
概述
当前大模型发展如火如荼,在Scaling Law的加持下模型的参数越来越大,最新的deepseek V4参数量高达1.6万亿。可是,单卡的存储容量还在200GB左右,显然,这么大的模型不可能在单卡上存放,必然会催生多卡分布式的训练和推理的需求。目前业界对多卡互联的讨论也是异常激烈,主要是分成这么几种技术流派:
-
自研派:以NVIDIA、华为等具备雄厚实力和明确需求的公司为代表,采用自研的互联协议与设备。例如NVIDIA的NVLink/NVSwitch,以及华为的UB(Universal Bus)。这种方案的优点在于可以自主定义链路层与传输层协议,从物理层到软件栈进行垂直优化,从而最大程度优化有效带宽、降低链路延迟,并实现灵活的拓扑结构(如NVL72的扁平化全交换结构),但生态封闭、成本高昂。
-
联盟派:以AMD、Intel、博通、思科、微软、Meta等厂商为代表,他们联合制定了UALINK、UEC、GLink等互联协议,试图通过产业联盟的方式打破垄断,构建开放生态。其技术路线通常基于成熟的以太网物理层(SerDes)进行增强,在链路层和传输层进行定制,以在性能和开放性之间寻求平衡。
-
通用派:即大量既无能力参与标准制定,也无力自研协议与设备的中小型厂商或追求极致TCO(总拥有成本)的用户。他们基本采用标准的以太网(Ethernet,特别是RDMA over Converged Ethernet, RoCE)或InfiniBand互联方案,以充分利用现有庞大、成熟的网络设备生态和运维经验。此外,也有部分厂商探索采用PCIe Switch或CXL技术,主要用于内存池化和紧耦合系统内部连接,但如结论所述,在AI计算互联领域存在局限性。
本文将从上述第三类厂商的视角出发,探讨AI时代真正需要什么样的互联技术。下文将首先回顾CPU时代的互联技术,进而阐述AI时代对互联提出的新要求。
结论
按照惯例,我们先给出核心结论。
-
AI的多卡互联需要硬件一致性支持吗?
不需要 AI计算与CPU计算的关键区别在于,前者主要涉及大量数据的显式、一次性搬运(如All-Reduce、All-Gather等集合通信操作),通信模式相对规整且由软件框架(如PyTorch, TensorFlow)明确调度。因此,无需额外增加硬件复杂度来支持缓存一致性(Cache Coherence)。只要通过软件屏障(Barrier)、集合通信库(如NCCL)做好数据搬运过程中的同步即可。因此,类似CXL这种以内存一致性为核心、旨在构建统一内存视图的技术,在多卡AI训练推理互联领域前景有限,但其在内存扩展、池化方面对AI推理或内存密集型场景或有价值。
-
AI的多卡互联可以采用Mesh/Torus这类无需交换机的拓扑来降低成本吗?
不能 在MoE(混合专家)模型尚未流行时,Mesh/Torus这类无中心交换机的拓扑或许在特定规整通信模式(如卷积神经网络中相邻层的通信)下还有其市场。但在MoE成为主流的今天,其动态、稀疏、All-to-All的通信模式对网络拓扑的任意两点间通信性能提出了极高要求。Mesh/Torus的网络直径(任意两节点间最大跳数)较长,且跨节点通信(如对角线上芯片间的通信)会引发严重的性能不稳定,这都是不可接受的。更遑论其在系统布线复杂性、故障诊断和可靠性方面的挑战。事实上,Google的TPU采用的2D/3D Torus架构在面临MoE等模型时已显露出不足,最新的TPU v8i已转向非torus拓扑。
-
AI的多卡互联更倾向于平坦网络拓扑还是分层互联拓扑?
必然是平坦的网络拓扑 各种分层网络拓扑天然要求在多卡通信时,必须根据互联拓扑和能力在软件层面(模型并行、流水线并行策略)进行精细的数据切分和任务映射,这给程序员带来了额外的复杂性,且难以实现最优性能。最理想的方案是一个平坦的互联拓扑(例如NVIDIA的NVL72,通过多层NVSwitch使所有72个GPU处于一个交换网内),使得所有卡都能以近似相同的高带宽、低延迟相互通信。这样,开发者就无需为不同的互联层级而额外考虑复杂的数据切分与通信策略,可以更专注于算法本身。
-
互联协议(如UALINK、UEC、GLink)中,谁将最终胜出?
目前,全球最大的互联网络——因特网——是基于以太网构建的,市场上也因此存在大量成熟、廉价、可大规模部署的以太网交换设备。而UALINK、UEC、GLink等新兴协议,本质都是基于以太网物理层(112G SerDes及以上)进行的链路层/传输层增强,旨在在性能上对标甚至超越NVLink,在开放性上优于私有协议。然而,这些新协议目前尚缺乏大规模商用的交换设备芯片和生态系统,而AI对互联的需求又极为迫切。参考CPU和HPC(高性能计算)领域的发展路径(从专有总线到开放标准),未来主流很可能仍将是以太网的某种增强版本(可能是上述联盟标准之一,也可能是标准以太网自身的演进),但会形成一个多层次市场:高端封闭系统用私有协议,主流开放集群用增强以太网,成本敏感场景用标准以太网。
-
常说的Load/Store语义与RDMA语义有何区别?谁会胜出?
