 个纹理单元,而Hawaii有 44 个 CU,这些 CU 被组织成 AMD 所说的四个着色器引擎,加起来一共 2816 个聚合着色器和 176 个纹理单元。最大的变化是 AMD 将硬件组织为“着色器引擎”。从概念上类似于 NVIDIA 的 SMX,每个着色器引擎 (SE) 包括着色器/CU、几何处理器、光栅器和 L1 缓存。此外,ROP 也被纳入着色器引擎模型中,每个 SE 承担一小部分 ROP。SE 之外的是命令处理器和 ACE、L2 高速缓存和内存控制器,以及各种专用的非重复功能,如视频解码器、显示控制器、DMA 控制器和 PCIe 接口。
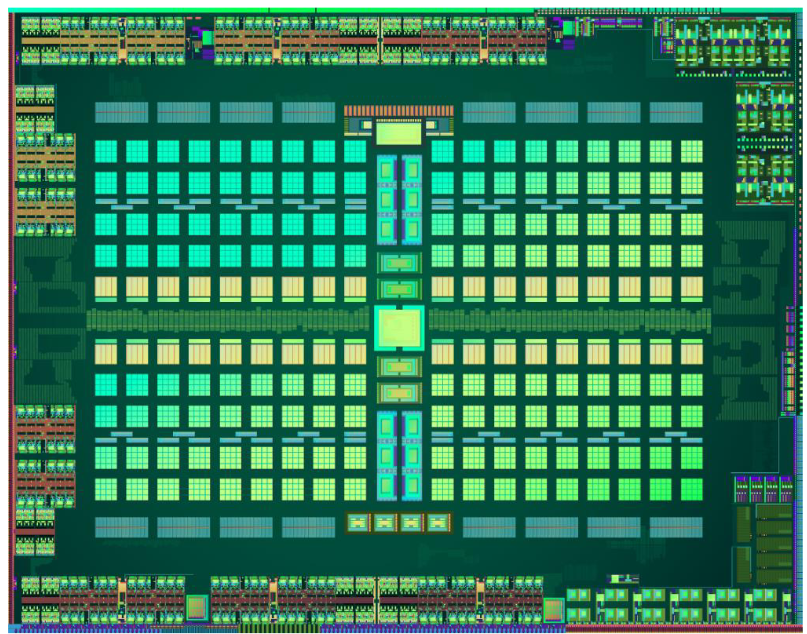 Hawaii 还使用了 8 个经过改进的异步计算引擎Asynchronous Compute Engine,负责将实时和后台任务调度到 CU。每个 ACE 最多管理 8 个队列,总共 64 个队列,并且可以访问 L2 缓存和共享内存。
Hawaii 还使用了 8 个经过改进的异步计算引擎Asynchronous Compute Engine,负责将实时和后台任务调度到 CU。每个 ACE 最多管理 8 个队列,总共 64 个队列,并且可以访问 L2 缓存和共享内存。
 Hawaii采用与 5GHz GDDR5 配对的 512 位内存总线,内存带宽总量达到 320GB/s
Hawaii采用与 5GHz GDDR5 配对的 512 位内存总线,内存带宽总量达到 320GB/s
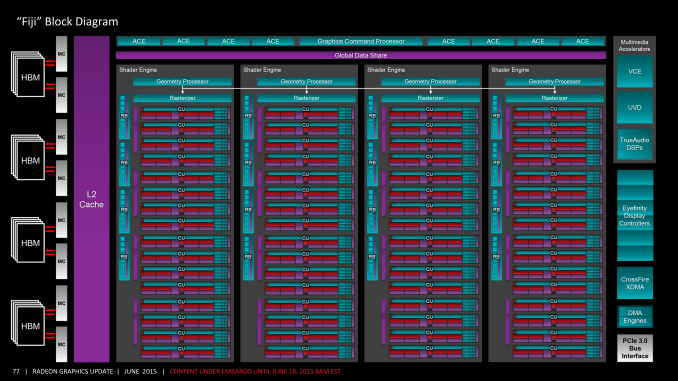
3.7 GCN 3 - Radeon R9 Fury X
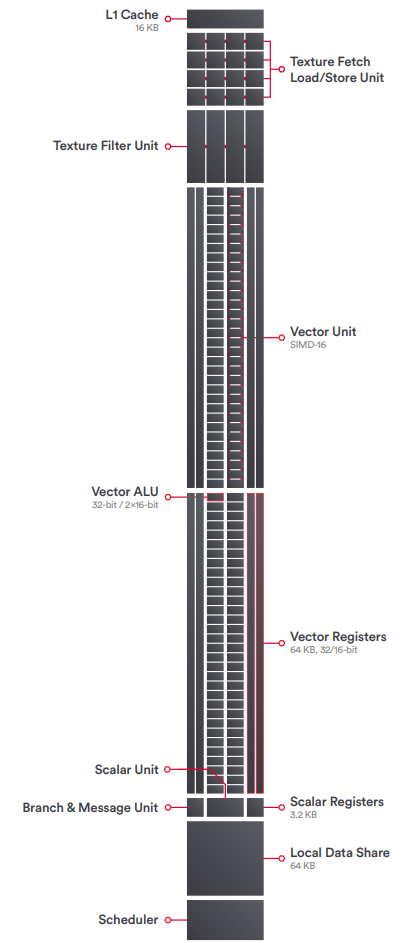
GCN 1.2 即GCN3最重要功能是 AMD 最新一代的 delta 颜色压缩技术。与Fiji的 ROP 相关联,delta颜色压缩增强了 AMD 现有的颜色压缩功能,增加了基于图块内像素模式和它们之间的差异(即增量)的压缩模式,从而提高了帧缓冲区(和 RT)的压缩频率和压缩量。GCN 3能够以有限的方式在 SIMD 通道之间共享数据,超越了现有的 swizzling 和其他数据组织方式。 中介层芯片超过了 65nm 工艺的标线限制,因此中介层经过精心构造,只有需要连接的区域才能接收金属层。在除去功能单元数量和内存变化的差异后,Fiji的整体逻辑布局接近Hawaii。64 个 CU 的布局方式与之前的 GCN 设计一致,着色器引擎整体组织方式也一样。整个GPU 分为四个部分,每个着色器引擎有 1 个几何单元(geometry unit)、1 个光栅器单元(rasterizer unit)、4 个渲染后端(总共 16 个 ROP),以及16个CU。
具体的,CU 还是以 4 个为一组,每组共享一个 16KB 的 L1 标量缓存和 32KB 的 L1 指令缓存。同时,由于Fiji的 CU 数量是 16 的倍数,这也消除了Hawaii在每个着色器引擎尾端的 3 个 CU 的古怪组。Fiji的 L2 缓存也进行了升级,达到 2MB。
3.8 GCN 4 - Radeon RX 480
Polaris 图形架构负责处理图形和计算工作负载,并尽可能高效地执行它们。Polaris 基于 GCN ,
- 增加了每个区域的 CU 数量以提高原始计算吞吐量,但保留了相同的整体 CU 设计。
- 改进控制逻辑和固定功能图形硬件,以充分利用可用的计算单元。Polaris 增强了命令处理、几何引擎和内存子系统,以实现比单纯 GCN 更高的性能和更高的能效。
命令处理器从驱动程序接收高级 API 指令(例如 DirectX 或 OpenCL),并将其转换为计算着色器、图形着色器或 DMA 复制命令。
- 计算任务被映射到多个异步计算引擎 (ACE) 上。每个 ACE 从主机接收单独的命令流,并有八个任务队列。ACE 可以从八个队列中的任何一个队列的头部进行调度。ACE 将异步计算着色器workgroup分发到着色器阵列中
- 图形流水线包含每种类型的着色器(例如,像素着色器、纹理着色器和同步计算着色器)的队列。图形命令处理器调度图形着色器,并协调固定功能硬件,例如光栅化器。
- 两个专用的 DMA 引擎处理与 GPU 内存之间的复制命令。
AMD 开创了一种称为异步计算的技术,该技术使 ACE、图形命令处理器和 DMA 引擎能够同时将任务分发到 GPU,而无需上下文切换。并行分发工作组workgroup可大大减少执行延迟并提高吞吐量,从而提高整体性能和响应能力。DirectX 12 和 Vulkan等库里新的低级 API 向开发人员提供了并行控制逻辑,充分利用了异步着色,实现了比早期 API 更高的性能。
Polaris 架构通过两种新的QoS技术增强了命令处理器,旨在提高系统响应能力和性能。
-
第一种称为快速响应队列Quick Response Queue,开发人员能够通过 API 将计算任务队列指定为高优先级。高优先级任务和常规优先级任务共存并共享 GPU 的执行资源,但 ACE 优先从高优先级任务中分派工作组workgroup。这种优先级方案可确保高优先级任务使用更多资源并优先完成,而无需命令处理器进行上下文切换来排除其他低优先级任务。
-
第二种QoS即计算单元预留,更加有效和通用。顾名思义,程序员可以使用 API 扩展对 Polaris GPU 的执行资源进行分区,用于计算任务。具体来说,着色器阵列中的计算单元 (CU) 可以为一个 ACE 中的队列保留,确保队列中的工作组有专用资源可用。这是开发人员避免多个任务之间竞争的强大工具。
在“Hawaii”和其他基于 Graphics Core Next ISA 的 GPU 中,硬件设计为支持固定数量的计算队列(每个 ACE 最多 8 个)。但是,从第 3 代和第 4 代 GCN 开始,硬件调度器Hardware Scheduler(HWS) 可以虚拟化这些计算队列。这意味着可以支持任意数量的队列,并且 HWS 会在槽可用时将这些队列分配给可用的 ACE。Polaris 和 GCN 架构图中的每个 ACE 代表一个wavefront/工作组调度器。因此,“Fiji” GPU 和基于 Polaris 架构的 GPU 可以随时从任何计算队列向着色器引擎分配多达四个wavefront/工作组。HWS 单元是双线程微处理器,能够处理两个调度线程,它们的行为可以通过 AMD 的微码更新进行调整。
9 个 CU 被组织成一个着色器引擎,Polaris 架构上最多支持 4 个 SE。每个着色器引擎都与一个几何引擎相关联。Polaris 也有2MB L2 缓存。
 Polaris采用 256 位内存总线,比Hawaii的 512 位窄得多。Radeon RX 480 的 4GB 版本包括 7 Gb/s GDDR5,实现 224 GB/s 的带宽; 8GB 型号使用 8 Gb/s 内存,将吞吐量提高到 256 GB/s。下图是基于 Polaris 架构的 Radeo RX 480 GPU 的芯片物理布局图:
Polaris采用 256 位内存总线,比Hawaii的 512 位窄得多。Radeon RX 480 的 4GB 版本包括 7 Gb/s GDDR5,实现 224 GB/s 的带宽; 8GB 型号使用 8 Gb/s 内存,将吞吐量提高到 256 GB/s。下图是基于 Polaris 架构的 Radeo RX 480 GPU 的芯片物理布局图:
3.9 GCN 5 - VEGA
“Vega” 10 芯片采用TSMC 14 纳米 LPP FinFET 工艺制造,125 亿个晶体管,面积 486 mm^2,最高达到1.67GHz 的Boost频率;一共 64 个下一代计算单元 (NCU),总共有 4,096 个流处理器。“Vega” 10 是第一款使用 Infinity Fabric 互连构建的 AMD 图形处理器,该互连也是“Zen”微处理器的基础。这种低延迟的互连在片上逻辑模块之间提供一致性的通信,并有QoS和安全功能。在“Vega” 10 中,Infinity Fabric 将图形核心和芯片上的其他主要逻辑模块连接起来,包括内存控制器、PCI Express 控制器、显示引擎和视频加速模块。整体架构框图如下所示:
 流处理器支持 16 位packed math,使峰值浮点和整数速率相对于 32 位运算翻了一番, 同时寄存器空间以及处理给定数量的运算所需的数据移动减少了一半。新指令集包括 16 位浮点和整数指令的丰富组合,包括 FMA、MUL、ADD、MIN/MAX/MED、移位、打包作等等。对于可以利用此功能的应用程序,Rapid Packed Math 可以显著提高计算吞吐量和能源效率。对于机器学习和训练、视频处理和计算机视觉等专业应用,16 位数据类型是自然而然的选择,但对于更传统的渲染作也有好处。例如,除了标准 FP32 之外,现代游戏还使用多种数据类型,Normal/direction向量、照明值、HDR 颜色值和混合因子也可以使用 16 位运算。
除了 Rapid Packed Math 之外,NCU 还引入了各种新的 32 位整数运算,可以提高特定场景的性能和效率。其中包括一组八条指令,用于加速内存地址生成和哈希函数(通常用于加密处理和加密货币挖掘),以及最大限度地减少寄存器使用的新 ADD/SUB 指令。NCU 还支持一组 8 位整数 SAD (Sum of Absolute Differences) 运算。这些指令对于各种视频和图像处理算法都非常重要,包括用于机器学习的图像分类、运动检测、手势识别、立体深度提取和计算机视觉。QSAD 指令可以在每个时钟周期内计算 16 个 4x4 像素图块,并将结果累积到 32 位或 16 位寄存器中。可屏蔽版本 (MQSAD) 可以通过忽略背景像素并将计算集中在图像中感兴趣的区域来提供进一步的优化。
流处理器支持 16 位packed math,使峰值浮点和整数速率相对于 32 位运算翻了一番, 同时寄存器空间以及处理给定数量的运算所需的数据移动减少了一半。新指令集包括 16 位浮点和整数指令的丰富组合,包括 FMA、MUL、ADD、MIN/MAX/MED、移位、打包作等等。对于可以利用此功能的应用程序,Rapid Packed Math 可以显著提高计算吞吐量和能源效率。对于机器学习和训练、视频处理和计算机视觉等专业应用,16 位数据类型是自然而然的选择,但对于更传统的渲染作也有好处。例如,除了标准 FP32 之外,现代游戏还使用多种数据类型,Normal/direction向量、照明值、HDR 颜色值和混合因子也可以使用 16 位运算。
