
概述
随着昇腾AI处理器架构的持续演进和不同产品的快速迭代,存在多种不同的架构,例如在最新的下一代架构950在硬件设计上增加了SIMT计算单元,用于提升离散操作场景及复杂分支场景的编程易用性;对华为昇腾AI处理器架构的演进历史进行一次回顾可以帮助了解不同架构的局限和应用需求,因此,本文从Ascend 910里原始DaVinci Core架构开始,最后以950结束,分析不同架构之间的异同。本文所有信息均来自公开渠道,如有错误,还请帮忙指正。
Ascend 910 DaVinci Core
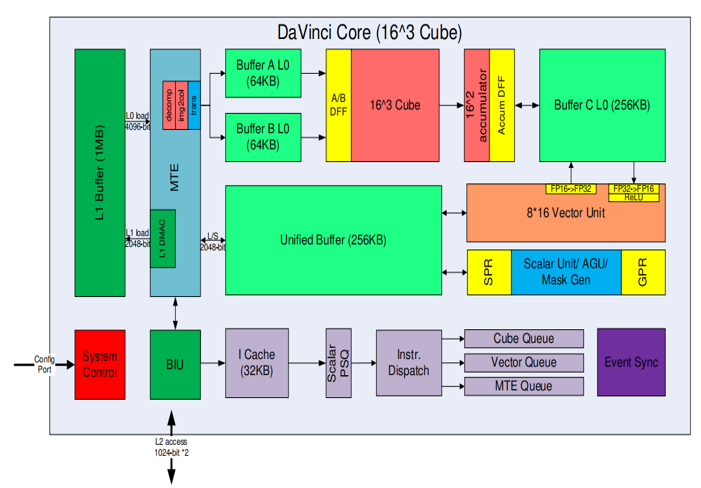
Ascend 910是第一代架构,主要由标量控制单元,向量计算单元和张量积算单元组成:
- 标量计算单元主要负责地址等标量计算
- 向量计算单元可以进行归一化,激活等计算;
- 向量单元还负责数据精度转换,例如 int32、fp16 和 int8 之间的量化和解量化操作;向量单元还可以实现 fp32 操作
- 张量计算单元主要是矩阵计算,包括卷积,全连接,矩阵乘等;张量计算中矩阵的典型尺寸为 16 x 16 x 16。因此,张量计算单元配备了 4096 个乘法器和 4096 个累加器。
DaVinci核包括多个缓冲区,分成不同层次。
- L0 缓冲区专用于张量计算单元,分成三个单独的 L0 缓冲区,分别是缓冲区 A L0、缓冲区 B L0 和缓冲区 C L0。分别用于保存输入特征数据、权重和输出特征数据。
- 缓冲区 A L0 和缓冲区 B L0 中的数据从 L1 缓冲区加载。
- L0 缓冲区和 L1 缓冲区之间的通信由内存传输引擎MTE(Memory Transfer Engine) 管理。
Ascend 910X(200) 计算架构
相比之前的架构,该架构主要变化如下;
- 增加L0C Buffer和Unified Buffer数据通路
- 增加Unified Buffer和Global Memory数据通路
前一代架构广为人诟病的一点就是矩阵计算单元和向量计算单元不能直接共享数据,必须通过L1;这样会导致算子融合性能收益有限,所以在该架构主要针对这个缺陷做了优化。
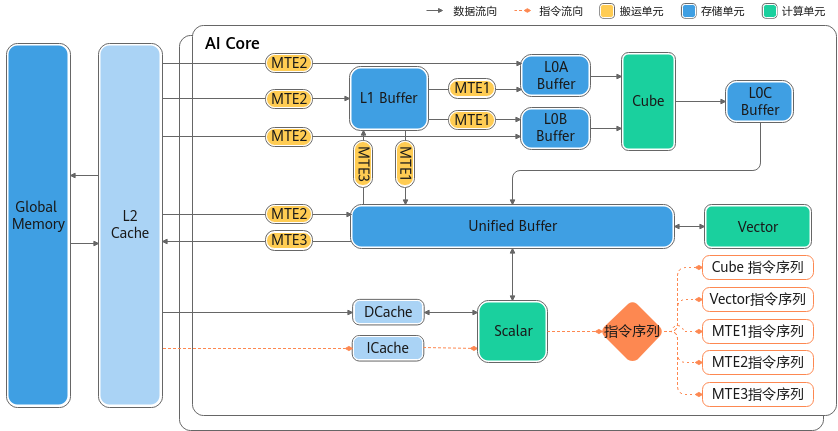 本架构中,Cube计算单元和Vector计算单元同核部署,共享同一个Scalar计算单元。
本架构中,Cube计算单元和Vector计算单元同核部署,共享同一个Scalar计算单元。