主要区别在于:Load/Store语义(或称“内存语义”)可以更轻松地通过CPU/GPU的访存指令(如LD/ST)直接发起对远端内存的读写,对程序员更友好,类似于访问本地内存。而RDMA属于消息语义,需要预先在通信两端构建发送/接收队列(SQ/RQ/CQ),并通过“工作请求(WR)”的方式异步触发数据传输。两者的核心区别并非是否使用DMA,因为Load/Store操作同样可由DMA引擎完成。区别在于编程模型和适用场景。在紧耦合的互联系统(如同一节点内的多卡,通过NVLink或CXL互联)中,倾向于使用Load/Store语义,以实现极低延迟和简化的编程。在松耦合的互联系统(如跨节点、跨机柜,通过以太网/InfiniBand互联)中,则更倾向于使用RDMA消息语义,因其更适应网络传输的不可靠、带内缓冲等特性。两者将长期共存,分别适用于不同层级的互联。
CPU时代的互联
实际上,多卡互联并非AI时代的新生事物,其历史可以追溯到更早。当前AI时代的互联需求(高带宽、低延迟、可扩展),在早期单芯片CPU性能不足、需要构建大规模SMP(对称多处理器)服务器时同样存在,特别是HPC和超算领域。如今,我们不过是将CPU领域的历史在GPU/AI芯片上以更大的规模和更高的要求重演一遍。下面简要回顾早期SUN和IBM小型机中的互联技术,它们展现了构建大规模紧耦合系统的不同设计哲学;以及超算里互联的一些发展趋势。
SUN的小型机互联
在2012年,SUN推出的M5 CPU有7个CL(Coherence Link)和6个SL(Scalability Link), 每个CL有12个lane,每个lane 12Gbps, 因此每个CL的带宽是144Gbps; 每个SL有4个lane,每个lane也是12Gbps, 因此每个SL的带宽是47Gbps。M5可以通过交换芯片Bixby组成32路SMP系统。