除了 Rapid Packed Math 之外,NCU 还引入了各种新的 32 位整数运算,可以提高特定场景的性能和效率。其中包括一组八条指令,用于加速内存地址生成和哈希函数(通常用于加密处理和加密货币挖掘),以及最大限度地减少寄存器使用的新 ADD/SUB 指令。NCU 还支持一组 8 位整数 SAD (Sum of Absolute Differences) 运算。这些指令对于各种视频和图像处理算法都非常重要,包括用于机器学习的图像分类、运动检测、手势识别、立体深度提取和计算机视觉。QSAD 指令可以在每个时钟周期内计算 16 个 4x4 像素图块,并将结果累积到 32 位或 16 位寄存器中。可屏蔽版本 (MQSAD) 可以通过忽略背景像素并将计算集中在图像中感兴趣的区域来提供进一步的优化。
 GPU 是大规模并行处理器,需要大量数据移动才能实现峰值吞吐量。主要依靠高级存储设备和多级缓存系统的组合来满足:
GPU 是大规模并行处理器,需要大量数据移动才能实现峰值吞吐量。主要依靠高级存储设备和多级缓存系统的组合来满足:
- 各种PE的 registers 从一组 L1 cache中读取数据
- L1 cache又访问一个统一的片上 L2 cache
- L2 缓存提供对 GPU 专用内存的高带宽、低延迟访问
GPU 通常需要将其整个工作数据集和资源保存在本地内存中,因为替代方案(即通过 PCI Express 总线从主机系统内存中提取数据)无法提供稳定的高带宽或足够低的延迟来保持其以最高性能运行。
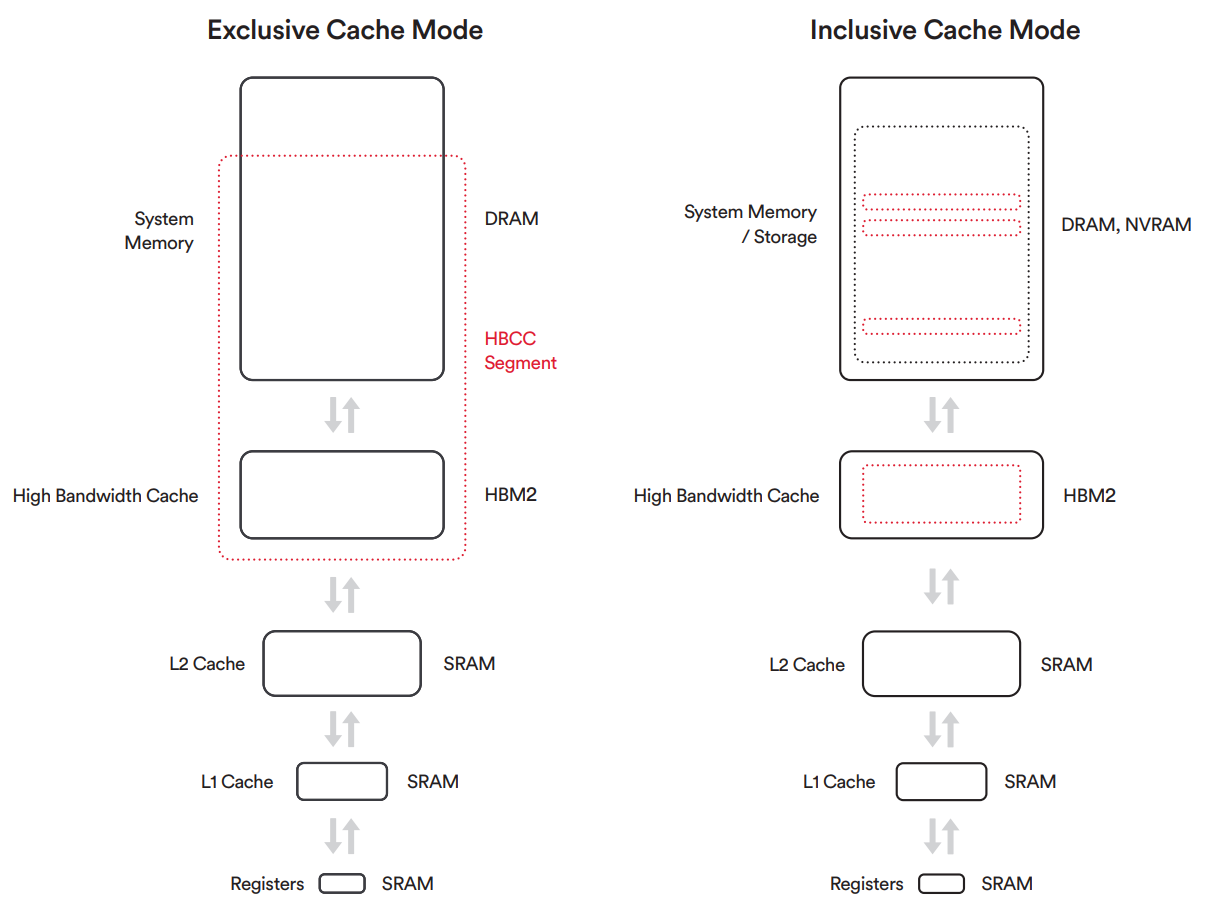
“Vega” 架构突破了这一限制,允许其本内存的行为类似于最后一级缓存。如果 GPU 尝试访问当前未存储在本地内存中的数据,它可以通过 PCIe 总线提取必要的内存页并将其存储在高带宽缓存中,而不是强制 GPU 在复制整个缺失资源时停止运行。由于页面通常比整个纹理或其他资源小得多,因此可以更快地复制它们。传输完成后,对这些内存页面的任何后续访问都将受益于更低的延迟,因为它们现在驻留在缓存中。此功能是通过添加称为高带宽缓存控制器 (HBCC) 的内存控制器逻辑来实现的,HBCC提供了一组功能,允许远程内存像本地内存一样工作,而本地内存的行为就像LLC(Last Level Cache)一样。HBCC 支持 49 位寻址,提供高达 512 TB 的虚拟地址空间,足以覆盖现代 CPU 可访问的 48 位地址空间,并且比当今 GPU 通常附带的几 GB 本地内存大几个数量级。HBCC 是适用于服务器和专业应用的革命性技术。对于处理的数据集大小接近系统内存容量的应用程序,基于“Vega”架构的 GPU 能为此类应用程序提供与本地内存相当的有效内存性能,而且未来甚至可以扩展到非易失性存储等大容量存储设备。应用程序可以将此存储容量视为一个统一的大内存空间。如果访问当前未存储在本地高带宽内存中的数据,HBCC 可以按需缓存页面,而最近未使用的页面将交换回系统内存。这个统一的内存池被称为 HBCC 内存段 (HMS,HBCC Memory Segment)。为了从“Vega”的新的缓存层次结构中获得最大收益,所有图形模块都通过L2 缓存进行访问。与以前基于 GCN 的架构不同,在之前架构中,像素引擎拥有自己的独立缓存,并支持更大的数据重用。由于 GPU 的 L2 缓存在新的内存层次结构中起着核心作用,因此基于“Vega”架构的 GPU 设计了大量 L2 缓存。“Vega” 10 GPU 具有 4 MB 的 L2 缓存,是以前高端 AMD GPU 中 L2 缓存大小的两倍。
4.0 CDNA 1 - MI100
AMD Instinct MI100 GPU 分为几个主要功能模块,这些模块都通过片上互联连接在一起:
- PCI-Express 4.0 接口,使用 16GT/s 链路将 GPU 连接到主机处理器,例如第 2 代 AMD EPYC CPU,该链路在每个方向上提供高达 32GB/s。
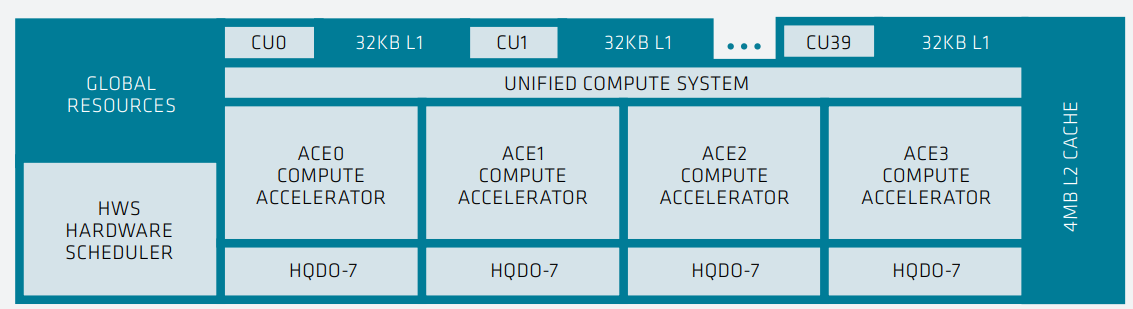
- 命令处理器接收 API 级命令并为 GPU 的各个组件分配工作。概括地说,任何计算处理器(无论是 CPU 还是 GPU)的三个主要功能是计算、内存和通信,每个功能由不同的模块实现。命令处理器和调度逻辑将更高级别的 API 命令转换为计算任务。这些计算任务反过来又作为计算阵列实现并由异步计算引擎 (ACE) 管理。四个 ACE 中的每一个都维护着独立的命令流,并且可以将wavefront分发到计算单元。
AMD CDNA 架构中 120 个 CU 被组织成四个 CU 阵列。CU 源自之前的 GCN 架构,并执行包含 64 个工作项的wavefront。但是,CU 通过新的矩阵核心引擎(Matrix Core Engine)得到增强,这些引擎针对矩阵数据类型进行了优化,从而提高了计算吞吐量和能效。AMD Instinct MI100 加速器的框图如下,这是第一款由 AMD CDNA 架构提供支持的 GPU:
 CU 通过新的矩阵引擎进行增强,以处理 MFMA 指令并提高吞吐量和能源效率。与 GCN 中的传统向量流水线相比,矩阵执行单元具有多项优势:
CU 通过新的矩阵引擎进行增强,以处理 MFMA 指令并提高吞吐量和能源效率。与 GCN 中的传统向量流水线相比,矩阵执行单元具有多项优势:
- 首先,执行单元减少了寄存器文件读取的次数,因为在矩阵乘法中,许多输入值被重复使用。
- 其次,较窄的数据类型为不需要完全 FP32 精度的工作负载(例如机器学习)提供优化空间。一般来说,乘累加指令功耗是输入数据类型的平方,因此从 FP32 转移到 FP16 或 bf16 可以节省大量功耗。
经典的 GCN 计算核心包含各种针对标量和向量指令优化的流水线:
- 每个 CU 包含一个标量寄存器文件、一个标量执行单元和一个标量数据缓存,以处理在wavefront间共享的指令,如公共控制逻辑或地址计算。
- CU 还包含四个大型向量寄存器文件、四个针对 FP32 优化的向量执行单元和一个向量数据缓存。通常,向量管道是 16 宽的,每个 64 宽的wavefront在 4 个周期内执行。
- CU 通过 32KB 指令缓存获取指令,并通过调度器分发到执行单元。
- CU 一次最多可以处理 10 个wavefront,并将其指令分送到执行单元。
- 执行单元包含 256 个向量通用寄存器 (VGPR) 和 800 个标量通用寄存器 (SGPR)。VGPR 和 SGPR 动态分配给执行wavefront。
- wavefront最多可以访问 102 个标量寄存器。过多的标量寄存器使用会导致寄存器溢出,从而可能影响执行性能。
- wavefront可以占据 0 到 256 的任意数量的 VGPR,直接影响占用率;即 CU 中并发激活的wavefront的数量。例如,如果使用 119 个 VGPR,CU 中只能同时有两个wavefront处于激活状态。由于每条 SIMD 指令的指令延迟为 4 个周期,因此需要占用率应尽可能高,以便计算单元可以通过调度多个wavefront的指令来提高执行效率。
AMD CDNA 架构建立在 GCN 的标量和向量基础之上,并将矩阵添加为一等公民,同时增加了对机器学习新数据格式的支持,并保留了为 GCN 架构编写的任何软件的向后兼容性。这些矩阵核心引擎(Matrix Core Engine)增加了一个新的wavefront级指令系列,即矩阵融合乘加MFMA(Matrix Fused Multiply Add)。MFMA 系列指令执行混合精度运算,并使用四种不同类型的输入数据对 KxN 矩阵进行运算:8 位整数 (INT8)、16 位半精度 FP (FP16)、16 位brain FP (bf16) 和 32 位单精度 (FP32)。所有 MFMA 指令都产生 32 位整数 (INT32) 或 FP32 输出,降低了矩阵乘法最后累加阶段溢出的可能性。 不同的数据格式都有不同的推荐应用程序。业界普遍认为,
- INT8 数值主要用于使用量化权重或数据的 ML 推理,并且具有最佳吞吐量和最低的内存使用率。
- 大多数 ML 训练和一些 HPC 应用程序默认使用 IEEE FP32 数据,其中 8 位分配给指数用于范围,23 位分配给尾数以保持精度。
- FP16 是另一个 IEEE 标准,专为图形工作负载设计,使用 5 位指数和 10 位尾数。虽然 FP16 比 FP32 效率高得多,但对于 ML 训练需要调整算法以避免溢出和收敛问题。bfloat16 格式进行了折衷,使用 FP32 的 8 位指数,但将尾数截断为 7 位。bf16 数值更容易用于 ML 训练,收敛问题较少。
下图是AMD CDNA里CU的架构框图:
内存层次结构
AMD Instinct MI100 加速器的内存层次结构的最低级别位于 CU 内部,但大多数科学或机器学习数据集都以 GB 或 TB 为单位,并且会很快溢出到内存中。内存层次结构负责保存工作数据并将其有效地传送到计算阵列供计算使用。
L2 缓存在整个芯片上共享,并在物理上分区为多个 slice。对于 MI100,L2缓存是 16 路组关联的,总共包含 32 个slice(是 MI50 的两倍),总容量为 8MB。每个slice可以提供 64B/cycle,整个 GPU 的聚合带宽超过 3TB/s(32x64x1.5)。
AMD CDNA架构内存控制器以 2.4GT/s的速度驱动 4 层或 8 层封装的 HBM2 堆栈,总理论吞吐量为 1.23TB/s,容量32GB,提供硬件 ECC 保护。
系统扩展
AMD CDNA 架构使用基于标准的高速 AMD Infinity Fabric 技术连接到其他 GPU。Infinity Fabric 链路速率为 23GT/s ,与上一代类似,宽度为 16 位;但 MI100 有3个IF链路,可在4个 GPU中实现完全连接,提供更大的双分带宽并支持高度可扩展的系统,完全连接的拓扑提高了常见通信模式的性能,例如 all-reduce 和 scatter/gather。与 PCIe 不同,AMD Infinity Fabric 链路支持一致性的 GPU 内存,这使得多个 GPU 能够共享一个地址空间。

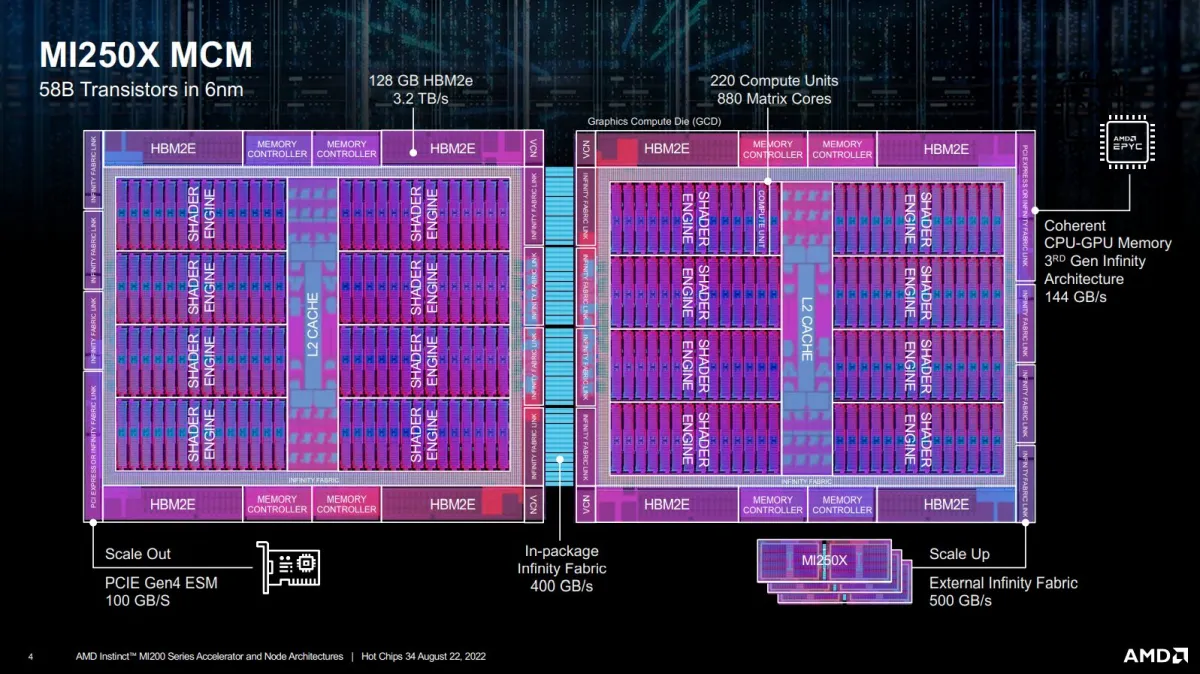
4.1 CDNA 2 - MI200
MI200是第二代CDNA架构,用于取代上一代MI100, MI200整体结构如下所示:
 通过Infinity Fabric, AMD利用封装技术将多个计算芯粒组成一个芯片,称为MCM(Multiple Chip Module)。
通过Infinity Fabric, AMD利用封装技术将多个计算芯粒组成一个芯片,称为MCM(Multiple Chip Module)。
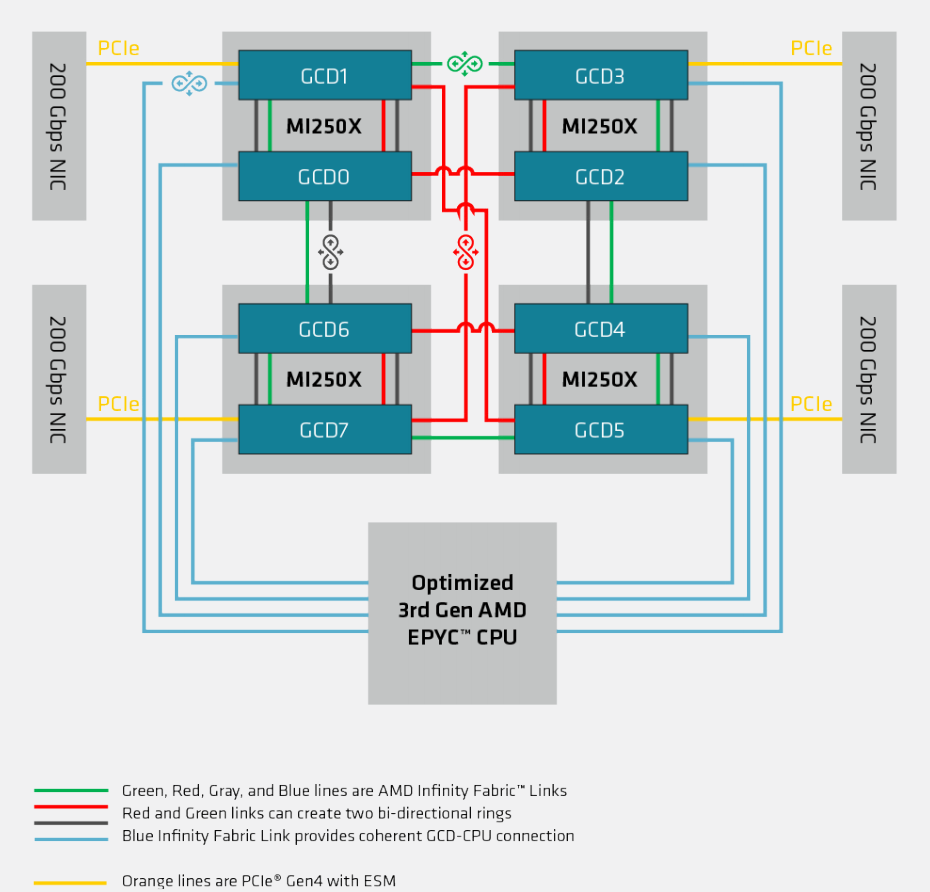
 两个主要的 MI200 加速器(MI250、MI250X)都使用这种方法,其中每个加速器由两个小芯片(“GCD”——图形计算芯片Graphics Compute Die)通过一致性的 4x Infinity Fabric 链路相互连接组成。通过使用多个更小尺寸、产量更高的 GCD 而不是一个大型单片芯片可以提高灵活性和可扩展性。然而,也带来了多个问题:
两个主要的 MI200 加速器(MI250、MI250X)都使用这种方法,其中每个加速器由两个小芯片(“GCD”——图形计算芯片Graphics Compute Die)通过一致性的 4x Infinity Fabric 链路相互连接组成。通过使用多个更小尺寸、产量更高的 GCD 而不是一个大型单片芯片可以提高灵活性和可扩展性。然而,也带来了多个问题:
- 首先,从软件的角度来看,单个加速器暴漏为两个独立的 GPU。这意味着算法需要具有多 GPU 感知能力,才能充分利用加速器。
- 其次,尽管通过 4 个高速 IF 链路连接,但芯片到芯片的互联带宽仍然远低于 HBM 内存带宽,导致在 GCD 之间移动数据相当痛苦,并且明显慢于内存访问。这实际上是 AMD 选择将加速器暴漏为两个不同的 GPU 的原因;互联带宽无法匹配两个芯片之间的 HBM 带宽。
这个缺点在 HPC 环境中不会有太大影响。HPC 代码旨在通过使用 MPI 通过高速网络同步和传递数据,从而跨多个节点进行扩展。双芯粒 MI250X 将简单地视为两个 GPU,具有特别快的链路用于在它们之间传递消息。
MI200 GCD的整体架构框图如下所示:
 总体而言,MI200 GCD 的计算架构在 MI100 的先前架构上采用了迭代、进化的方法。芯片分为 4 个计算引擎,每个引擎由一个异步计算引擎提供任务,每个计算引擎分为 2 个着色器引擎,每个着色器引擎有 14 个计算单元 (CU)。
总体而言,MI200 GCD 的计算架构在 MI100 的先前架构上采用了迭代、进化的方法。芯片分为 4 个计算引擎,每个引擎由一个异步计算引擎提供任务,每个计算引擎分为 2 个着色器引擎,每个着色器引擎有 14 个计算单元 (CU)。
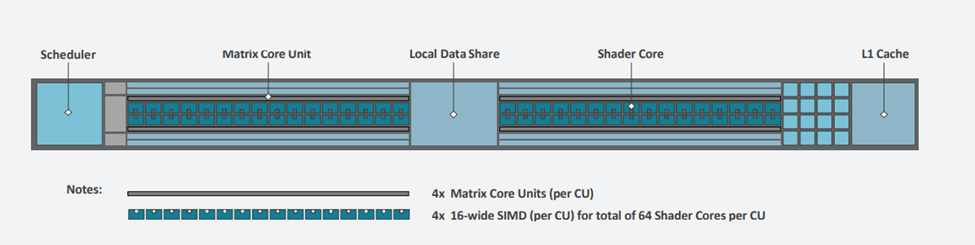
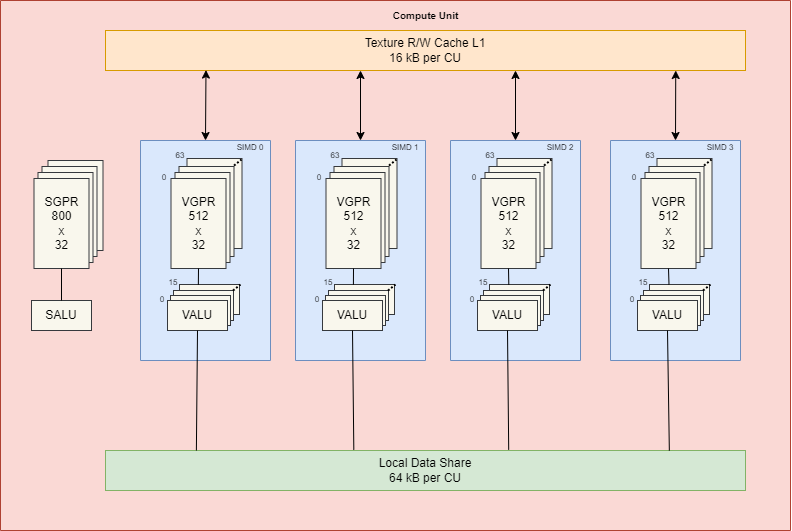
CU的结构框图如下所示:
 CU 的结构与 MI100 基本相同。每个 CU 都有
CU 的结构与 MI100 基本相同。每个 CU 都有
- 4 个 SIMD16 单元
- 4 个 Matrix Core 单元
- 一个调度器
- 一个 16KB 64 路 L1 缓存、提供 64B/CU/clk 带宽,
- 加载/存储单元
- 本地数据共享。
这里的主要区别在于 ALU 现在是原生的 64 位宽。这意味着 MI200 可以全速率执行 FP64,不仅相对于 MI100 的吞吐量增加了 2 倍,而且与 NVIDIA A100 相比也具有相当大的优势,并使 MI200 加速器在 FP64 中略差于下一代 NVIDIA H100。
AMD 还使用此功能支持Packed FP32 指令,从而使某些 FP32操作(FMA、FADD 和 FMUL)的吞吐量增加一倍。然而,这并不是免费的——它需要修改代码才能工作,因为操作数需要相邻并与偶数寄存器对齐。AMD 还包括专用的packed移动指令,对分散的操作数进行排序,以便可以适用packed FP32。寄存器分配是编译器的工作,而不是程序员的工作,但是对于packed FP32,需要指导编译器才能使用此功能,因此需要进行一些修改。
 从 MI100 开始,AMD 在 CU 中添加了矩阵单元。与 NVIDIA 的 Tensor Core 一样,矩阵单元可通过一组新指令进行访问。在 NVIDIA 和 AMD 上,矩阵指令打破了 SIMT 抽象模型,并在整个wavefront(或 NVIDIA 上的 “warp”)上工作。
从 MI100 开始,AMD 在 CU 中添加了矩阵单元。与 NVIDIA 的 Tensor Core 一样,矩阵单元可通过一组新指令进行访问。在 NVIDIA 和 AMD 上,矩阵指令打破了 SIMT 抽象模型,并在整个wavefront(或 NVIDIA 上的 “warp”)上工作。
矩阵操作在两边都有点奇怪。NVIDIA 依赖于向量寄存器文件中的特殊布局。AMD 添加了第二个累加寄存器文件。对于 A * B + C 矩阵运算,MFMA 指令可以从任一寄存器文件获取 A 和 B,但 C 必须来自累加器寄存器文件。
 CDNA2 通过删除单独的累加器 RF,提供一个大的统一寄存器文件来改进这一点。在 MI100 中,每个 SIMD16 单元都有 256 个“架构”向量通用寄存器 (VGPR),矩阵核心单元还有 256 个“累加器”寄存器。MI200 将这两者合并为一个具有 512 个条目的统一寄存器文件。对于矩阵运算,统一寄存器文件消除了在寄存器文件之间移动值的潜在麻烦,以确保累加器输入可以来自累加器寄存器文件。统一寄存器文件增加的条目数还有助于减少寄存器压力,并在运行非矩阵代码时可以增加占用率。
CDNA2 通过删除单独的累加器 RF,提供一个大的统一寄存器文件来改进这一点。在 MI100 中,每个 SIMD16 单元都有 256 个“架构”向量通用寄存器 (VGPR),矩阵核心单元还有 256 个“累加器”寄存器。MI200 将这两者合并为一个具有 512 个条目的统一寄存器文件。对于矩阵运算,统一寄存器文件消除了在寄存器文件之间移动值的潜在麻烦,以确保累加器输入可以来自累加器寄存器文件。统一寄存器文件增加的条目数还有助于减少寄存器压力,并在运行非矩阵代码时可以增加占用率。
 MI200 中的矩阵核心单元还支持全速率 FP64,与 MI100 相比,CU 每个周期的 FP64 FLOPS 增加了 4 倍。较低精度的矩阵计算的吞吐量也有所增加,相比MI100,CU每个时钟的 BF16 吞吐量翻了一番。此外,还为 16x16x4 和 4x4x4 模块引入了功耗更低的矩阵指令。
MI200 CU 中的 LDS 改进原子操作,并支持 FP64 原子。这些变化反映并加强了 AMD 在其服务器 GPU 中采用的以 HPC 为中心的方法,非常注重双精度向量性能,而不是较低的精度或矩阵性能。MI250X 的矩阵单元比 CDNA1 中的矩阵单元有所改进,但仍然只能与NVIDIA的 FP64 每 CU/SM 时钟吞吐量相匹配。在处理较低精度的格式时NVIDIA仍然提供更高的矩阵吞吐量,这使得 Hopper 成为 ML 和 AI 工作负载的更好选择。
MI200 中的矩阵核心单元还支持全速率 FP64,与 MI100 相比,CU 每个周期的 FP64 FLOPS 增加了 4 倍。较低精度的矩阵计算的吞吐量也有所增加,相比MI100,CU每个时钟的 BF16 吞吐量翻了一番。此外,还为 16x16x4 和 4x4x4 模块引入了功耗更低的矩阵指令。
MI200 CU 中的 LDS 改进原子操作,并支持 FP64 原子。这些变化反映并加强了 AMD 在其服务器 GPU 中采用的以 HPC 为中心的方法,非常注重双精度向量性能,而不是较低的精度或矩阵性能。MI250X 的矩阵单元比 CDNA1 中的矩阵单元有所改进,但仍然只能与NVIDIA的 FP64 每 CU/SM 时钟吞吐量相匹配。在处理较低精度的格式时NVIDIA仍然提供更高的矩阵吞吐量,这使得 Hopper 成为 ML 和 AI 工作负载的更好选择。
内存层次结构
每个 GCD 都有一个 8MB 的 16 路 L2 缓存,物理分区为 32 个切片,BW 为 128B/clk/slice,总带宽为 4096B/clk,是 MI100 的 L2 带宽的两倍。与 LDS 一样, MI200 中L2 原子操作也得到了增强,增加了对 FP64 原子的支持。
在内存方面,每个 MI200 GCD 支持4 个 3.2 Gbps HBM2E,容量64GB; 物理上一共 32 个通道,在有效电压下带宽为 64B/clk;每个 GCD一共 1.6 TB/s 的内存带宽,带宽比 MI100 增加了 33%,内存容量增加了 100%。
 与 CDNA 相比,CDNA2 GCD 里CU 略少,但提供了更多的缓存和内存带宽。这种带宽增加可能是必要的,因为 CDNA2 计算单元可以全速率处理 FP64,而 FP64 消耗的内存和内存带宽是 FP32 的两倍。AMD 的 HPC 和消费类 GPU 架构在过去几年中越来越分化,CDNA2 和 RDNA2 的内存子系统截然不同。RDNA2 将廉价的 256 位 GDDR6 设置与非常复杂的缓存层次结构相结合,而 CDNA2 具有简单的两级缓存结构,但是巨大的 L2 和 DRAM 带宽。。
与 CDNA 相比,CDNA2 GCD 里CU 略少,但提供了更多的缓存和内存带宽。这种带宽增加可能是必要的,因为 CDNA2 计算单元可以全速率处理 FP64,而 FP64 消耗的内存和内存带宽是 FP32 的两倍。AMD 的 HPC 和消费类 GPU 架构在过去几年中越来越分化,CDNA2 和 RDNA2 的内存子系统截然不同。RDNA2 将廉价的 256 位 GDDR6 设置与非常复杂的缓存层次结构相结合,而 CDNA2 具有简单的两级缓存结构,但是巨大的 L2 和 DRAM 带宽。。
NVIDIA 的缓存方法与 AMD 的相反,在消费类和 HPC 中都提供高的 DRAM 带宽。消费类 GA10x 芯片有高达 6 MB 的 L2,并使用高功耗、高带宽的 GDDR6X 。相比之下,面向 HPC 的 A100 具有 40 MB 的 L2,由 HBM2 提供支持。NVIDIA Hopper 架构类似,并带来了由 HBM3 支持的 50 MB L2。
互联 – Infinity Architecture 3
高速连接是超级计算机与任何旧商用硬件的区别。HPC 程序通过在节点之间传递消息(使用 MPI 等 API)来跨多个节点进行扩展。因此,高速连接对于确保良好的扩展至关重要。HPC 集群还需要复杂的链路拓扑,以便在任意两个节点之间提供尽可能多的带宽,同时最大限度地减少所需的链路数量。MI250X 引入了更复杂的 IF 链路设置,以尽可能最大化带宽。