- Vector计算单元的数据来源来自于Unified Buffer,要求32字节对齐;
- 数据从L0C Buffer传输至Unified Buffer需要以Vector计算单元作为中转。
- Cube计算单元可以访问的存储单元有L0A Buffer、L0B Buffer、L0C Buffer,其中
- L0A Buffer存储左矩阵,L0B Buffer存储右矩阵,L0C Buffer存储矩阵乘的结果和中间结果。
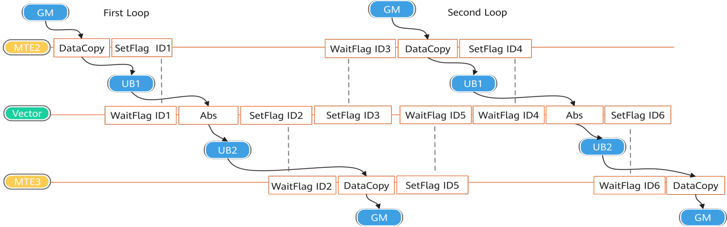
在该架构中支持核内同步,而不支持核间同步(硬件)。由于AI Core内部的执行单元(如MTE2搬运单元、Vector计算单元等)以异步并行的方式运行,在读写Local Memory(如Unified Buffer)时可能存在数据依赖关系。为确保数据一致性及计算正确性,需通过同步控制协调操作时序。对于软件,主要以SetFlag IDx来调用同步机制,数据从GM通过MTE搬运到UB, 之后Vector计算单元才能开始计算,计算完成的结构之后通过MTE搬运到GM,如下所示:
Ascend 910X(220) 计算架构
该架构相比之前的设计,主要修改如下:
- 向量计算单元和矩阵计算单元分离
- 该改动应该主要是为了更灵活的针对不同产品需求配置Vector和Cube的比例
- 增加Fixpipe(硬件加速)
- 增加了FP Buffer和对应的硬件加速器,一方面弥补了Vector的性能,另一方面也可以更好的做一些相关的算子融合
- 增加BT Buffer ( Bias Table Buffer)
- 这个改动和上一个也类似,主要是为了弥补Vector的性能,通过专用的硬件在Cube单元里进行带Bias运算可以极大的减轻Vector的压力
该架构相比原始910设计,对于一些算子会有较大提升,但也继承了缺陷,Vector和Cube计算单元缺少直接通信方式,需要通过GM。
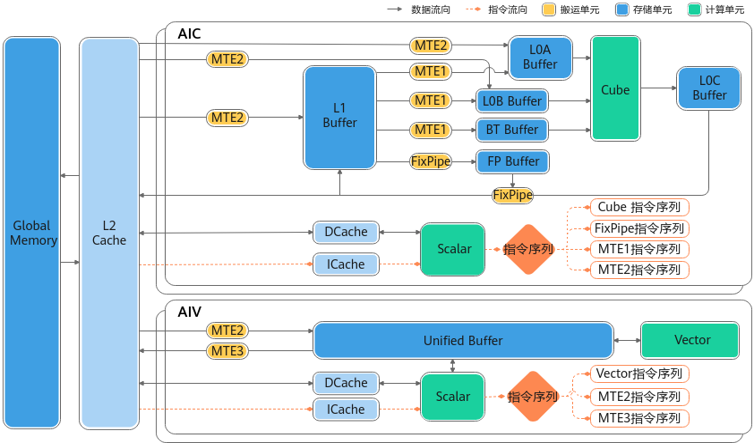
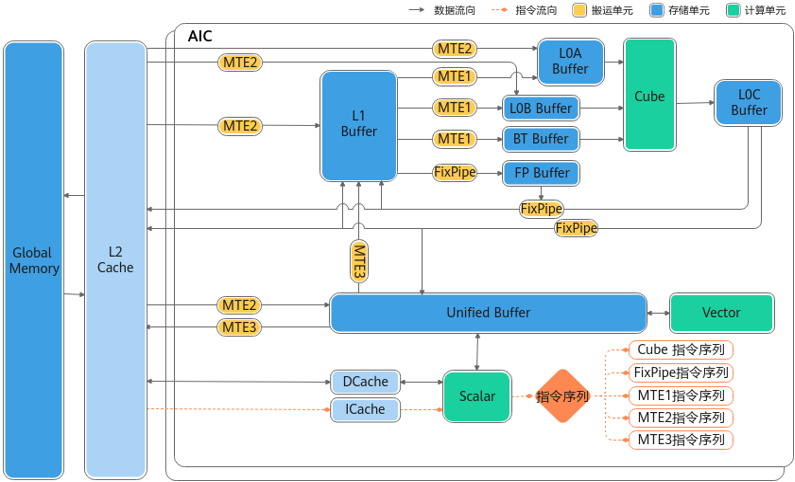
AI Core分为AIC和AIV两个独立的核,分别用于矩阵计算和向量计算。每个核都有自己的Scalar单元,能独立加载自己的代码段。AIV与AIC之间通过Global Memory进行数据传递。
- Vector计算单元 :Vector计算单元的数据来自于Unified Buffer,要求32字节对齐。