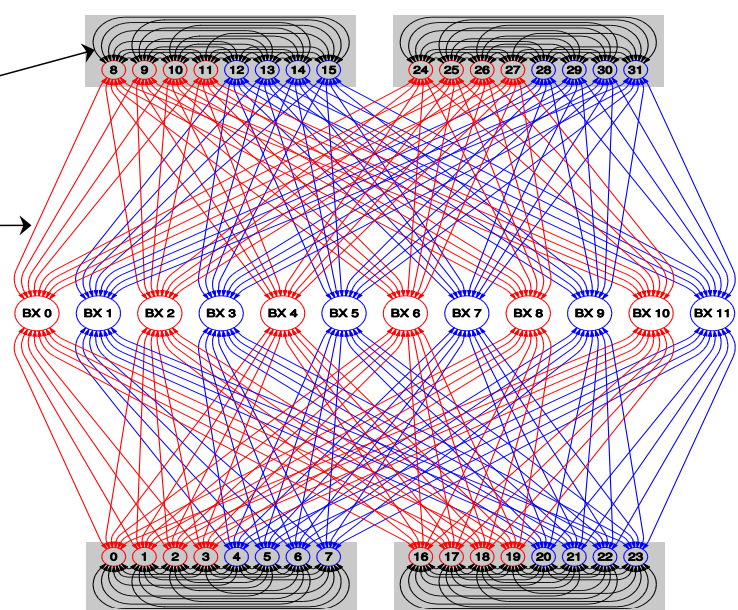 每个Bixby有16个端口,每个端口是4x16Gbps的互联能力
每个Bixby有16个端口,每个端口是4x16Gbps的互联能力
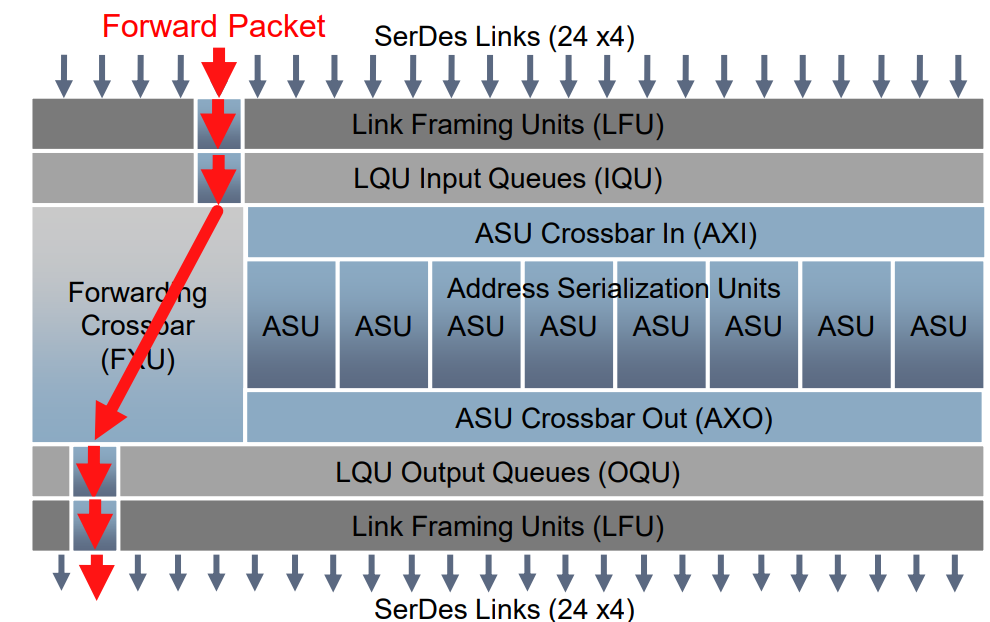
这是2012年,这个和现在NVIDIA采用的NVLINK+NVSWITCH形式上是比较像的,有自己的互联协议和互联设备。
到2013年,SPARC M6可以通过互联扩展成更大的系统。 下面通过交换机可以组成48,64或96路SMP系统。

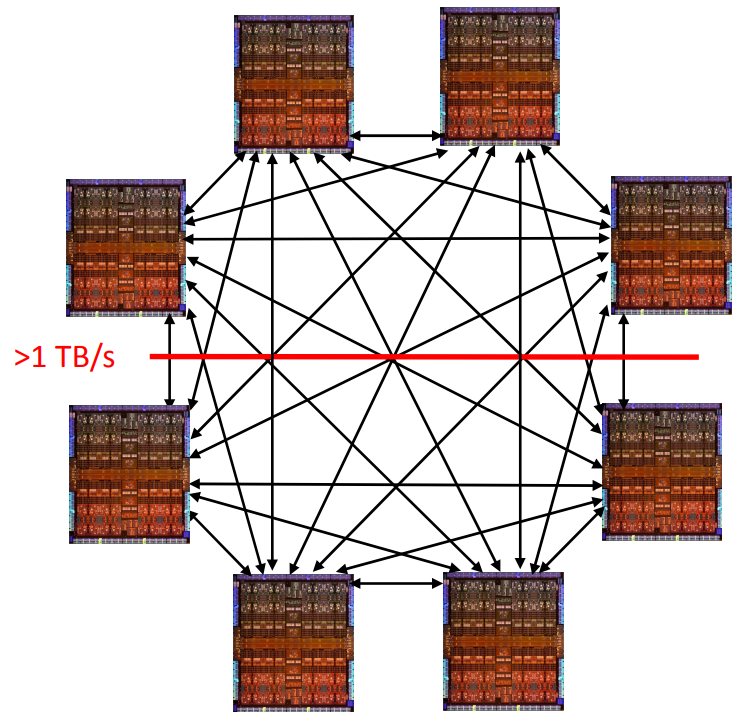
2017年的M7 继续扩展SMP系统,可以是现在比较流行的8卡full mesh, 有超过1TB/s的双分带宽。
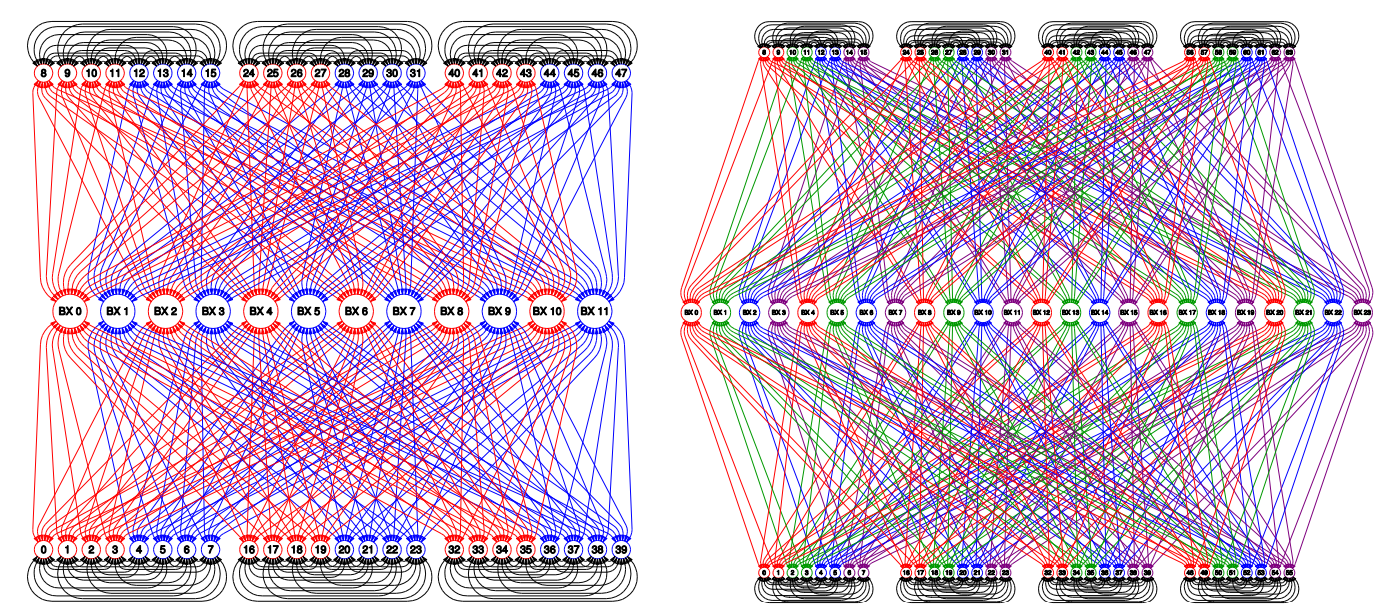
 或者通过64口的交换机组成32路的SMP系统,可以提供64TB的存储
或者通过64口的交换机组成32路的SMP系统,可以提供64TB的存储
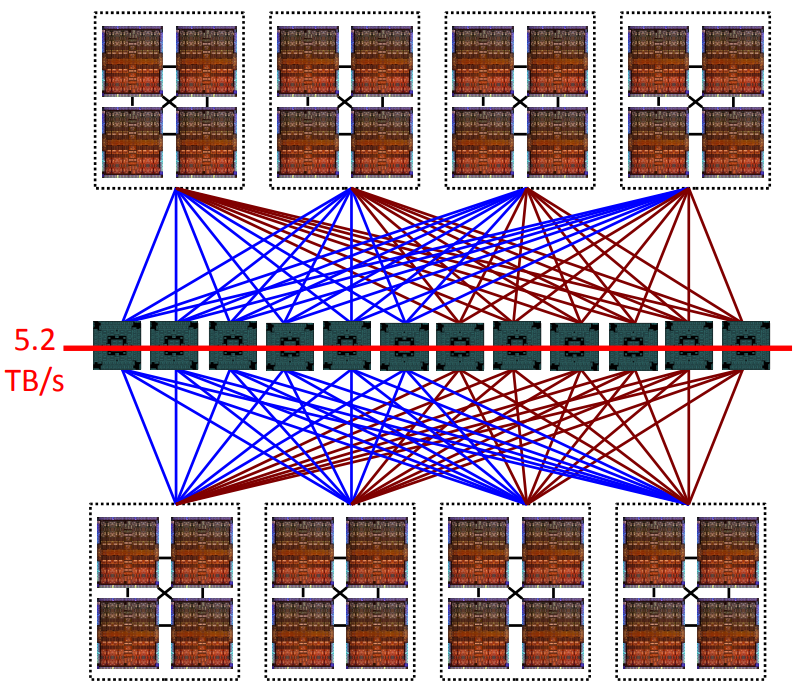
IBM的小型机