- AMD 略微增加了 IF 链路带宽。MI100 的 IF 链路每个方向宽 16 位,以 23 GT/s 的速度运行,每个方向提供 46 GB/s 的带宽,或总计 92 GB/s。MI250X 的 IF 链路保持 16 位宽,但传输速率增加,每个方向提供 50 GB/s,或总计 100 GB/s。
- AMD 通过不同类型的物理接口提供了更多的 IF 链路,以在物理限制内最大限度地提高带宽。
- 四个 IF 链路具有封装内接口,允许同一封装芯片中的两个 GCD 以 400 GB/s 的带宽相互通信。
- 其余三个 IF 链路具有封装间接口,用于与其他 GCD 和主机 CPU 通信。与 MI100 中每个 GPU 三个 IF 链路允许完全连接4个GPU拓扑结构不同 ,MI250X 需要更复杂的拓扑。因为每个 MI250X 卡基都是一个双 GPU 板卡,所以对于1个由4个GPU组成的 HPC 需要连接8个 GCD。AMD 为每个 GCD 提供与对等 MI250X 卡中的两个 GCD 的直接链接。当跨 GCD 通信需要额外的跃点时,可以通过高带宽的封装内链接。这可避免在较低带宽的片间链路上造成拥塞。
 AMD 使用 GCD 的第三个片间 IF 链路连接到 CPU。此链路仅在 IF 模式下运行,使用经过专门优化的第 3 代 EPYC CPU(Frontier 中使用的 AMD Trento 平台)。这允许 CPU 和 GPU 之间保持缓存一致性,其中 CPU 缓存其内存和 MI250X 中HBM 内存 。当与其他常规 x86 CPU 连接时,该链路的行为类似于常规 PCIe x16 接口。
AMD 使用 GCD 的第三个片间 IF 链路连接到 CPU。此链路仅在 IF 模式下运行,使用经过专门优化的第 3 代 EPYC CPU(Frontier 中使用的 AMD Trento 平台)。这允许 CPU 和 GPU 之间保持缓存一致性,其中 CPU 缓存其内存和 MI250X 中HBM 内存 。当与其他常规 x86 CPU 连接时,该链路的行为类似于常规 PCIe x16 接口。
MI200 的另一个重大变化是增加了一个下游 25Gbps PCIe 4.0 ESM 链路。这个下游接口耦合到 PCIe RC,使 GPU 能够驱动连接到它的 I/O 设备。因此,GPU 可以直接管理连接到它的设备,而不必依赖 CPU 进行管理。此功能对于超级计算集群中的高带宽的网卡特别有用。进出 IO 设备的流量通常由 DRAM 提供支持,这意味着通过网络控制器移动大量数据可能会占用大量 DRAM 带宽。将 NIC 直接连接到 MI250X GPU 允许 AMD 使用 GPU 的 HBM 内存支持网络流量,该内存带宽比 CPU 的 DDR4 多得多。
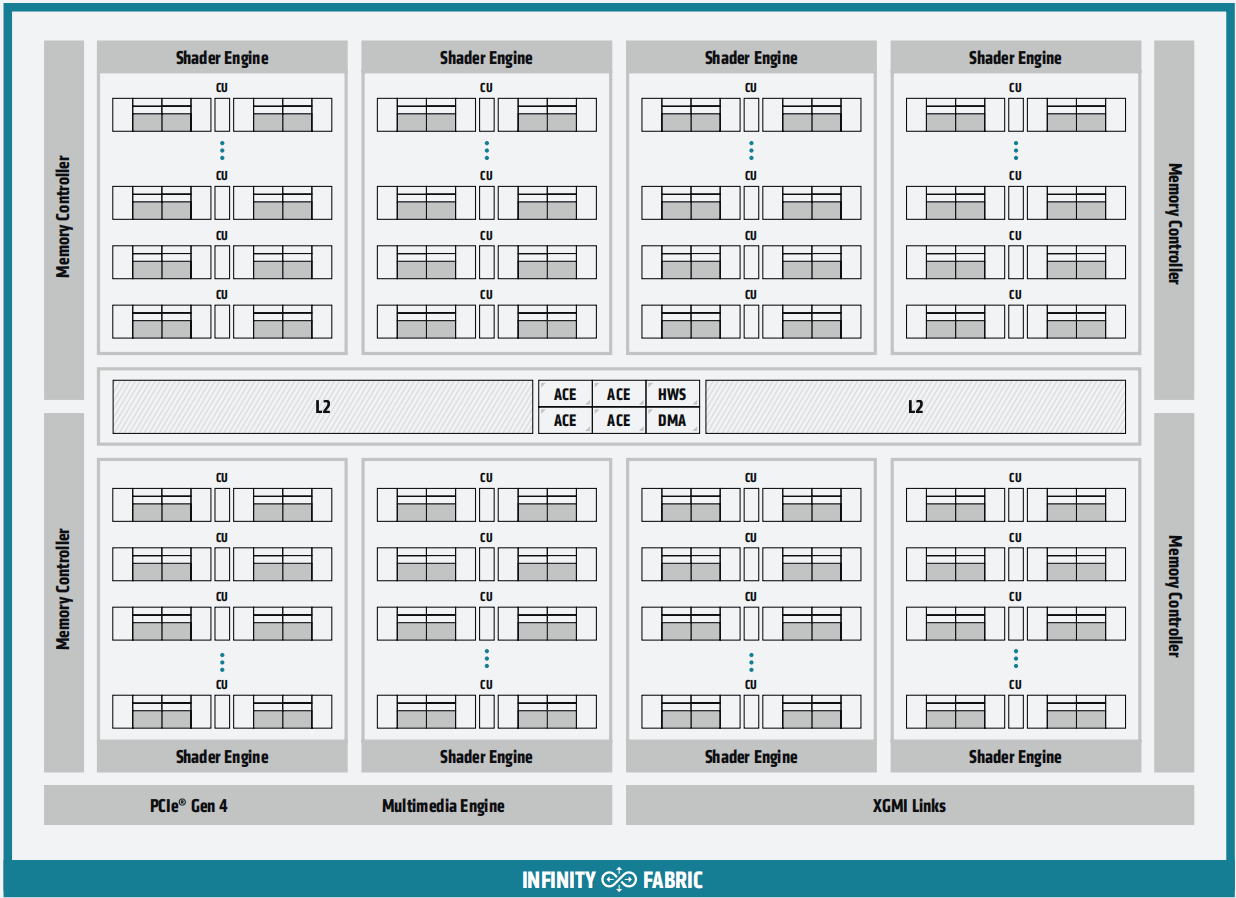
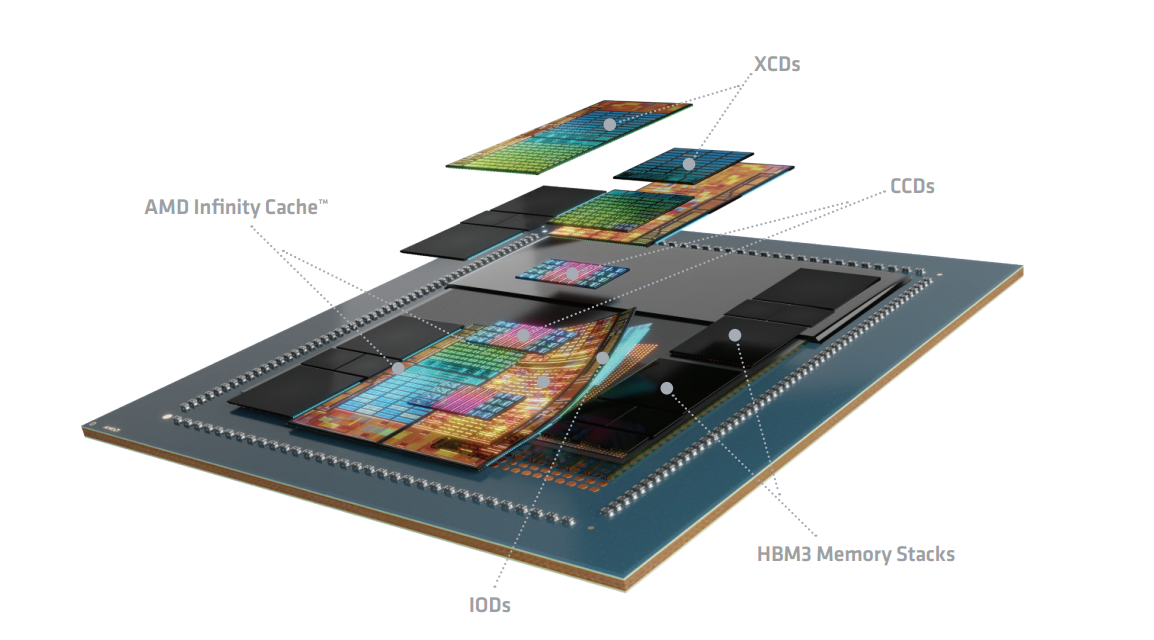
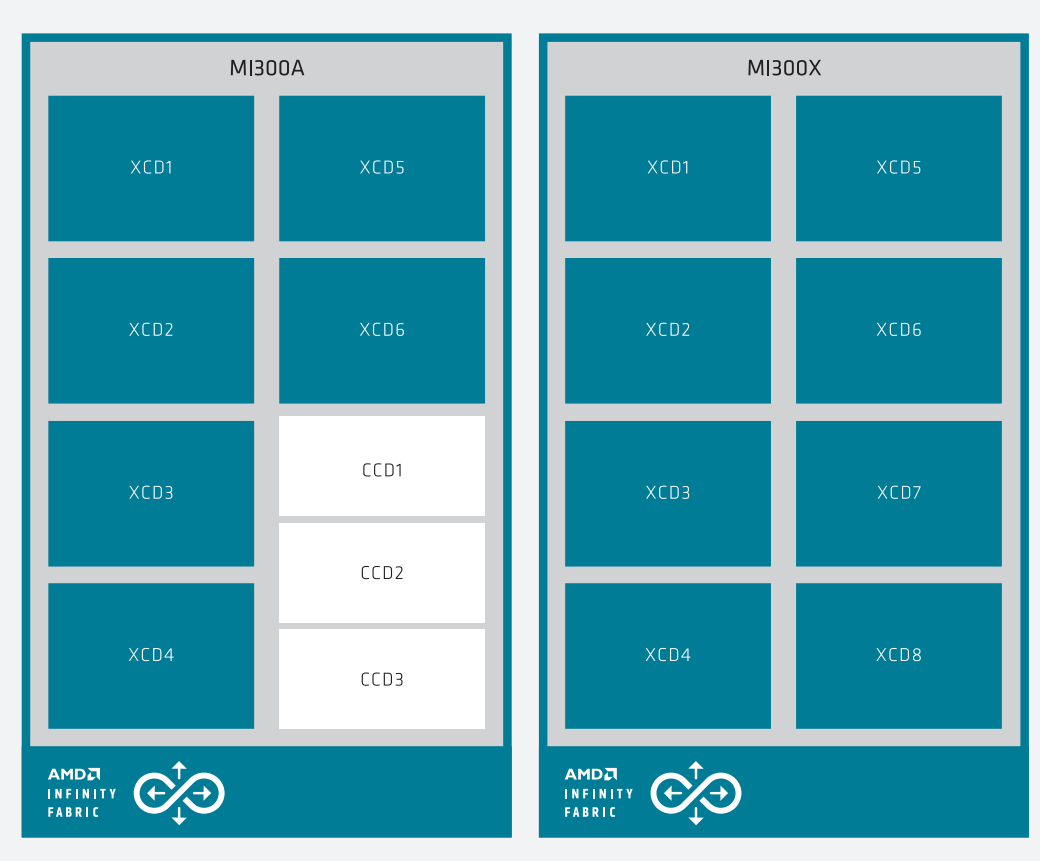
4.2 CDNA 3 - MI300
如下图所示,CDNA 3架构利用了最新 3D 封装技术,并从根本上将处理器的计算、内存和通信单元重新分区到异构封装中。MI300 系列集成了多达 8 个垂直堆叠的加速器复合芯粒 (XCD) 和 4 个包含系统基础功能的 I/O 芯粒 (IOD),通过AMD Infinity Fabric连接,并提供 8 个高带宽内存 (HBM) 堆栈。在微架构层面,GPU 内核中向量和矩阵数据的计算吞吐量通过对稀疏数据的支持得到增强。在宏观层面,这种对物理实现的彻底重新思考与完全重新设计的缓存和内存层次结构相结合,该层次结构可以随着计算的增加而优雅扩展,并且还将缓存一致性作为一等公民。
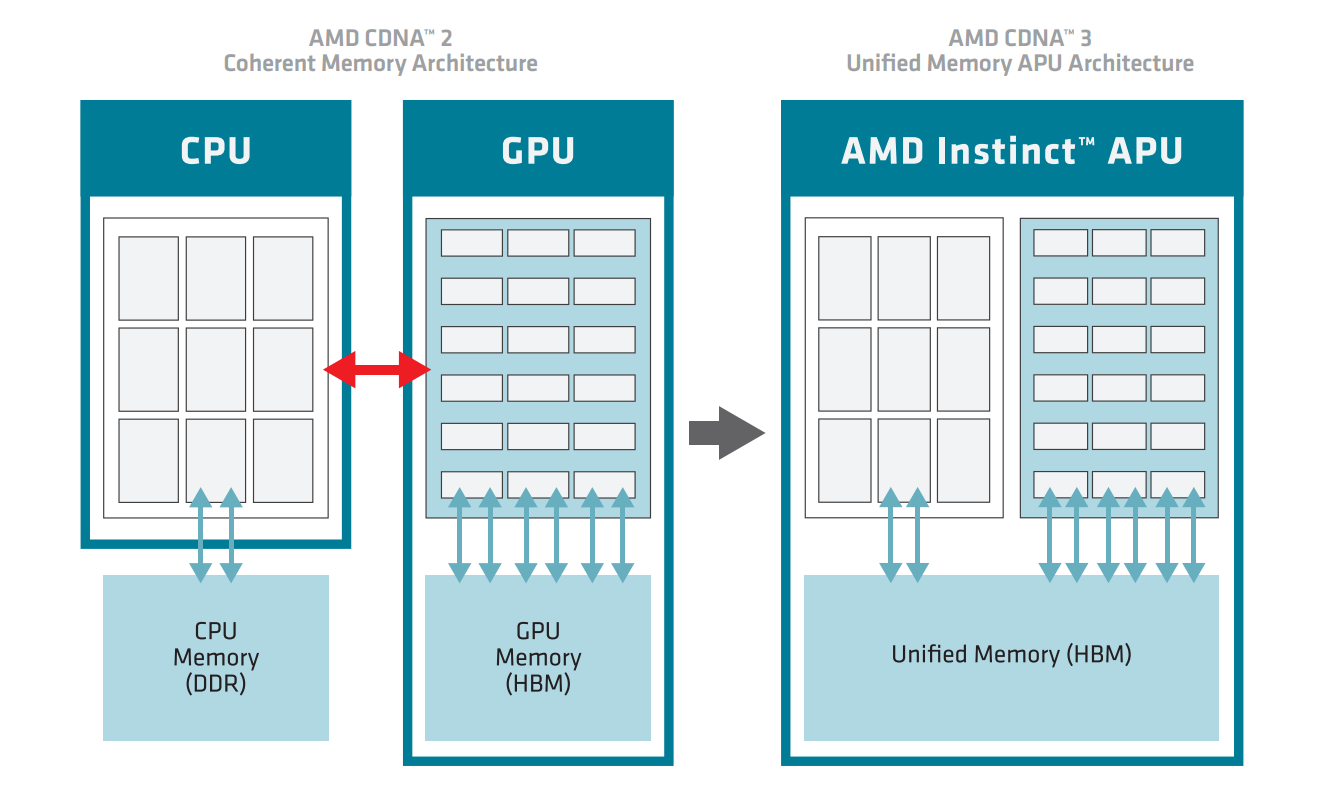 这种架构为构建 AMD CDNA 3 变体提供了多功能性,例如 MI300X 独立 GPU 或 MI300A APU,如下图所示。
这种架构为构建 AMD CDNA 3 变体提供了多功能性,例如 MI300X 独立 GPU 或 MI300A APU,如下图所示。
- MI300X 独立 GPU 主要专注于加速器计算,并包含 8 个加速器复杂芯粒 (XCD)。对于机器学习中常见的低精度数据,MI300X 独立 GPU 提供了显著的代际性能提升,峰值吞吐量为 3.4-6.8 倍,峰值理论 FP8 性能为 2.6 PFLOP/s。对于使用单精度和双精度的传统 HPC 工作负载,计算吞吐量提高了 1.7-3.4 倍,为单个处理器提供了 163.4 TFLOP/S FP64 矩阵计算能力。
- MI300A APU 将 CPU、GPU 和内存集成在一个封装内。相比MI300X加速器,计算能力降低了 25%,为3个基于 x86 的“Zen 4”CPU 芯粒腾出空间,与 6 个 GPU 芯粒紧密耦合。APU 共享单个虚拟内存和物理内存池,延迟极低。MI300A 是世界上第一款高性能数据中心 APU,通过消除主机/设备数据拷贝,并为开发人员带来极大的易用性,并通过消除 DIMM 和 CPU 到 GPU 通信链路等组件,在系统级别降低功耗和面积。
AMD CDNA 3 计算架构
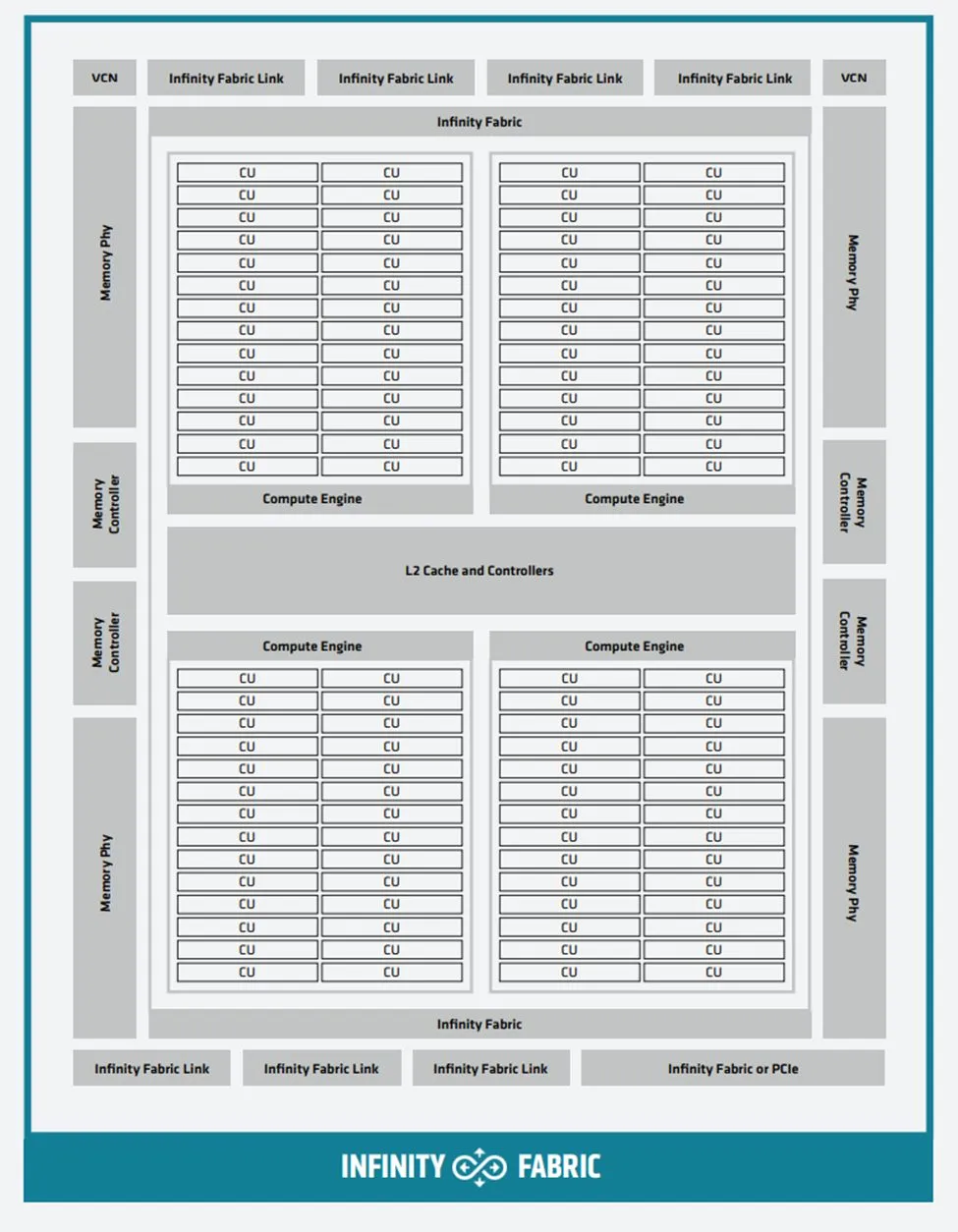
计算能力由加速器复合芯粒 (XCD)提供,它包含处理器的计算单元以及缓存层次结构的最低级别,并采用 TSMC 5nm 工艺制造。整体架构如下所示:
 如上图所示,每个 XCD 都包含一组共享的全局资源,包括调度程序、硬件队列和四个异步计算引擎 (ACE),这些引擎负责将计算着色器工作组分发到计算单元 (CU),这些计算单元是 AMD CDNA 3 架构的计算核心。四个 ACE 分别与 40 个 CU 相关联,但只有 38 个活动 CU,其中 2 个用于良率管理而被禁用。38 个 CU 共享一个 4MB 的 L2 缓存,用于聚合芯粒的所有内存流量。相比 AMD Instinct MI200,AMD CDNA 3 XCD 芯粒更小,CU数量 不到一半,但使用更先进的封装,芯片一共包括 6-8 个 XCD,总共多达 304 个 CU,比 MI250X 多出约 40%。
如上图所示,每个 XCD 都包含一组共享的全局资源,包括调度程序、硬件队列和四个异步计算引擎 (ACE),这些引擎负责将计算着色器工作组分发到计算单元 (CU),这些计算单元是 AMD CDNA 3 架构的计算核心。四个 ACE 分别与 40 个 CU 相关联,但只有 38 个活动 CU,其中 2 个用于良率管理而被禁用。38 个 CU 共享一个 4MB 的 L2 缓存,用于聚合芯粒的所有内存流量。相比 AMD Instinct MI200,AMD CDNA 3 XCD 芯粒更小,CU数量 不到一半,但使用更先进的封装,芯片一共包括 6-8 个 XCD,总共多达 304 个 CU,比 MI250X 多出约 40%。
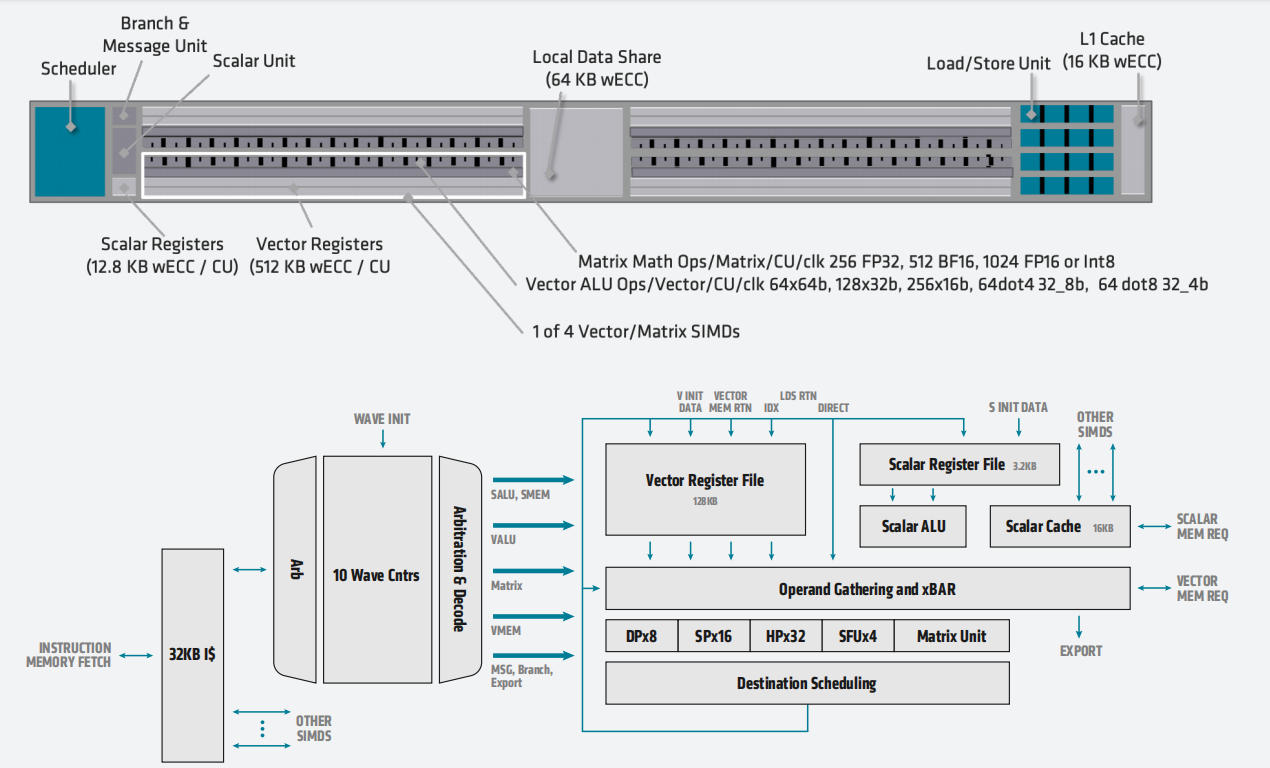
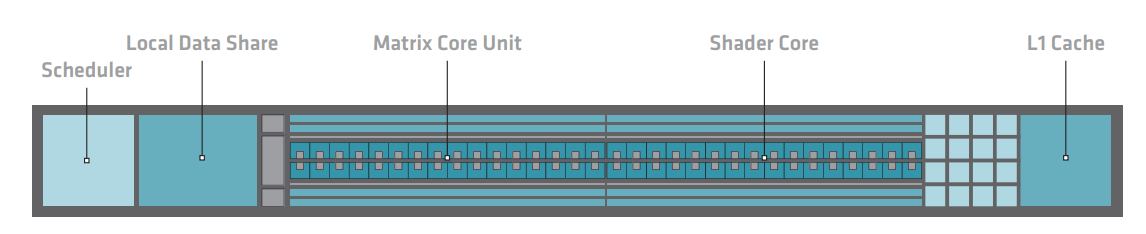
如下图所示,AMD CDNA 3 计算单元是完整的、高度线程化的并行处理器内核,包括指令获取和调度,标量、向量和矩阵执行单元,以及包含 L1 缓存和本地数据共享 (LDS) 的加载/存储流水线,这些构成了内存层次结构的起点。虽然计算单元在架构上与 AMD CDNA 2 中的计算单元相似,但进行了全面改进,整个内核都进行了重大更改,几乎在每个级别都利用了更高的并行性,在许多情况下,每个 CU的向量和矩阵工作负载的性能提高了一倍甚至四倍。
 指令缓存在两个 CU 之间共享,比上一代的容量增加了一倍,达到 64KB,8 路组相联。这种结构利用了这样一个现实,即在绝大多数情况下,相同的指令流将由一组 CU 执行,因此增加可缓存窗口和命中率,同时保持芯片面积几乎不变。AMD CDNA 3 CU 改进了源缓存,以提供更好的重用和带宽放大,以便每个向量寄存器读取都可以支持更多的下游向量或矩阵操作。
指令缓存在两个 CU 之间共享,比上一代的容量增加了一倍,达到 64KB,8 路组相联。这种结构利用了这样一个现实,即在绝大多数情况下,相同的指令流将由一组 CU 执行,因此增加可缓存窗口和命中率,同时保持芯片面积几乎不变。AMD CDNA 3 CU 改进了源缓存,以提供更好的重用和带宽放大,以便每个向量寄存器读取都可以支持更多的下游向量或矩阵操作。
AMD CDNA 3 CU 的最大改进在于矩阵内核Matrix Core,通过提高通常用于尖端训练和推理的现有数据类型的吞吐量,以及添加全新的数据类型来支持人工智能和机器学习。机器学习性能的最大杠杆之一是采用更紧凑的数据类型,可以节省内存和缓存容量,提高吞吐量并降低功耗。十年前,大多数机器学习应用程序都依赖于 FP32,但随着时间的推移,社区使用越来越小的数据类型。为了实现最佳训练性能,AMD CDNA 2 矩阵内核支持 FP16 和 BF16,同时提供 INT8 进行推理。AMD CDNA 3 矩阵内核将 FP16 和 BF16 的性能提高了三倍,同时与上一代 MI250X 加速器相比,INT8 的性能提高了 6.8 倍。为了提高 AI 性能,AMD CDNA 3还支持FP8和TF32。
AMD CDNA 3 计算单元中的 LDS 保持在 64KB,类似于 AMD CDNA 2 计算单元。L1 向量数据缓存负责提供数据到向量寄存器文件和 LDS 中,并使执行单元得到充分利用。随着 AMD CDNA 3 计算单元吞吐量的显著提高,向量数据缓存大幅改进以在多个维度上匹配。缓存行大小翻了一番,达到 128B,L1 数据缓存容量也翻了一番,达到 32KB,提高了命中率并减轻了外部缓存级别的压力。此外,从数据缓存到内核本身的请求总线以及从 L2 的填充路径扩展以匹配新的缓存行,从而使内核的带宽增加一倍。保持不变的一点是,向量数据缓存具有非常宽松的一致性模型,需要显式同步才能保持一致性和顺序。
AMD CDNA 3内存层次结构
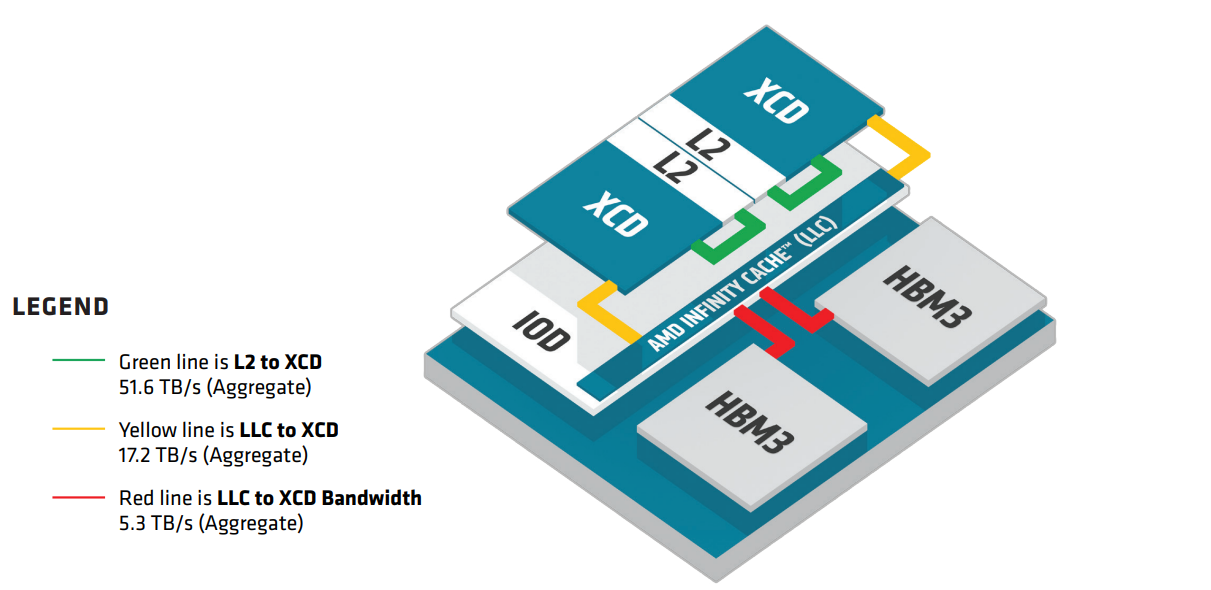
AMD CDNA 3 架构中最大的变化在于计算单元之外的内存层次结构,该架构已完全重新设计,以充分利用异构小芯片,并为 APU 产品中共同封装的 CPU 小芯片实现缓存一致性。这种内存层次结构的重新设计从 XCD 中的共享 L2 缓存开始。随着 AMD Infinity Cache 的加入,L2 缓存的作用发生了根本性的变化,AMD Infinity Cache 是位于有源 I/O 芯粒 (IOD) 上的最后一级缓存 (LLC)。下图显示了新的内存架构:
 一些更面向内存的功能已被删除并转移到 AMD Infinity Cache,而其他方面则是新的或更突出的。例如,L2 发挥着关键的新作用,因为它是最低级别的缓存,一致性由硬件自动维护。同时,它经过重新设计,为 CU 提供更丰富的资源组合,同时将它们与一致性流量隔离,并优化了与 AMD Infinity Fabric互联网络的接口。L2 的容量是 4MB,16 路组相联,分成16 个通道,每个通道 256KB。L2 缓存由所有 38 个计算单元共享,并为来自较低级别的指令和数据缓存的请求服务。在读取端,每个通道可以读出一条 128 字节的缓存行,而 L2 缓存每个周期可以接受来自不同 CU 的四个请求,每个 XCD 的总吞吐量为 2KB/时钟。16 个通道仅支持半行 64 字节写入,每个通道每个时钟有一个来自 Infinity Fabric 的填充请求。AMD CDNA 2 的每个 L2 缓存实际上有 32 个通道,但最多只有两个实例,而 AMD CDNA 3 总共有多达 8 个实例和高达 34.4 TB/s 的聚合读取带宽。
一些更面向内存的功能已被删除并转移到 AMD Infinity Cache,而其他方面则是新的或更突出的。例如,L2 发挥着关键的新作用,因为它是最低级别的缓存,一致性由硬件自动维护。同时,它经过重新设计,为 CU 提供更丰富的资源组合,同时将它们与一致性流量隔离,并优化了与 AMD Infinity Fabric互联网络的接口。L2 的容量是 4MB,16 路组相联,分成16 个通道,每个通道 256KB。L2 缓存由所有 38 个计算单元共享,并为来自较低级别的指令和数据缓存的请求服务。在读取端,每个通道可以读出一条 128 字节的缓存行,而 L2 缓存每个周期可以接受来自不同 CU 的四个请求,每个 XCD 的总吞吐量为 2KB/时钟。16 个通道仅支持半行 64 字节写入,每个通道每个时钟有一个来自 Infinity Fabric 的填充请求。AMD CDNA 2 的每个 L2 缓存实际上有 32 个通道,但最多只有两个实例,而 AMD CDNA 3 总共有多达 8 个实例和高达 34.4 TB/s 的聚合读取带宽。
L2 是一种写回和写分配设计,旨在聚合并减少从 AMD Infinity Fabric 到 AMD Infinity Cache 的访问次数。L2 本身在 XCD 中是保持一致性的。Infinity Cache 包括一个覆盖多个 XCD L2 缓存的监听过滤器(snoop filter),因此来自其他 XCD 的绝大多数一致性请求将在 Infinity Cache 中解析,而不会干扰高度利用的 L2 缓存。
异构集成使 AMD CDNA 3 架构能够整合大量专用于内存层次结构的硅面积。IOD 采用台积电的 6nm 工艺制造,垂直堆叠在一对 XCD 下方,包含全新的 AMD Infinity Cache 和HBM3 接口,并通过 AMD Infinity Fabric 互联网络连接到系统的其余部分。L2 充当每个 XCD 的单点接口,在溢出到 IOD 之前,将所有进出 38 个 CU 的本地内存流量聚合在一起。通道的概念起源于 L2(每个 L2 包含 16 个通道),但在 IOD 及其他内存层次结构的其余部分都至关重要。每个 L2 通过 16 个通道连接到 IOD,每个通道的宽度为 64B,在 IOD 接口上每个 XCD 总共 1KB。
AMD Infinity Cache 是 AMD CDNA 3 架构的全新结构,它通过增加缓存带宽和减少片外内存访问的数量来提高代际性能和效率。通常,GPU 缓存与内存控制器更紧密地对齐并在物理上位于同一位置,对于 AMD CDNA 3 架构来说尤其如此。AMD Infinity Cache 经过精心设计为共享内存侧缓存,这意味着它可以缓存内存数据,并且无法保存从较低级别缓存中驱逐的脏数据。这有两个显着的好处。首先,AMD Infinity Cache 不参与一致性,也不必吸收或处理任何监听流量,这显着提高了效率并减少了从较低级别缓存监听的延迟。其次,它实际上可以保存名义上不可缓存的内存,例如 I/O 缓冲区。
就像 L2 缓存一样,AMD Infinity Cache 是 16 路组相联,并围绕通道的概念构建的。每个 HBM 内存堆栈与 16 个并行通道相关联。一个通道宽 64 字节,连接到 2 MB 的数据阵列支持同时读取和写入。四个 IOD 总共有 8 个 HBM 堆栈,一共 128 个通道和 256MB 数据阵列。Infinity Cache 的峰值带宽达到惊人的 17.2 TB/s,几乎与上一代 L2 缓存的总带宽一样大。除了 AMD Infinity Cache 之外,每个 IOD 通过封装扇出到两个内存堆栈。AMD CDNA 3 架构将内存接口从 HBM2e 升级到最新的 HBM3,速率5.2Gbps,每个堆栈包含 16GB 或 24GB 内存。总的来说,MI300A上容量是128GB 和 MI300X 上的 HBM3 内存容量是192GB, 峰值理论内存带宽是5.3 TB/s 。此外,在 MI300A 中,HBM3 内存在 GPU 和 CPU 之间统一共享,从而大大降低了延迟并提高了通信吞吐量。如下图所示,
片间互联和扩展
AMD CDNA 2 架构在采用第 3 代 AMD Infinity 架构的功能方面取得了巨大飞跃,包括封装内、封装之间和主机处理器的 AMD Infinity Fabric 技术。AMD CDNA 3 架构在封装内部更广泛地使用第 4 代 Infinity 架构,将通信和扩展提升到一个新的水平,并全面提高了效率和性能。然而,AMD CDNA 3 系列的异构集成为 AMD 提供了独特的机会,可以通过 AMD Instinct MI300X 独立 GPU 和 AMD Instinct MI300A APU 在两个不同的方向上推动可扩展性。对于 AMD CDNA 3,通信链路速率为 32Gbps ,并在 IOD 之间重新分配。每个 IOD 包括两个 16 通道双向封装间 AMD Infinity Fabric 链路,用于连接其他 AMD 加速器。其中一个链路是多用途的,可以配置为 x16 PCIe Gen 5,以实现纯 I/O 功能。
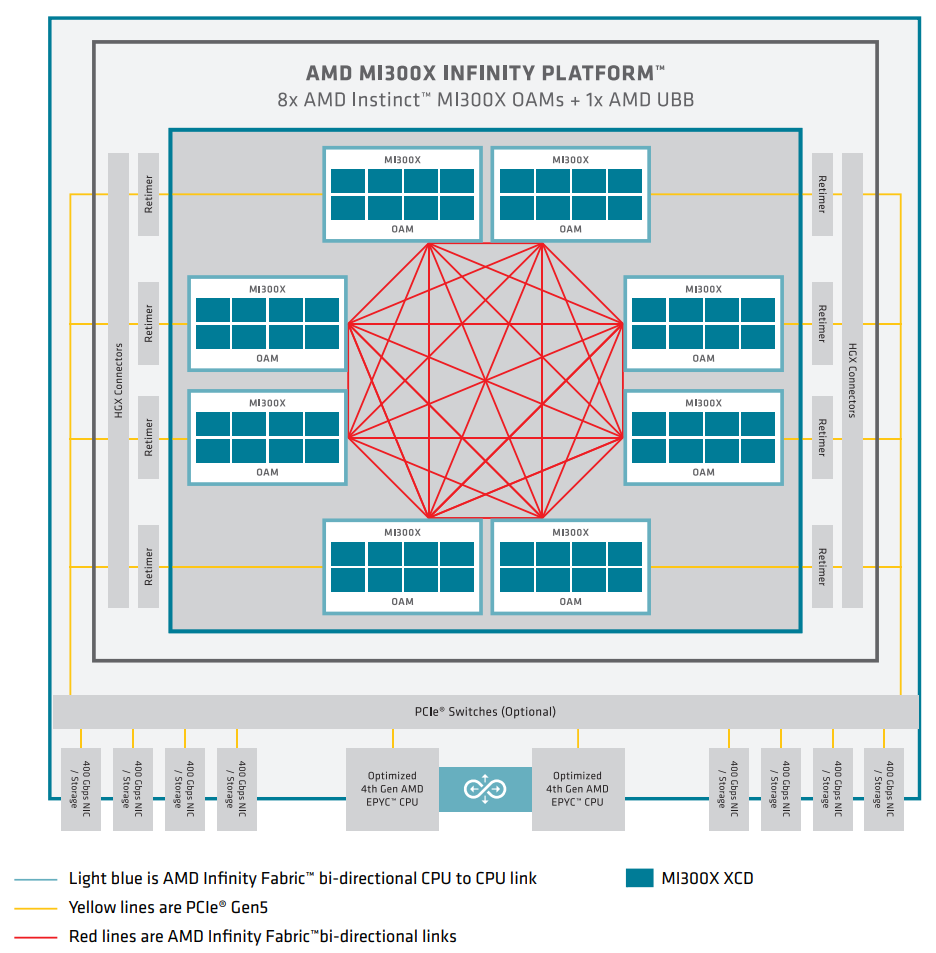
 如上图所示,MI300X 独立 GPU 使用7个高带宽和低延迟的 AMD Infinity Fabric 链路来形成一个完全连接的 8-GPU 系统。每个 GPU 还通过 x16 PCIe Gen 5 链路连接到主机 CPU。这种方法通常使用 OCP 通用基板 (UBB) 外形尺寸,该外形尺寸基于各种行业标准技术构建,可轻松构建和部署系统。与上一代相比,这个 8 GPU 节点本质上更快、更高效,可用于 allreduce 和 allgather 等通信模式,这些通信模式用于机器学习的梯度求和和数据并行分片。对于 MI300A APU,CPU 内核和统一内存的封装集成更具变革性。在上一代产品中,AMD EPYC 处理器和 MI250X GPU 通过两个 AMD Infinity Fabric 链路连接,带宽 144GB/s,延迟是封装级别的。在 MI300A APU 上,封装内的 AMD Infinity Fabric 以芯粒内延迟和接口吞吐量将加速器复合体芯片 (XCD) 和 CPU 复合芯片 (CCD) 直接连接到共享的 Infinity Cache 和 8 堆栈的 HBM3 堆栈中。在节点级别,MI300A APU 还在处理器之间提供比上一代更大的结构带宽。许多 HPC 系统专注于 4 处理器节点,如下图所示,每个处理器都使用两个带宽为 256GB/s 的 AMD Infinity Fabric 链路与其对等节点完全连接。
如上图所示,MI300X 独立 GPU 使用7个高带宽和低延迟的 AMD Infinity Fabric 链路来形成一个完全连接的 8-GPU 系统。每个 GPU 还通过 x16 PCIe Gen 5 链路连接到主机 CPU。这种方法通常使用 OCP 通用基板 (UBB) 外形尺寸,该外形尺寸基于各种行业标准技术构建,可轻松构建和部署系统。与上一代相比,这个 8 GPU 节点本质上更快、更高效,可用于 allreduce 和 allgather 等通信模式,这些通信模式用于机器学习的梯度求和和数据并行分片。对于 MI300A APU,CPU 内核和统一内存的封装集成更具变革性。在上一代产品中,AMD EPYC 处理器和 MI250X GPU 通过两个 AMD Infinity Fabric 链路连接,带宽 144GB/s,延迟是封装级别的。在 MI300A APU 上,封装内的 AMD Infinity Fabric 以芯粒内延迟和接口吞吐量将加速器复合体芯片 (XCD) 和 CPU 复合芯片 (CCD) 直接连接到共享的 Infinity Cache 和 8 堆栈的 HBM3 堆栈中。在节点级别,MI300A APU 还在处理器之间提供比上一代更大的结构带宽。许多 HPC 系统专注于 4 处理器节点,如下图所示,每个处理器都使用两个带宽为 256GB/s 的 AMD Infinity Fabric 链路与其对等节点完全连接。

AMD CDNA 4 计算架构
First off, a check on where we are at in the journey. In 2023, AMD shipped the Instinct MI300 series. The MI300A found great success at places like HPC with El Capitan (and the GIGABYTE G383-R80-AAP1) while the MI300X series did well at Microsoft Azure for AI. The MI325X is effectively an update to the MI300X much like the NVIDIA H200 updates the H100. The MI350 series is more than that with some architectural changes an a pivot to focus more on AI than HPC.