- Cube计算单元 :Cube计算单元可以访问的存储单元有L0A Buffer、L0B Buffer、L0C Buffer,其中L0A Buffer存储左矩阵,L0B Buffer存储右矩阵,L0C Buffer存储矩阵乘的结果和中间结果。
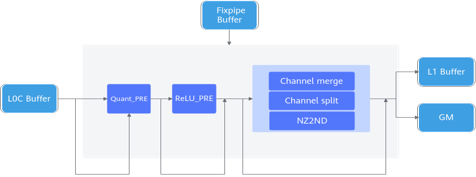
- 支持Fixpipe硬件化加速:Fixpipe是NPU将典型操作进行硬化的加速模块,位于AIC内部,配合Cube计算单元完成随路计算,主要功能如下:
- 量化反量化:包括S322FP16、S322S32、S322S4、S322S8、S322S16、FP322FP16、FP322BF16、FP322S8、FP322S4、FP322FP32。
- Relu功能,包括ReLu、PReLu和Leaky ReLu等典型的激活函数。
- 数据格式转换
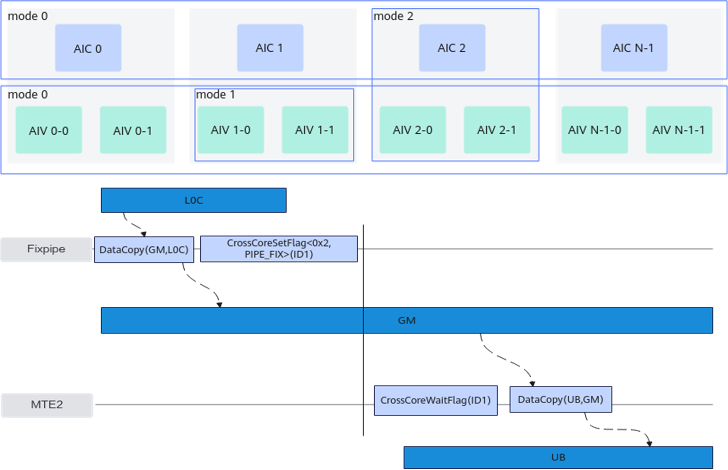
 该架构支持核间同步。当不同核之间操作同一块全局内存时,可能存在读后写、写后读以及写后写等数据依赖问题,需要进行核间同步控制。核间同步控制分为以下几种模式:
该架构支持核间同步。当不同核之间操作同一块全局内存时,可能存在读后写、写后读以及写后写等数据依赖问题,需要进行核间同步控制。核间同步控制分为以下几种模式:
- 模式0:AI Core核间的同步控制。
- 对于AIC场景,同步所有的AIC核,直到所有的AIC核都执行到CrossCoreSetFlag时,CrossCoreWaitFlag后续的指令才会执行;
- 对于AIV场景,同步所有的AIV核,直到所有的AIV核都执行到CrossCoreSetFlag时,CrossCoreWaitFlag后续的指令才会执行。
- 模式1:AI Core内部,AIV核之间的同步控制。如果两个AIV核都运行了CrossCoreSetFlag,CrossCoreWaitFlag后续的指令才会执行。
- 模式2:AI Core内部,AIC与AIV之间的同步控制。在AIC核执行CrossCoreSetFlag之后, 两个AIV上CrossCoreWaitFlag后续的指令才会继续执行;两个AIV都执行CrossCoreSetFlag后,AIC上CrossCoreWaitFlag后续的指令才能执行。
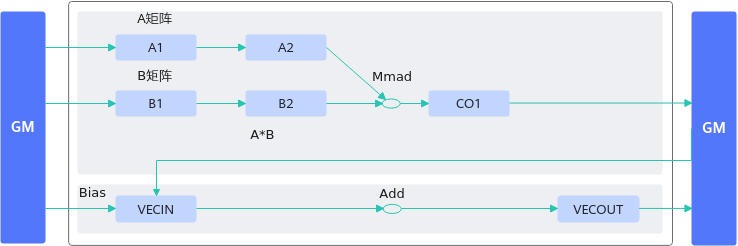
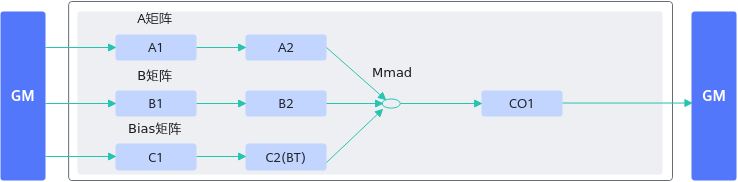