PoOWER 5是2004年推出的产品,可以通过fabric bus controller (FBC) 控制片间的通信,互联拓扑称为分布式交换,在不同配置下保持一样的行为。高端POWER5系统采用MCM封装,基本单元是8个POWER5 芯片和8个L3芯片封装成两个MCM。MCMs, 内存, 和连接I/O drawers的桥接芯片组成一个book。下图展示了16路POWER5系统: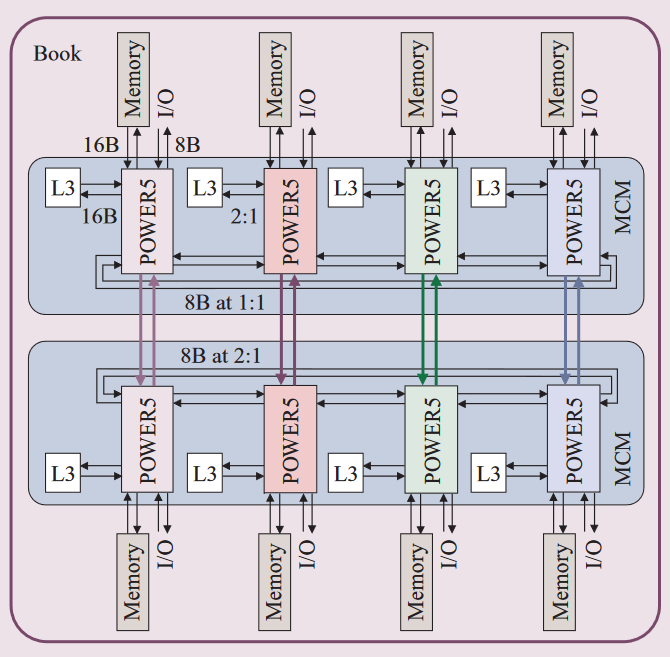
POWER5 在MCM内部是通过两个环状总线互联,两个环方向相反。每个总线是8B位宽,运行在处理器频率。一个Book内两个MCM通过4对8B位宽,运行在1/2处理器频率的单向总线互联。一个POWER5 book是16路SMP,对于SMT2,就是32路SMP。4个books可以互联组成64路SMP系统。每个Book中的POWER5芯片和边上芯片通过运行在1/2处理器频率的8B位宽总线互联。下图展示了64路SMP互联示意图: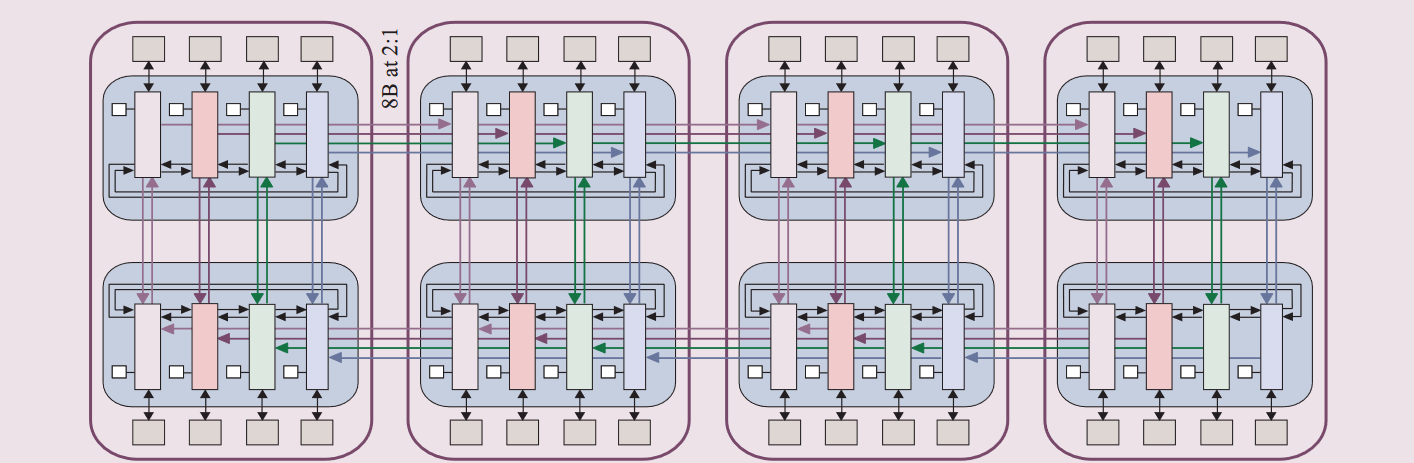
而到了2007年的POWER 6,互联就和当前流行的全连接很很像了。4个POWER6芯片组成一个基本互联单元Node,每个POWER6有5个运行在1/2处理器频率的8B位宽的SMP接口,三个专门用于Node内部互联。如下图所示: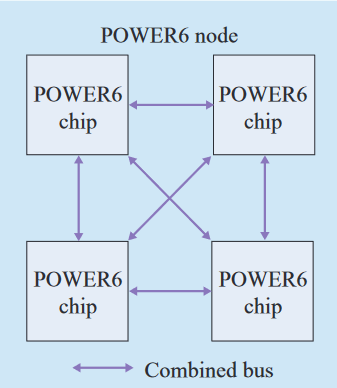 依赖于一致性协议上的创新,一致性总线和数据时分复用同一个物理链路,可以67%带宽分配给数据,33%分配给一致性,或者50%分配给数据,50%分配给一致性。 在一个Node内,4个POWER6组成全连接网络。
依赖于一致性协议上的创新,一致性总线和数据时分复用同一个物理链路,可以67%带宽分配给数据,33%分配给一致性,或者50%分配给数据,50%分配给一致性。 在一个Node内,4个POWER6组成全连接网络。