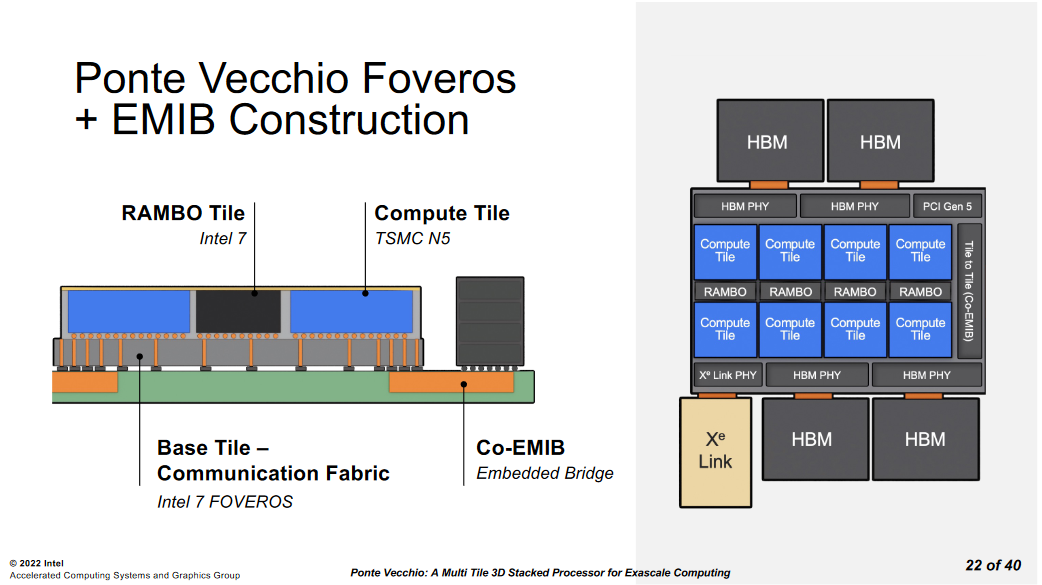
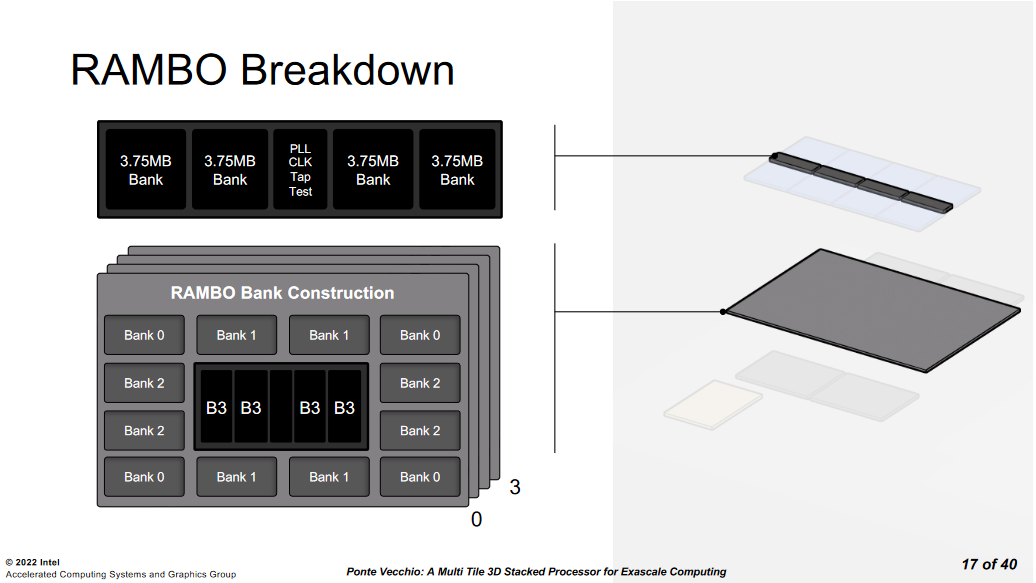
 the AMD Instinct MI350 is built in a similar manner to the MI300 and MI325 with the 3D Integration. The new accelerator compute die (XCD) is now on N3P process versus N5 in the previous generation. The I/O die (IOD) is between those XCDs and the interposer.
the AMD Instinct MI350 is built in a similar manner to the MI300 and MI325 with the 3D Integration. The new accelerator compute die (XCD) is now on N3P process versus N5 in the previous generation. The I/O die (IOD) is between those XCDs and the interposer.
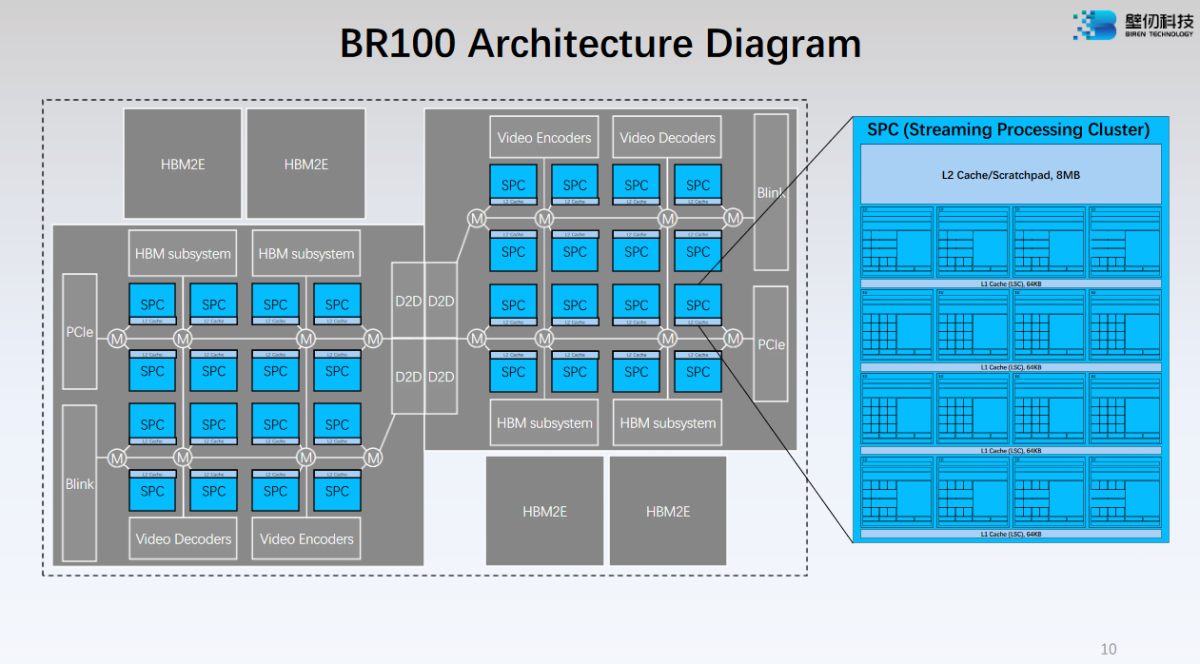 There are eight 32 CDNA 4 compute units per XCD. With eight XCDs that is 256 compute units total. You may note that is fewer than the full MI300X/ MI325X even with the N3P process shrink. AMD said that it added more compute to CDNA 4, so those are beefier compute units.
There are eight 32 CDNA 4 compute units per XCD. With eight XCDs that is 256 compute units total. You may note that is fewer than the full MI300X/ MI325X even with the N3P process shrink. AMD said that it added more compute to CDNA 4, so those are beefier compute units.
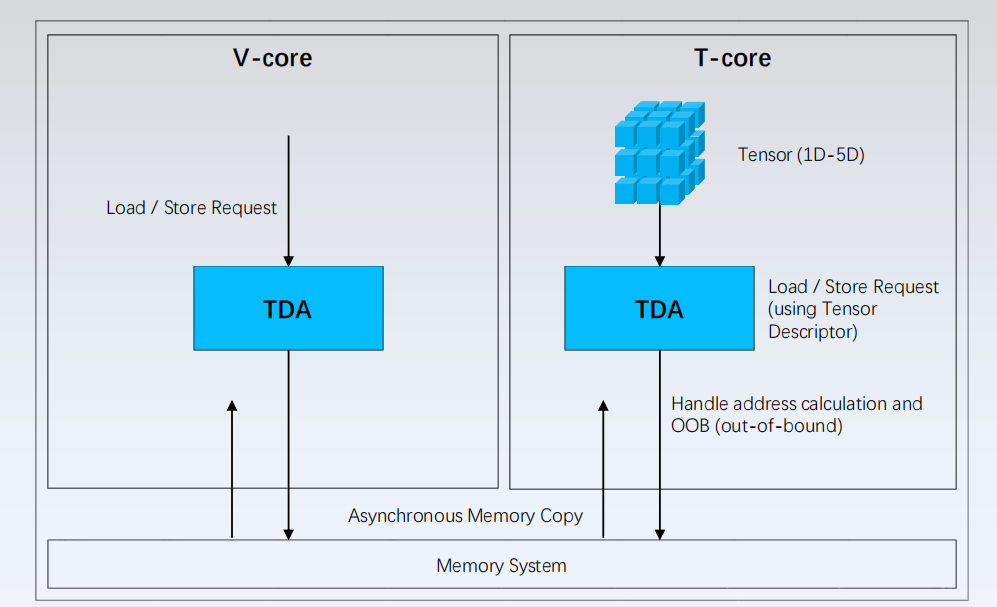 Here is the block diagram including the Infinity Fabric and Infinity Cache. You might notice that on the XCD there are several compute units that are different colors. AMD has additional compute units that it can use to help bin chiplets and increase yield by binning for the best CUs.
Here is the block diagram including the Infinity Fabric and Infinity Cache. You might notice that on the XCD there are several compute units that are different colors. AMD has additional compute units that it can use to help bin chiplets and increase yield by binning for the best CUs.
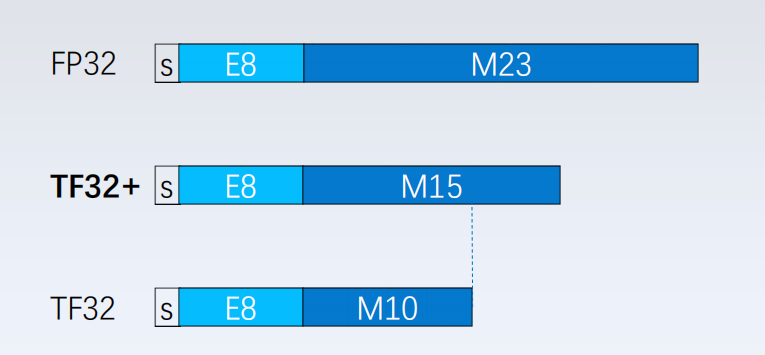 The AMD Instinct MI350 platforms are based on the OAM UBB (Universal Baseboard), the industry’s standard 8-GPU form factor. The AMD Instinct MI350X air-cooled and MI355X liquid-cooled platforms use the UBB form factor but the liquid-cooled version can scale to 1.4kW with liquid cooling.
The AMD Instinct MI350 platforms are based on the OAM UBB (Universal Baseboard), the industry’s standard 8-GPU form factor. The AMD Instinct MI350X air-cooled and MI355X liquid-cooled platforms use the UBB form factor but the liquid-cooled version can scale to 1.4kW with liquid cooling.
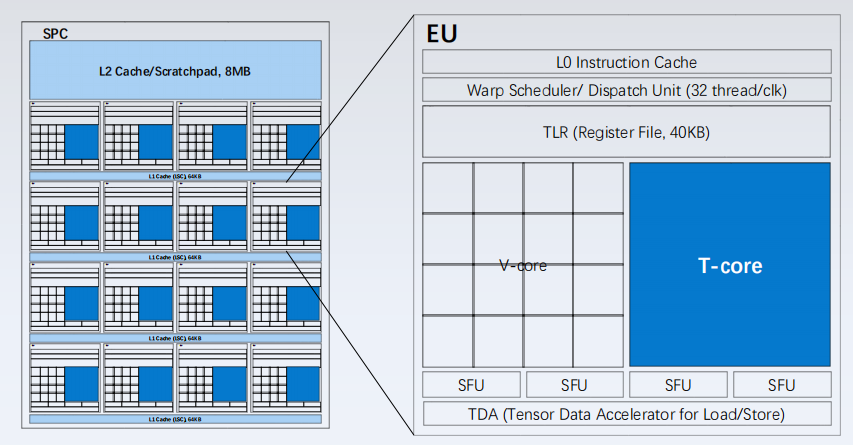 AMD’s vision is to use open standards like UltraEthernet Consortium (UEC) and UALink for scale out and scale up. Some of those are next-generation technologies, but for now, the focus is showing the racks with 64 to 128 GPUs per rack and offering up to 36TB of HBM3E memory in a single rack.
AMD’s vision is to use open standards like UltraEthernet Consortium (UEC) and UALink for scale out and scale up. Some of those are next-generation technologies, but for now, the focus is showing the racks with 64 to 128 GPUs per rack and offering up to 36TB of HBM3E memory in a single rack.
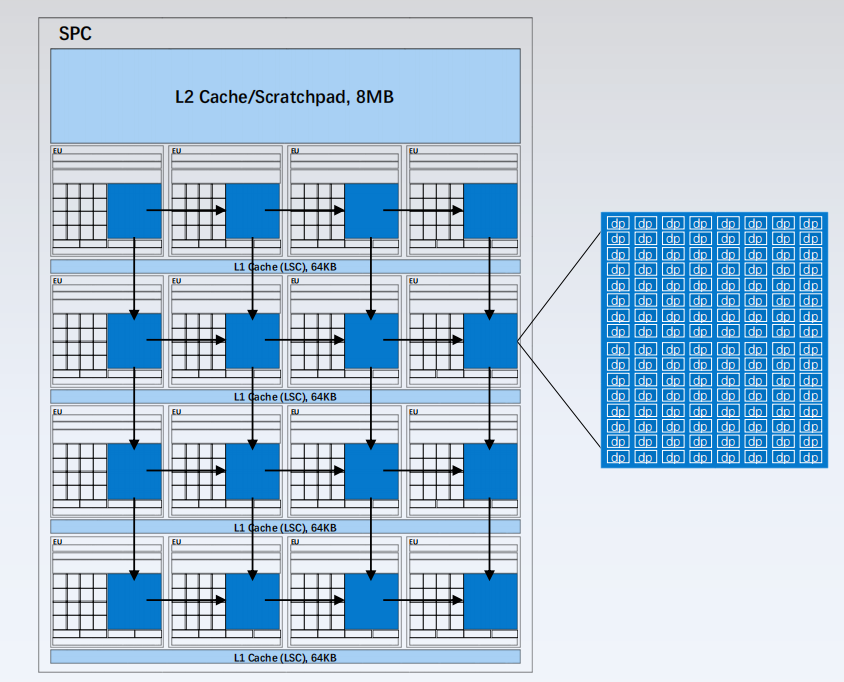 As a result, we get designs for up to 128x liquid cooled MI355X GPUs. That is sixteen UBB 8 GPU trays. Even at 2U each, that is 32U worth of GPUs. Even if you have 1U host nodes, that is 48U of rack space which is significant. Remember, the NVIDIA GB200 NVL72 rack is only 72 GPUs in a rack.
As a result, we get designs for up to 128x liquid cooled MI355X GPUs. That is sixteen UBB 8 GPU trays. Even at 2U each, that is 32U worth of GPUs. Even if you have 1U host nodes, that is 48U of rack space which is significant. Remember, the NVIDIA GB200 NVL72 rack is only 72 GPUs in a rack.