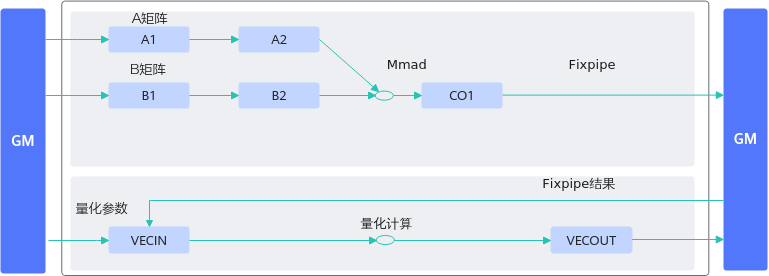
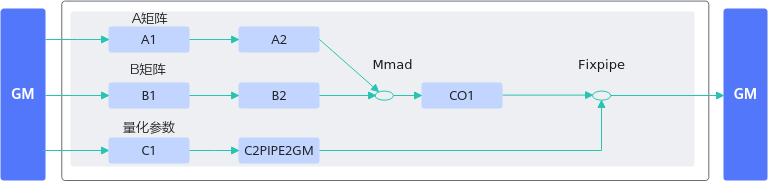
算子中进行带bias的矩阵乘计算时,可将bias数据搬运至C2(Bias Table Buffer)上,调用一次Mmad接口实现矩阵乘加bias的计算,或者直接调用Matmul高阶API完成功能。相比于先将矩阵乘的结果从CO1(L0C)搬运到GM上,再搬运到UB上进行加bias的过程,减少了数据搬运的次数,可提升内存使用效率。下图分别是不带BT Buffer和带BT Buffer运算的差别:
算子实现中对矩阵乘结果进行量化计算时,可将量化参数搬运到C2PIPE2GM(Fixpipe Buffer)上,调用一次Fixpipe接口实现矩阵乘结果的量化计算。相比于将矩阵乘的结果从CO1(L0C)搬运到GM,再从GM搬运到UB,在UB进行量化计算的过程,数据搬运的次数更少,内存使用效率更高。下图分别是不带FP Buffer和带FP Buffer运算的差别:
Ascend 910X(300) 计算架构 - 偏端侧
该架构应该是偏端侧应用,所以Cube和Vector计算单元还是延续早期设计,在前端耦合; 同时引入之前的BT Buffer和FP Buffer来加速,降低Vector的需求。Cube计算单元和Vector计算单元同核部署,共享同一个Scalar计算单元。
- Vector计算单元:数据来源来自于Unified Buffer,要求32字节对齐。
- Cube计算单元:可以访问的存储单元有L0A Buffer、L0B Buffer、L0C Buffer,其中L0A Buffer存储左矩阵,L0B Buffer存储右矩阵,L0C Buffer存储矩阵乘的结果和中间结果。
该硬件架构不支持核间同步。
Ascend 950 计算架构
最新的架构则是Ascend 950,分为950PR(Prefill & Recommendation) 和950DT(Decode & Training)。在上一代基础上增加了SIMT模式的支持;同时结合了之前几代架构的修改,将Cube和Vector解耦,但同时增加了之间通信的数据通路。一个AI Core包含AIV和AIC的组合。 对于AIV:
- 可支持两种工作模式:SIMT和SIMD,以VF(Vector Fuction) 为粒度进行切换;
- 同一时刻不能同时支持SIMD和SIMT;
- SIMT可以支持
- 支持直接读写GM或UB (UB当做Shared Memory)