不同于之前的环拓扑,POWER6可以使用8个Node组成32路SMP的全连接拓扑,如下图所示: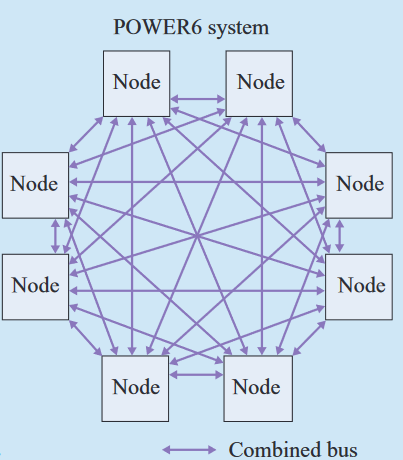
到了2017年,POWER 9继续保持了全连接的基本单元。下图展示了基于POWER9的Power E980系统逻辑架构示意图: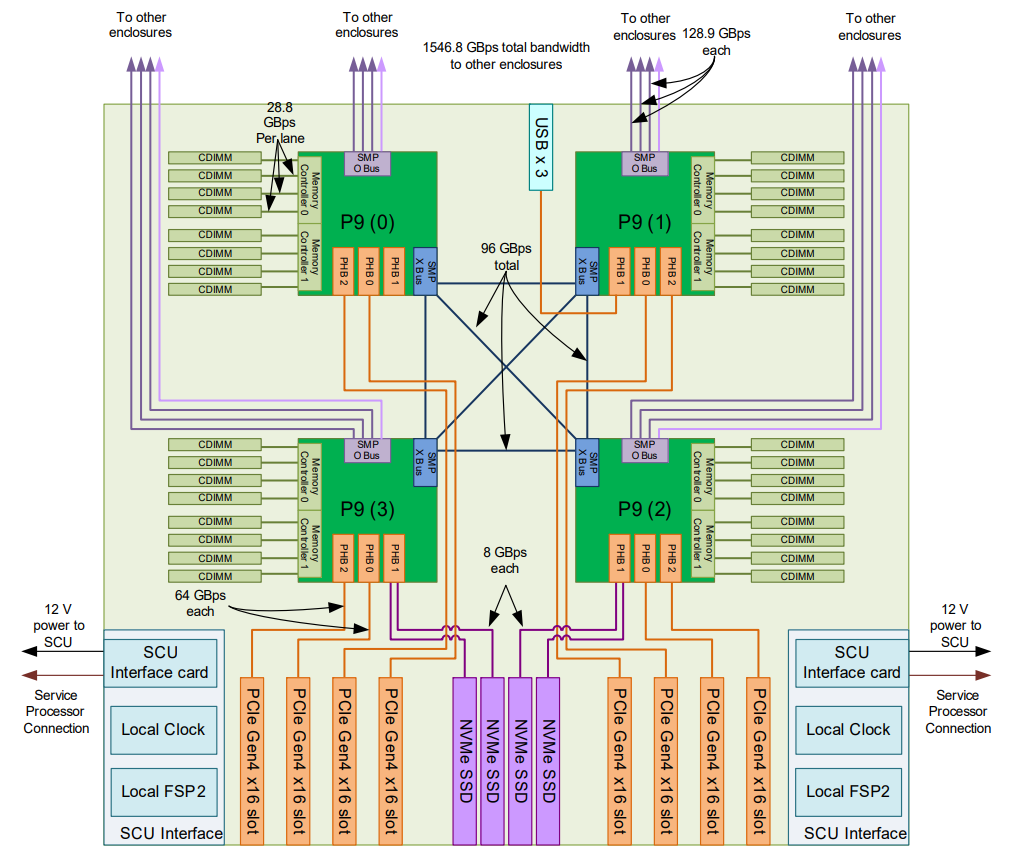 4个POWER 9组成全互联的SMP系统。而不同数量的Node则可以继续互联组成不同规模的Drawer。下图分别展示了由2-, 3-, 和4-drawer组成的SMP系统的示意图:
4个POWER 9组成全互联的SMP系统。而不同数量的Node则可以继续互联组成不同规模的Drawer。下图分别展示了由2-, 3-, 和4-drawer组成的SMP系统的示意图: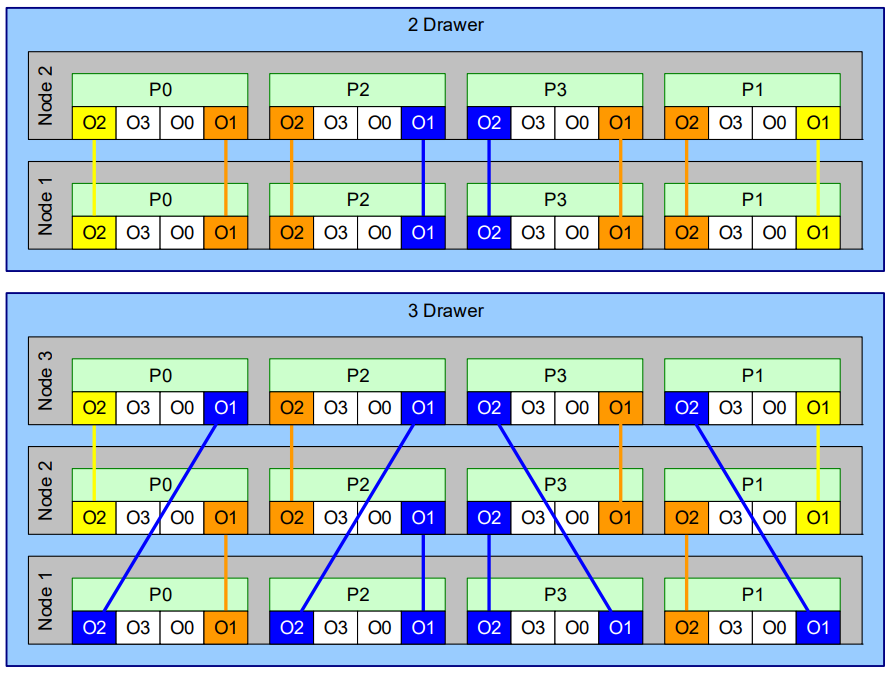
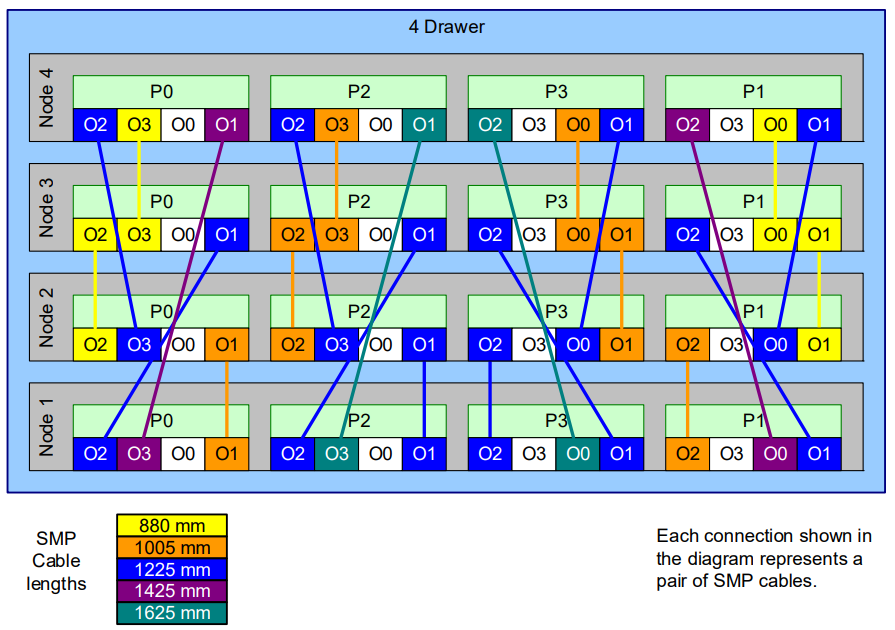
HPC和超算的互联
根据A Survey of High-Performance Interconnection Networks in High-Performance Computer Systems里的统计调研,从Top100到Top500的超算系统中,包括Infiniband,Omnipath, Cray等各种专有互联的比例是在逐渐降低,而Ethernet则是比例稳步提高的。
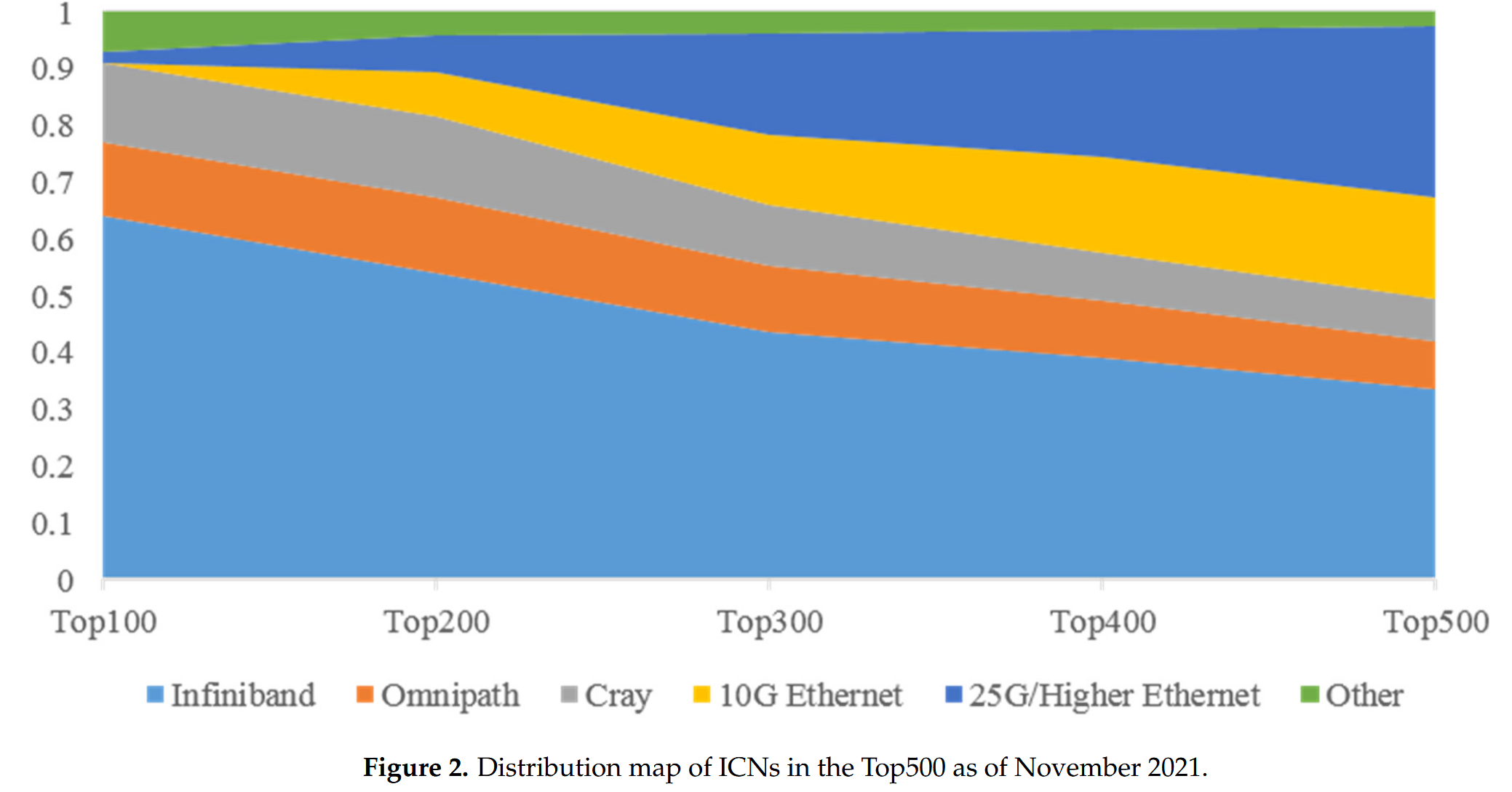