4 Intel Ponte Vecchio
与 Nvidia 的 H100 和 AMD 的 MI210 相比,PVC 没有固定功能的图形硬件,并且缺少显示输出。而H100 和 MI210 仍然具有某种形式的纹理单元。因此,PVC实际上是一个巨大的并行处理器,其编程方式与为计算编程的 GPU 的方式相同。

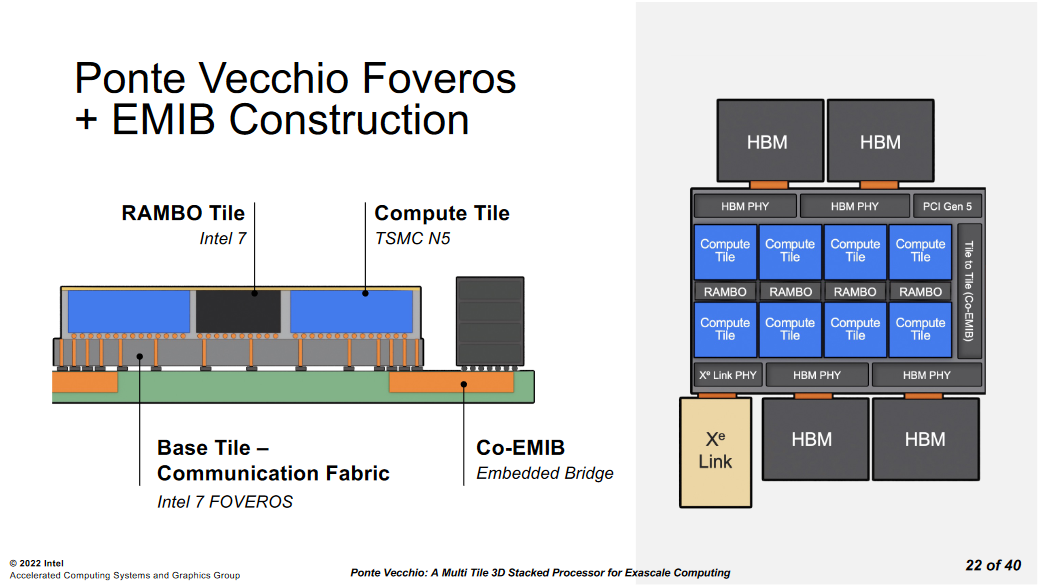 PVC 是一场小芯片盛会。 PVC 的计算芯粒采用台积电 5 纳米工艺制造,基本计算单元称为 Xe 内核(Xe Core)。计算芯粒位于 640 mm^2 基础芯粒的顶部,基础芯粒包括 144 MB L2 缓存并使用英特尔的 7 工艺。然后,基础芯粒充当 IO 芯粒,连接到 HBM2e、PCIe 和其他 GPU。PVC 将五个不同的工艺节点组合在同一个封装中,并使用嵌入式桥接(EMIB)或 3D 堆叠将它们连接起来。英特尔 GPU Max 1100实现了 56 个 Xe 内核,时钟频率高达 1.55 GHz。基本芯粒启用了 108 MB 的 L2 缓存,并连接到 48 GB 的 HBM2e 内存,理论带宽为 1.2 TB/s。Max 1100 是300W TDP 的 PCIe 卡,类似于 AMD 的 MI210 和 Nvidia 的 H100 PCIe。
PVC 是一场小芯片盛会。 PVC 的计算芯粒采用台积电 5 纳米工艺制造,基本计算单元称为 Xe 内核(Xe Core)。计算芯粒位于 640 mm^2 基础芯粒的顶部,基础芯粒包括 144 MB L2 缓存并使用英特尔的 7 工艺。然后,基础芯粒充当 IO 芯粒,连接到 HBM2e、PCIe 和其他 GPU。PVC 将五个不同的工艺节点组合在同一个封装中,并使用嵌入式桥接(EMIB)或 3D 堆叠将它们连接起来。英特尔 GPU Max 1100实现了 56 个 Xe 内核,时钟频率高达 1.55 GHz。基本芯粒启用了 108 MB 的 L2 缓存,并连接到 48 GB 的 HBM2e 内存,理论带宽为 1.2 TB/s。Max 1100 是300W TDP 的 PCIe 卡,类似于 AMD 的 MI210 和 Nvidia 的 H100 PCIe。
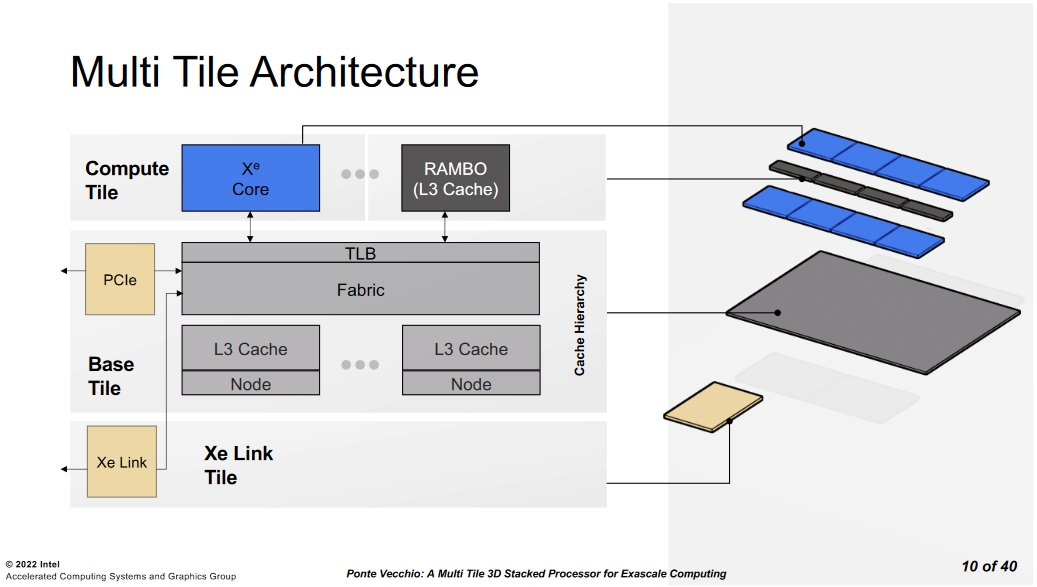 如果 L1未命中,将继续访问基础芯粒上的 L2。Intel 的 L2 缓存(有时称为 L3)非常大,标称容量为 144 MB。Nvidia 的 Ada Lovelace 架构的完整体 AD102 芯片有 96 MB 的 L2 缓存,而 AMD 的 RDNA 2 有高达 128 MB 的 Infinity 缓存。这两种架构都代表了最近的趋势,即消费类 GPU 使用巨型缓存来避免昂贵的 VRAM 。
如果 L1未命中,将继续访问基础芯粒上的 L2。Intel 的 L2 缓存(有时称为 L3)非常大,标称容量为 144 MB。Nvidia 的 Ada Lovelace 架构的完整体 AD102 芯片有 96 MB 的 L2 缓存,而 AMD 的 RDNA 2 有高达 128 MB 的 Infinity 缓存。这两种架构都代表了最近的趋势,即消费类 GPU 使用巨型缓存来避免昂贵的 VRAM 。
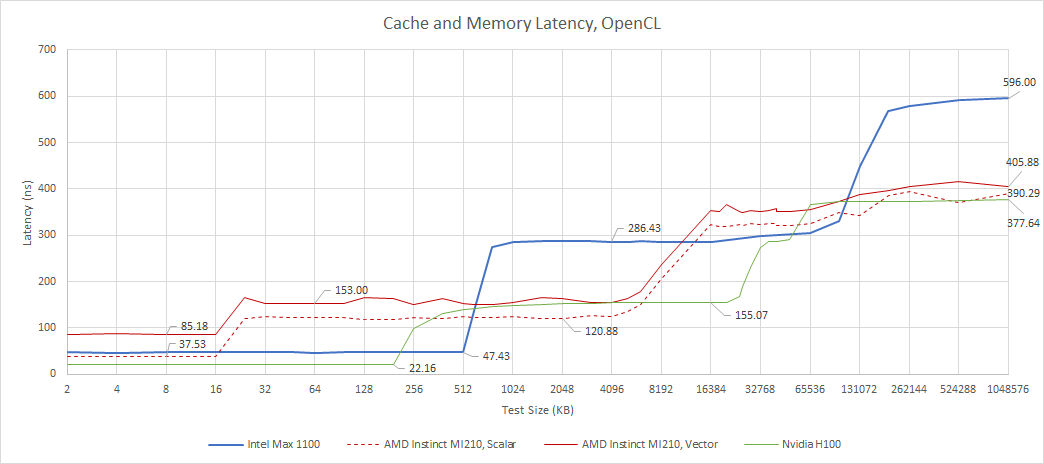
不幸的是,Intel 的 L2 延迟相当高,超过 286 ns。小芯片不是延迟增加的原因,因为 AMD CPU 上的垂直堆叠只会增加几纳秒的额外延迟。一般具有更大缓存的更大 GPU 往往会出现更高的延迟,但 Intel 比 AMD 或 Nvidia 更难解决这个问题。
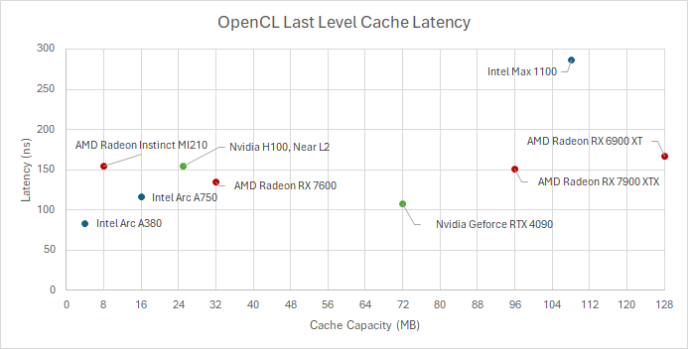
TLB 以及 L2 缓存是在基础芯粒上实现的,因此 L1 缓存实际上是VIVT寻址的,命中 L2 可能会导致地址转换延迟。很多 GPU 都这样做,但如果 TLB 查找速度很慢,会增加缓存延迟。高 L2 延迟可以由更大的L1容量来克服。PVC 的 上512 KB 的 L1 和较早之前的 GPU(如 Nvidia 的 GTX 680 或 AMD 的 Radeon HD 6950)上的 L2 容量一样大,也比 AMD 的 RDNA 2 和 3 架构上的 L1 缓存大。与 AMD 和 Nvidia 相比,Intel 的 L2 缓存的访问量应该要少得多,因为 L1 的未命中率会更低。
除了全局内存外,GPU 还有充当软件管理暂存器的本地内存,英特尔称之为共享本地内存 (SLM)。Nvidia 称为共享内存(Shared Memory),AMD 称之为本地数据共享 (LDS)。
PVC 中的每个 Xe Core 有8个 512 位向量引擎,每个周期可进行 16 个 32 位操作。Nvidia 和 AMD 的设计则使用4个分区。H100 的 SM 有4个 32 位宽的 SMSP,或者32 位操作时为 1024 位宽。MI210 的 CU 有4个 16 宽的 SIMD,也是 1024 位宽的,因为每个通道本身都处理 64 位操作。

PVC 有很多弱点,L2 缓存和 VRAM 延迟太高了,并且FP64 FMA 吞吐量出奇地低。对于PVC,大量的芯片面积却没有带来足够的计算能力,即使和 AMD 的 MI210 相比。不过开发 PVC 时可能获得了不同工艺节点和封装技术的大量经验。
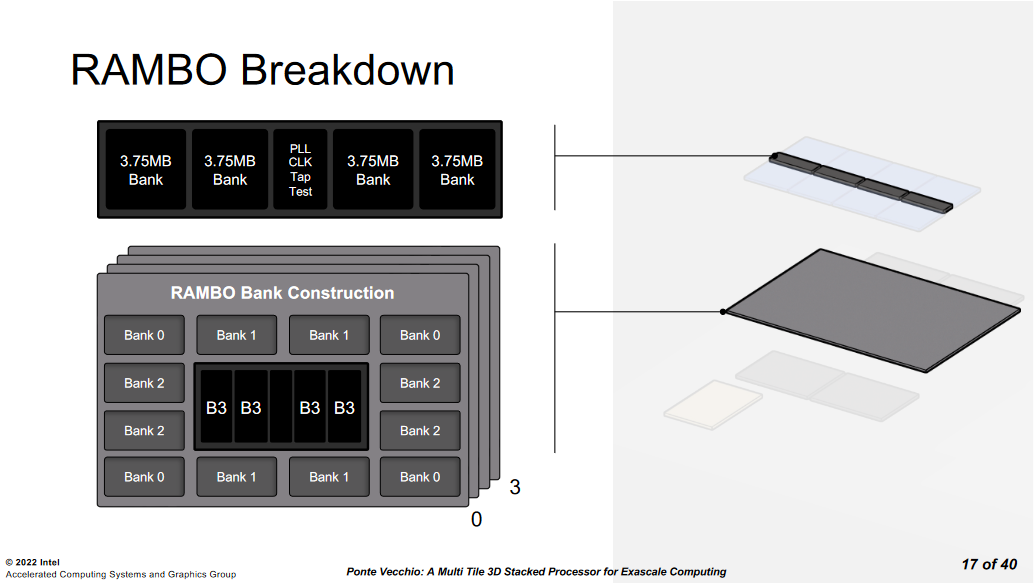
5 BR100
BR100 是由两个芯粒组成的多芯粒 GPU,采用台积电的 7nm 工艺,频率1 GHz,功耗为550W;每个芯粒的面积为 537 mm2,有 385 亿个晶体管,芯片一共有 770 亿个晶体管。每个芯粒有两个 HBM2E ,为 GPU 提供总共四个 HBM2E 堆栈和 64 GB 的 DRAM,1.6TB/s的存储带宽。计算芯粒和 HBM 使用 TSMC 的 CoWoS(Chip on Wafer on Substrate)封装,芯粒间 896 GB/s 的互联带宽。整体结构如下所示:
 GPU 通过PCIe Gen 5 x16连接到主机, 并且支持 CXL。GPU 可以通过8个“BLink”连接,每个提供 64 GB/s 的双向带宽。对于片上网络,BR100 与 Sapphire Rapids (SPR) 等英特尔的服务器 CPU 有很多共同点, 每个处理单元旁边实现一个缓存切片,并且可以将这些缓存切片组合成一个大型的统一缓存。BR100整体架构如下所示:
GPU 通过PCIe Gen 5 x16连接到主机, 并且支持 CXL。GPU 可以通过8个“BLink”连接,每个提供 64 GB/s 的双向带宽。对于片上网络,BR100 与 Sapphire Rapids (SPR) 等英特尔的服务器 CPU 有很多共同点, 每个处理单元旁边实现一个缓存切片,并且可以将这些缓存切片组合成一个大型的统一缓存。BR100整体架构如下所示:
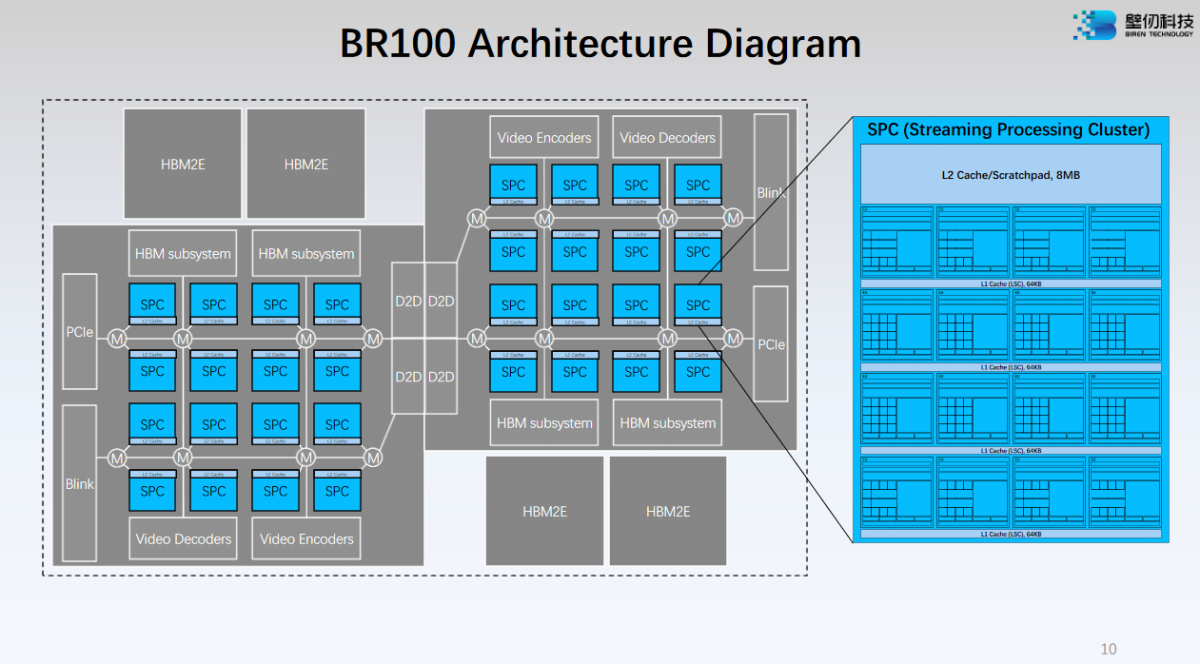 BR100 计算单元由 SPC(Streaming Processing Cluster) 组成,SPC 的 L2 可以配置为私有暂存器(Scratchpad)或私有缓存。BR100 SPC 主要包括:
BR100 计算单元由 SPC(Streaming Processing Cluster) 组成,SPC 的 L2 可以配置为私有暂存器(Scratchpad)或私有缓存。BR100 SPC 主要包括:
- 16 个EU(执行单元),每个 EU 有:
- 16 个流处理核心(V 核)
- 1 个张量引擎(T 核)
- 40KB TLR(线程本地寄存器, Thread Local Register)
- 4 个SFU
- TDA(张量数据加速器, Tensor Data Accelerator)
- 4 个64KB L1 缓存/LSC(加载和存储缓存)
- 高达 8MB 的分布式 L2 缓存
- 保存所有 SPC 的共享数据
- 可以配置为暂存器(Scratchpad)
- 内置归约引擎(Reduction Engine)
TDA 专用于使用张量描述符加速地址计算和 OOB,TDA 通过卸载寻址开销和支持不同的张量布局来提高张量数据获取效率。
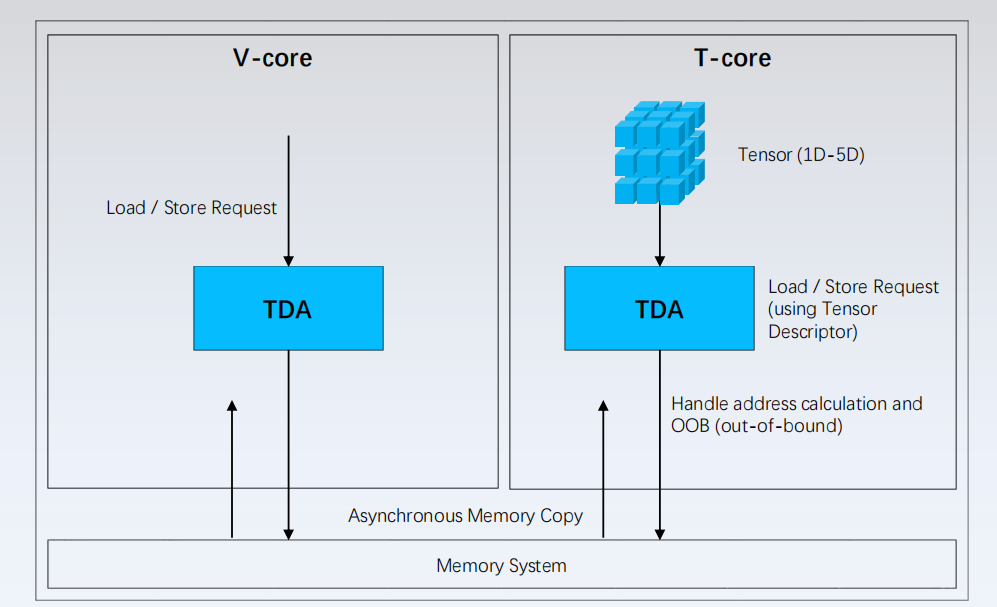
V核支持通用计算的全套 ISA,支持 FP32、FP16、INT32、INT16,包括下列功能单元:
- SFU
- 加载/存储
- 数据预处理
- 管理具有多个同步通道的 T 核
- 处理如 Batch Norm、ReLu 等运算
BR100支持增强的 SIMT 模型
- 128K 个线程在 32 个 SPC 上运行
- 协作Warps (Cooperative Warp)
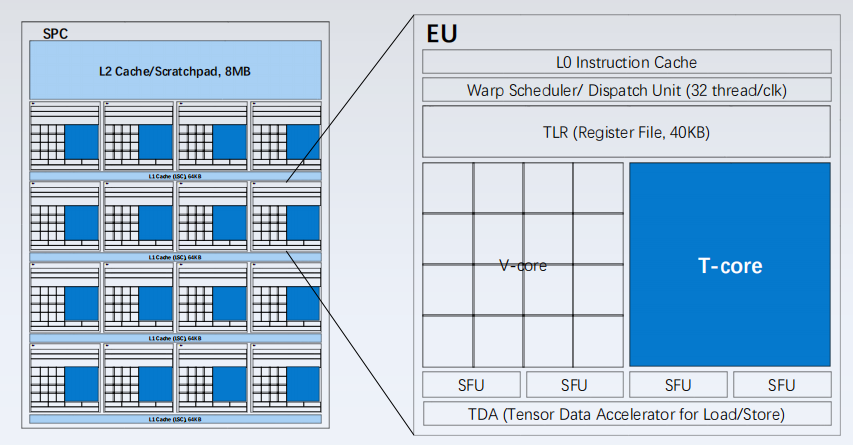 与其他 GPU 相比,BR100 上的向量 FP32 较弱。每个 EU 只有 16 个向量 FP32 通道,只有 16 TFLOPS 的理论 FP32 吞吐量。
与其他 GPU 相比,BR100 上的向量 FP32 较弱。每个 EU 只有 16 个向量 FP32 通道,只有 16 TFLOPS 的理论 FP32 吞吐量。
一个SPC有16 个 T 核,形成2D 脉动阵列;每个 T 核有 2 组 8 x 8 点积 (dp)阵列(BF16 时为 8x 8 x dp8 3D MMA),相当于 64 x 64 矩阵乘法;支持 FP32、TF32、BF16、INT16、INT8、INT4 张量格式。
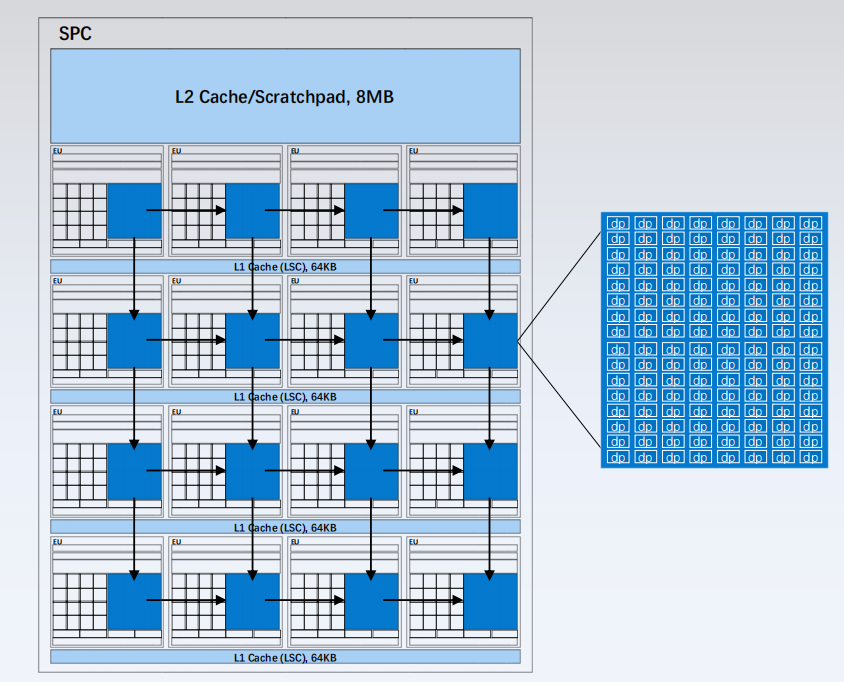
Biren设计了TF32+ 张量数据类型 ,宣称在 AI 训练中比 TF32 精确 32 倍 ,
- E8M15,共 24 位
- 重用 BF16 乘法器(带 1+7 尾数)并简化 T 核设计
- 使用张量加速库时自动启动并声明为 FP32
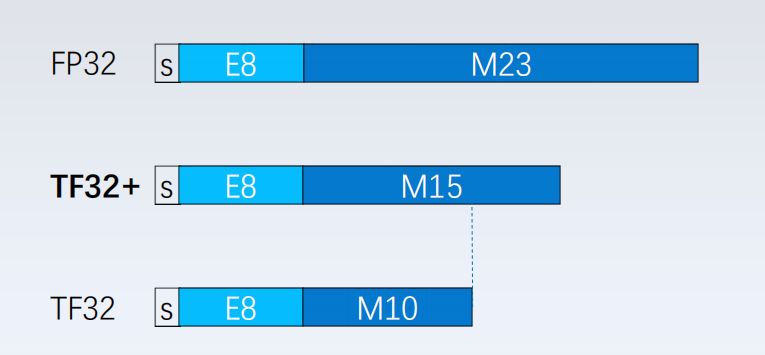
采用8个GPU全互联进行扩展,每个 BR100 GPU 与其他每个 GPU 互联带宽是双向64 GB/s。
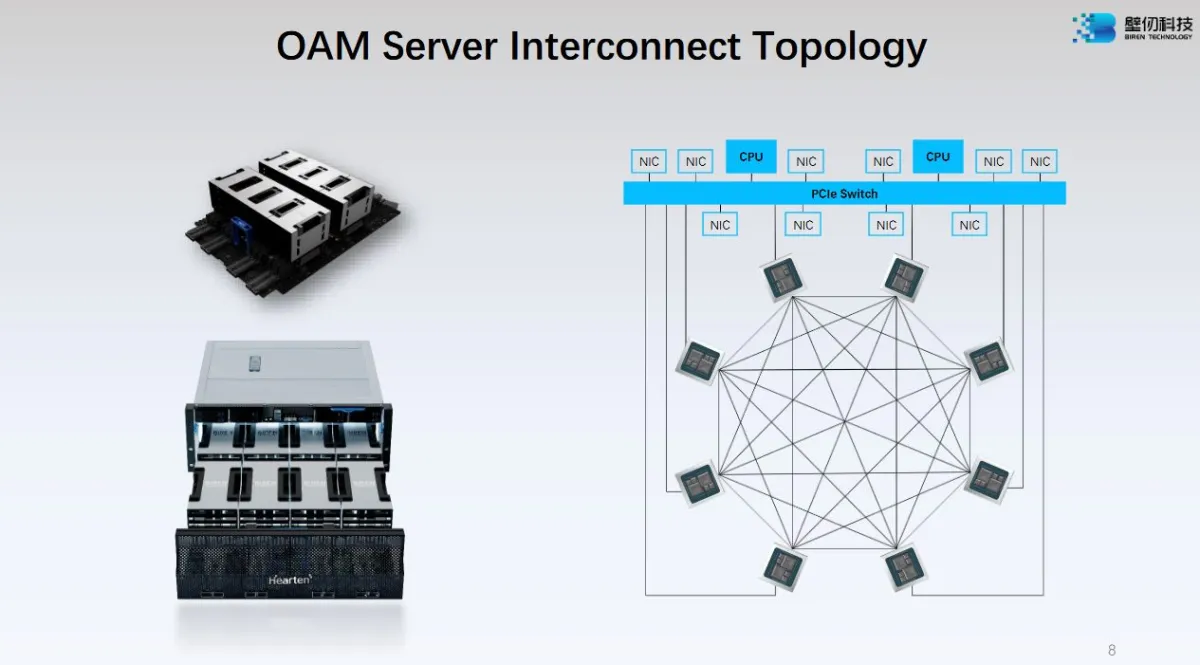 节点外连接由连接到 PCIe 交换机的 NIC 处理。NIC 不直接连接到 GPU,因此网络流量可能由 CPU 端内存提供支持。如此高带宽的 NIC 会给 CPU 端内存带宽带来很大压力。
节点外连接由连接到 PCIe 交换机的 NIC 处理。NIC 不直接连接到 GPU,因此网络流量可能由 CPU 端内存提供支持。如此高带宽的 NIC 会给 CPU 端内存带宽带来很大压力。
Reference
- CUDA Programming Guide Version 1.0
- CUDA C++ Programming Guide, Release 12.3
- McClanahan, C., n.d. History and Evolution of GPU Architecture.
- Lindholm, E., Nickolls, J., Oberman, S., Montrym, J., 2008. NVIDIA Tesla: A Unified Graphics and Computing Architecture. IEEE Micro 28, 39–55. https://doi.org/10.1109/MM.2008.31
- E. Lindholm and S. Oberman, “The NVIDIA GeForce 8800 GPU,” 2007 IEEE Hot Chips 19 Symposium (HCS), Stanford, CA, USA, 2007, pp. 1-17, doi: 10.1109/HOTCHIPS.2007.7482490.
- Montrym, J., Moreton, H., 2005. The GeForce 6800. IEEE Micro 25, 41–51. https://doi.org/10.1109/MM.2005.37
- Kilgard, M.J., Moreton, H., n.d. A User-Programmable Vertex Engine.
- Wittenbrink, C.M., Kilgariff, E., Prabhu, A., 2011. Fermi GF100 GPU Architecture. IEEE Micro 31, 50–59. https://doi.org/10.1109/MM.2011.24
- J. Choquette, O. Giroux and D. Foley, “Volta: Performance and Programmability,” in IEEE Micro, vol. 38, no. 2, pp. 42-52, Mar./Apr. 2018, doi: 10.1109/MM.2018.022071134.
- J. Burgess, “RTX on—The NVIDIA Turing GPU,” in IEEE Micro, vol. 40, no. 2, pp. 36-44, 1 March-April 2020, doi: 10.1109/MM.2020.2971677.
- NVIDIA Turing Architecture In-Depth [WWW Document], 2018. . NVIDIA Technical Blog. URL https://developer.nvidia.com/blog/nvidia-turing-architecture-in-depth/ .
- NVIDIA Ampere Architecture In-Depth [WWW Document], 2020. . NVIDIA Technical Blog. URL https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/ .