- 一个SIMT Vector Function 运行一个 thread block,同一时刻一个AIV只能执行一个SIMT Vector Function
- 每个AIV有4个Warp Scheduler, scheduler id = warp id % 4
- 每个线程可使用的寄存器受线程个数限制
- 最大支持128KB Data Cache,Data Cache直接复用UB作为Cacheline
- SIMD优化包括:
- 从A2/A3Memorybased架构切换到Regbased架构,增加SIMD Register File存储层次,可以直接对芯片的Vector寄存器Register进行操作,实现更大的灵活性和更好的性能。
- 数据从Unified Buffer搬运到Register进行计算,产生的中间结果可以不用传回Unified Buffer,直接在寄存器计算;
对于AIC:
- 新增MX FP4/MX FP8类型;
- 增强单核算力,增大核数;
-
不再支持s4类型;不支持4:2稀疏矩阵;
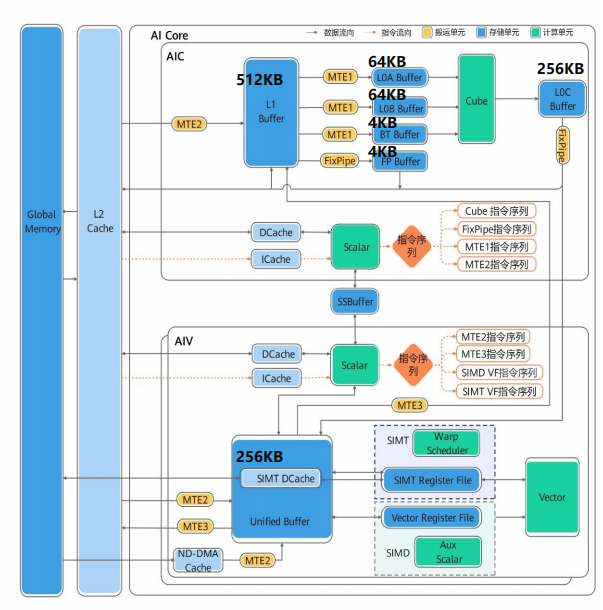 除了SIMT功能的增加,额外的优化包括新的数据通路:
除了SIMT功能的增加,额外的优化包括新的数据通路: - 增加L0C Buffer -> Unified Buffer、Unified Buffer <-> L1 Buffer的数据通路;
- 删除Global Memory -> L0A Buffer、Global Memory -> L0B Buffer的数据通路。删除L1 Buffer->Global Memory的数据通路;
- MTE2 数据搬运能力增强:新增NDDMA搬运、新增Compact模式、增强搬运维度;
- SSBuffer,用于AIC和AIV的核间通信;
对于SIMT API,基本可以做到和业界SIMT编程接口一一对应,如下所示:

两者实现相同Reduce算子的代码,不能说一模一样,基本上也没太多差别。

吸取之前架构的优点,AIV 和 AIC 支持独立运行机制。AIC和AIV独立运行机制,又称双主模式。在分离架构下,区别于MIX模式(包含矩阵计算和矢量计算)通过消息机制驱动AIC运行,双主模式为AIC和AIV独立运行代码,不依赖消息驱动,使能双主模式能够提高Matmul计算性能。默认情况下,双主模式不使能,需要通过MatmulConfig中的enableMixDualMaster参数开启。