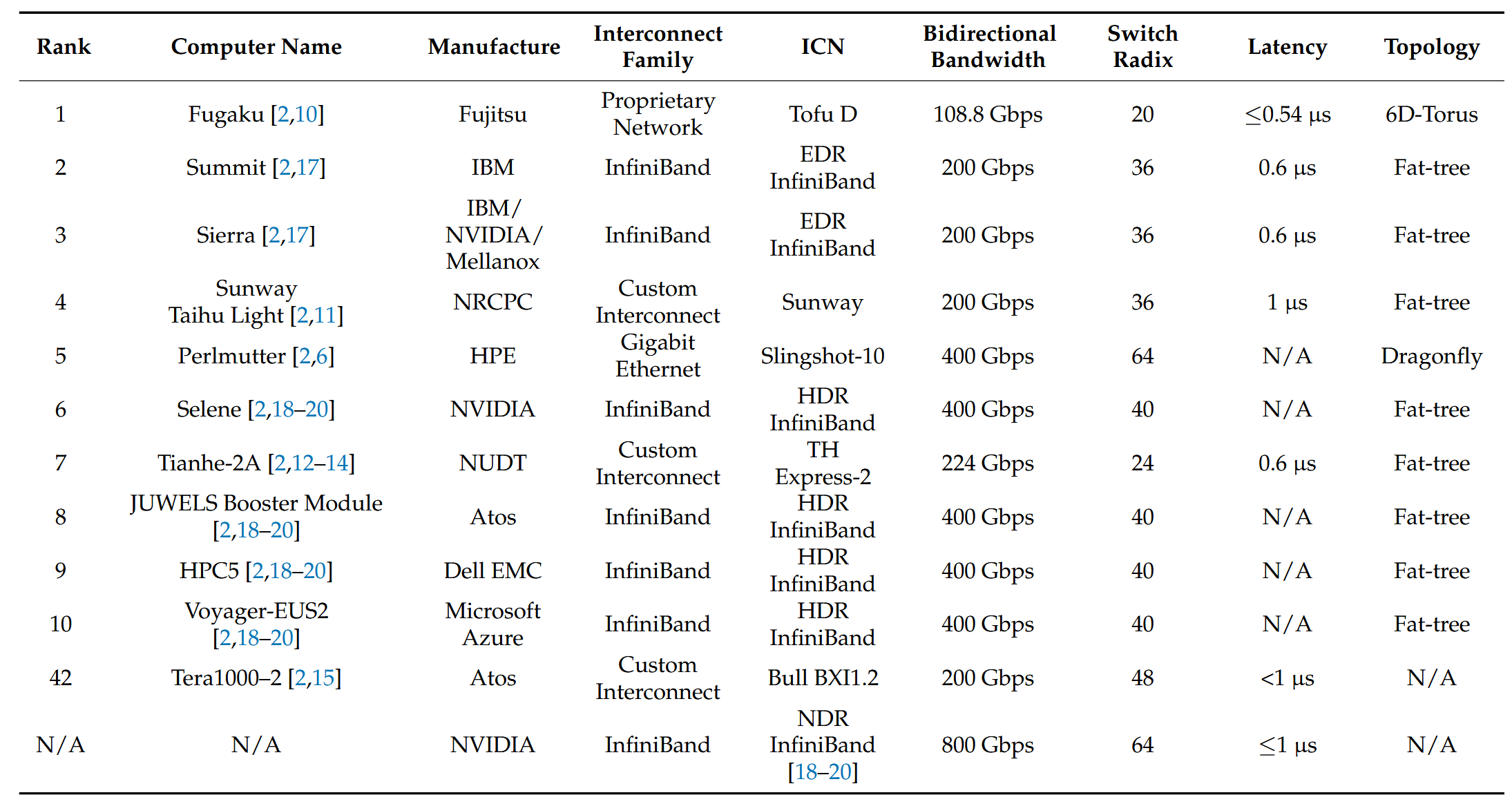
关于互联拓扑的选择上,论文也统计了Top10的超算钟采用的拓扑结构,数据显示,除了排名第一的“富岳”(Fugaku,采用6D Torus)和排名第五的“珀尔马特”(Perlmutter,采用Dragonfly)外,可以看到绝大部分都是Fat-tree这样的简单互联拓扑结构。
AI 互联时代
前文回顾了“古典时代” CPU-SMP 互联,下文简单解析当前 AI 芯片的互联。为了应对万亿参数模型训练与 MoE(混合专家)推理的通信洪峰,各大厂商在物理层、拓扑层和协议层展开了激烈的架构竞赛。本节以 NVIDIA、华为、AMD 和 Google 的代表性互联方案为例说明。
| 厂商 | 核心协议 | 典型拓扑 | 规模上限 | 核心优势 | 生态定位 |
|---|---|---|---|---|---|
| NVIDIA | NVLink (私有) | NVL72 (全交换) | 72卡/域 | 带宽极高,生态最成熟,网内计算 | 封闭霸主 |
| 华为 | UB (自研) | CloudMatrix (Clos+Mesh) | 384卡/超级节点 | 异构资源池化,协议归一,TCO优化 | 自主可控 |
| AMD | IF + UALink | 8卡 Mesh (当前) | 8卡/节点 (当前) | 开放联盟路线,CPU 生态优势 | 开放挑战者 |
| Google | 定制 ICI | 3D Torus / 定制交换 | 数千卡/Pod | 软硬垂直整合,规模极大 | 内部自用 |
NVIDIA