- Choquette J. et al., “NVIDIA A100 tensor core GPU: Performance and innovation,” IEEE Micro, vol. 41, no. 2, pp. 29–35, Mar./Apr. 2021, doi: 10.1109/MM.2021.3061394.
- NVIDIA Hopper Architecture In-Depth [WWW Document], 2022. . NVIDIA Technical Blog. URL https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/ .
- NVIDIA H100 Tensor Core GPU Architecture Whitepaper
- A. C. Elster and T. A. Haugdahl, “Nvidia Hopper GPU and Grace CPU Highlights,” in Computing in Science & Engineering, vol. 24, no. 2, pp. 95-100, 1 March-April 2022, doi: 10.1109/MCSE.2022.3163817.
- J. Choquette, “NVIDIA Hopper H100 GPU: Scaling Performance,” in IEEE Micro, vol. 43, no. 3, pp. 9-17, May-June 2023, doi: 10.1109/MM.2023.3256796.
- Jia, Z., Maggioni, M., Smith, J., Scarpazza, D.P., 2019. Dissecting the NVidia Turing T4 GPU via Microbenchmarking.
- Jia, Z., Maggioni, M., Staiger, B., Scarpazza, D.P., 2018. Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking.
- Wong, H., n.d. Demystifying GPU Microarchitecture through Microbenchmarking.
- Abdelkhalik, H., Arafa, Y., Santhi, N., Badawy, A.-H., 2022. Demystifying the Nvidia Ampere Architecture through Microbenchmarking and Instruction-level Analysis.
- Markidis, S., Der Chien, S.W., Laure, E., Peng, I.B., Vetter, J.S., 2018. NVIDIA Tensor Core Programmability, Performance & Precision, in: 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). pp. 522–531. https://doi.org/10.1109/IPDPSW.2018.00091
- Andrews, J., Baker, N., 2006. XBOX 360 SYSTEM ARCHITECTURE. IEEE MICRO.
- Mantor, M., Houston, M., n.d. Low Power High Performance Graphics & Parallel Compute.
- Mark Fowler. ATI Radeon HD5000 Series : In Inside View.
- AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE
- AMD Sea Islands Series Instruction Set Architecture
- AMD Graphics Core Next Architecture, Generation 3 Reference Guide
-
Kanter, D., n.d. The Polaris Architecture . - Radeon’s next-generation Vega architecture
- “AMD Instinct MI100” Instruction Set Architecture: Reference Guide, n.d.
- Introducing AMD CDNA ARCHITECTURE - The All-New AMD GPU Architecture for the Modern Era of HPC & AI
- “AMD Instinct MI200” Instruction Set Architecture: Reference Guide, n.d.
- Introducing AMD CDNA 2 ARCHITECTURE - Propelling humanity’s foremost research with the world’s most powerful HPC and AI accelerator.
- AMD CDNA 3 Architecture - The All-new AMD GPU Architecture for the Modern Era of HPC and AI
- “AMD Instinct MI300” Instruction Set Architecture Reference Guide, n.d.
- M. Hong and L. Xu, “壁仞™ BR100 GPGPU: Accelerating Datacenter Scale AI Computing,” 2022 IEEE Hot Chips 34 Symposium (HCS), Cupertino, CA, USA, 2022, pp. 1-22, doi: 10.1109/HCS55958.2022.9895604.
- W. Gomes et al., “Ponte Vecchio: A Multi-Tile 3D Stacked Processor for Exascale Computing,” 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 42-44, doi: 10.1109/ISSCC42614.2022.9731673.
- D. Blythe, “XeHPC Ponte Vecchio,” 2021 IEEE Hot Chips 33 Symposium (HCS), Palo Alto, CA, USA, 2021, pp. 1-34, doi: 10.1109/HCS52781.2021.9567038.
- H. Jiang, “Intel’s Ponte Vecchio GPU : Architecture, Systems & Software,” 2022 IEEE Hot Chips 34 Symposium (HCS), Cupertino, CA, USA, 2022, pp. 1-29, doi: 10.1109/HCS55958.2022.9895631.
- NVIDIA. Nvidia collective communications library. https://github.com/ NVIDIA/nccl
- Luebke, D., n.d. GPU Architecture: Implications & Trends.
- Hower, D., n.d. GPU Architectures.
- Foster, M., Frasch, I., n.d. GPU Architecture and Function.
- Luebke, D., Humphreys, G., n.d. GPUs have moved away from the traditional fixed-function 3D graphics pipeline toward a flexible general-purpose computational engine.
- Owens, J.D., Houston, M., Luebke, D., Green, S., Stone, J.E., Phillips, J.C., n.d. Graphics Processing Units
- McClanahan, C., n.d. History and Evolution of GPU Architecture.
- Scalable Parallel Programming with CUDA, n.d.
- J. Nickolls, “GPU parallel computing architecture and CUDA programming model,” 2007 IEEE Hot Chips 19 Symposium (HCS), Stanford, CA, USA, 2007, pp. 1-12, doi: 10.1109/HOTCHIPS.2007.7482491.
- Buck, I., n.d. The Evolution of GPUs for General Purpose Computing.
- Nickolls, J., Dally, W.J., 2010. The GPU Computing Era. IEEE Micro 30, 56–69. https://doi.org/10.1109/MM.2010.41
- Gebhart, M., Johnson, D.R., Tarjan, D., Keckler, S.W., Dally, W.J., Lindholm, E., Skadron, K., 2012. A Hierarchical Thread Scheduler and Register File for Energy-Efficient Throughput Processors. ACM Trans. Comput. Syst. 30, 1–38. https://doi.org/10.1145/2166879.2166882
- Fung, W.W.L., Sham, I., Yuan, G., Aamodt, T.M., n.d. Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow.
- Gebhart, M., Johnson, D.R., Tarjan, D., Keckler, S.W., Dally, W.J., Lindholm, E., Skadron, K., n.d. Energy-efficient Mechanisms for Managing Thread Context in Throughput Processors.
- Narasiman, V., Shebanow, M., Lee, C.J., Miftakhutdinov, R., Mutlu, O., Patt, Y.N., 2011. Improving GPU performance via large warps and two-level warp scheduling, in: Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. Presented at the MICRO-44: The 44th Annual IEEE/ACM International Symposium on Microarchitecture, ACM, Porto Alegre Brazil, pp. 308–317. https://doi.org/10.1145/2155620.2155656
- Owens, J.D., Luebke, D., Govindaraju, N., Harris, M., Krüger, J., Lefohn, A.E., Purcell, T.J., 2007. A Survey of General-Purpose Computation on Graphics Hardware. Computer Graphics Forum 26, 80–113. https://doi.org/10.1111/j.1467-8659.2007.01012.x
- Arora, M., n.d. The Architecture and Evolution of CPU-GPU Systems for General Purpose Computing.
- Guz, Z., Bolotin, E., Keidar, I., Kolodny, A., Mendelson, A., Weiser, U.C., 2009. Many-Core vs. Many-Thread Machines: Stay Away From the Valley. IEEE Comput. Arch. Lett. 8, 25–28. https://doi.org/10.1109/L-CA.2009.4
- M. Gebhart, S. W. Keckler, B. Khailany, R. Krashinsky and W. J. Dally, “Unifying Primary Cache, Scratch, and Register File Memories in a Throughput Processor,” 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 2012, pp. 96-106, doi: 10.1109/MICRO.2012.18.