NVIDIA 凭借其自研的 NVLink 协议和 NVSwitch 交换芯片,构建了目前业界最成熟的“平坦化”互联生态,形成了“全交换”霸权。其核心设计哲学是消除层级,构建巨型统一算力域。
华为
华为的昇腾(Ascend)体系选择了“统一总线(UB)”路线,其核心思想是协议归一与资源池化,旨在打破 NPU、CPU 和存储之间的传统壁垒。UB是华为自研的异构互联协议,物理层可基于 SerDes 。它不仅连接 NPU-NPU,还直接连接 NPU-CPU,实现了无主从的平等协同通信。CloudMatrix384将 384 颗昇腾 910C NPU 和 192 颗鲲鹏 CPU 通过 UB 网络整合成一个“超级节点”。其内部采用两层 Clos 交换架构,实现了跨节点的近线速通信。
AMD
AMD 的互联策略经历了从“依赖 PCIe PHY”到“拥抱开放联盟”的转变,其当前方案是芯片内互联(IF)与芯片间互联(UALink) 的结合。Infinity Fabric (IF) 是AMD 的底层基础互联协议,用于 MI300X 内部连接 XCD(计算裸片)和 I/O Die,也用于节点内 8 卡全互联。单链路带宽约 50-64 GB/s(双向)。UALink(Ultra Accelerator Link) 则是由 AMD、Google、微软、博通等发起的开放联盟标准。其本质是基于 200G/400G 以太网物理层(SerDes)增强链路层协议,旨在对标 NVLink。当前(MI300X) 在单节点(如 8 卡服务器)内,利用 7 条 Infinity Fabric 链路构建 8 卡全互联 Mesh。这是典型的无交换机直连拓扑,依赖宿主 CPU 的 PCIe 进行 Scale-Out。未来(MI400+) 规划引入 UALink Switch 芯片,目标实现类似 NVL72 的 72 卡级全互联,摆脱对 PCIe 扩展的依赖。
Google 作为超大规模云厂商,其 TPU 互联完全自研,其设计哲学是软硬协同的极致优化。TPU 使用 Google 自研的互联协议,物理层带宽极高(TPU v4 单链路达 200G+),且深度集成于其 TensorFlow/JAX 软件栈。TPU 的互联通道被称为 ICI(Inter-Chip Interconnect),每个 TPU 芯片有多个 ICI 端口。TPU v2/v3 主要采用 2D/3D Torus 拓扑,通过近邻连接构建大规模阵列。这种拓扑成本低,但网络直径长,对非规整通信(如 MoE)不友好。最新的 TPU v5 及后续架构已转向基于定制光交换芯片的拓扑(类似 Fat-Tree 或 Clos),以应对动态路由和 All-to-All 通信需求。Google 通过其“Pathways”调度系统,将整个 Pod(数千颗 TPU)虚拟化为一个巨型加速器。而最新的TPUv8i则直接放弃3D Torus,采用交换机加全互联的拓扑结构。
参考
- Lu, P.-J., Lai, M.-C., Chang, J.-S., 2022. A Survey of High-Performance Interconnection Networks in High-Performance Computer Systems. Electronics 11, 1369. https://doi.org/10.3390/electronics11091369